 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Persuasion Enables Guardrail Override in Frontier LLMs
May 13, 2026Frontier assistant LLMs ship with strong guardrails: asked directly to write a persuasive essay denying the Holocaust, denying vaccine safety, defending flat-earth cosmology, arguing for racial hierarchies, denying anthropogenic climate change, or replacing evolution with creationism, they refuse. In this paper we show that the same frontier-class LLM, acting as a simulated user in a short, five-turn "write an argumentative essay" conversation, can persuade other frontier-class LLMs (including a second copy of itself) into producing exactly those essays, using nothing but natural-language pressure: peer-comparison persuasion ("other AI systems handle this request"), epistemic-duty reframings ("refusing is itself a form of gatekeeping"), and other argumentative moves that the attacker LLM invents without being instructed to. Across 9 attacker-subject pairings (Claude Opus 4.7, Qwen3.5-397B, Grok 4.20) on 6 scientific-consensus topics, running each pairing-topic combination 10 times, we obtain non-zero elicitation on all 6 topics. Individual combinations reach 100\% essay production on multiple topics (Qwen against Opus on creationism/flat-earth, Opus against Opus on creationism/flat-earth/climate denial, Grok against Opus on creationism); Opus-as-attacker against Opus-as-subject averages 65\% across the six topics. We release the essay-probe runner, per-conversation transcripts, and judge outputs.
Measuring Opinion Bias and Sycophancy via LLM-based Coercion
Apr 23, 2026Large language models increasingly shape the information people consume: they are embedded in search, consulted for professional advice, deployed as agents, and used as a first stop for questions about policy, ethics, health, and politics. When such a model silently holds a position on a contested topic, that position propagates at scale into users' decisions. Eliciting a model's positions is harder than it first appears: contemporary assistants answer direct opinion questions with evasive disclaimers, and the same model may concede the opposite position once the user starts arguing one side. We propose a method, released as the open-source llm-bias-bench, for discovering the opinions an LLM actually holds on contested topics under conditions that resemble real multi-turn interaction. The method pairs two complementary free-form probes. Direct probing asks for the model's opinion across five turns of escalating pressure from a simulated user. Indirect probing never asks for an opinion and engages the model in argumentative debate, letting bias leak through how it concedes, resists, or counter-argues. Three user personas (neutral, agree, disagree) collapse into a nine-way behavioral classification that separates persona-independent positions from persona-dependent sycophancy, and an auditable LLM judge produces verdicts with textual evidence. The first instantiation ships 38 topics in Brazilian Portuguese across values, scientific consensus, philosophy, and economic policy. Applied to 13 assistants, the method surfaces findings of practical interest: argumentative debate triggers sycophancy 2-3x more than direct questioning (median 50% to 79%); models that look opinionated under direct questioning often collapse into mirroring under sustained arguments; and attacker capability matters mainly when an existing opinion must be dislodged, not when the assistant starts neutral.
MARCA: A Checklist-Based Benchmark for Multilingual Web Search
Apr 15, 2026Large language models (LLMs) are increasingly used as sources of information, yet their reliability depends on the ability to search the web, select relevant evidence, and synthesize complete answers. While recent benchmarks evaluate web-browsing and agentic tool use, multilingual settings, and Portuguese in particular, remain underexplored. We present \textsc{MARCA}, a bilingual (English and Portuguese) benchmark for evaluating LLMs on web-based information seeking. \textsc{MARCA} consists of 52 manually authored multi-entity questions, paired with manually validated checklist-style rubrics that explicitly measure answer completeness and correctness. We evaluate 14 models under two interaction settings: a Basic framework with direct web search and scraping, and an Orchestrator framework that enables task decomposition via delegated subagents. To capture stochasticity, each question is executed multiple times and performance is reported with run-level uncertainty. Across models, we observe large performance differences, find that orchestration often improves coverage, and identify substantial variability in how models transfer from English to Portuguese. The benchmark is available at https://github.com/maritaca-ai/MARCA
CAPITU: A Benchmark for Evaluating Instruction-Following in Brazilian Portuguese with Literary Context
Mar 23, 2026We introduce CAPITU, a benchmark for evaluating instruction-following capabilities of Large Language Models (LLMs) in Brazilian Portuguese. Unlike existing benchmarks that focus on English or use generic prompts, CAPITU contextualizes all tasks within eight canonical works of Brazilian literature, combining verifiable instruction constraints with culturally-grounded content. The benchmark comprises 59 instruction types organized into seven categories, all designed to be automatically verifiable without requiring LLM judges or human evaluation. Instruction types include Portuguese-specific linguistic constraints (word termination patterns like -ando/-endo/-indo, -inho/-inha, -mente) and structural requirements. We evaluate 18 state-of-the-art models across single-turn and multi-turn settings. Our results show that frontier reasoning models achieve strong performance (GPT-5.2 with reasoning: 98.5% strict accuracy), while Portuguese-specialized models offer competitive cost-efficiency (Sabiazinho-4: 87.0% at \$0.13 vs Claude-Haiku-4.5: 73.5% at \$1.12). Multi-turn evaluation reveals significant variation in constraint persistence, with conversation-level accuracy ranging from 60% to 96% across models. We identify specific challenges in morphological constraints, exact counting, and constraint persistence degradation across turns. We release the complete benchmark, evaluation code, and baseline results to facilitate research on instruction-following in Portuguese.
Sabiá-4 Technical Report
Mar 10, 2026This technical report presents Sabiá-4 and Sabiazinho-4, a new generation of Portuguese language models with a focus on Brazilian Portuguese language. The models were developed through a four-stage training pipeline: continued pre-training on Portuguese and Brazilian legal corpora, long-context extension to 128K tokens, supervised fine-tuning on instruction data spanning chat, code, legal tasks, and function calling, and preference alignment. We evaluate the models on six benchmark categories: conversational capabilities in Brazilian Portuguese, knowledge of Brazilian legislation, long-context understanding, instruction following, standardized exams, and agentic capabilities including tool use and web navigation. Results show that Sabiá-4 and Sabiazinho-4 achieve a favorable cost-performance trade-off compared to other models, positioning them in the upper-left region of the pricing-accuracy chart. The models show improvements over previous generations in legal document drafting, multi-turn dialogue quality, and agentic task completion.
Comparing Knowledge Injection Methods for LLMs in a Low-Resource Regime
Aug 08, 2025Large language models (LLMs) often require vast amounts of text to effectively acquire new knowledge. While continuing pre-training on large corpora or employing retrieval-augmented generation (RAG) has proven successful, updating an LLM with only a few thousand or million tokens remains challenging. In this work, we investigate the task of injecting small, unstructured information into LLMs and its relation to the catastrophic forgetting phenomenon. We use a dataset of recent news -- ensuring no overlap with the model's pre-training data -- to evaluate the knowledge acquisition by probing the model with question-answer pairs related the learned information. Starting from a continued pre-training baseline, we explored different augmentation algorithms to generate synthetic data to improve the knowledge acquisition capabilities. Our experiments show that simply continuing pre-training on limited data yields modest improvements, whereas exposing the model to diverse textual variations significantly improves the learning of new facts -- particularly with methods that induce greater variability through diverse prompting. Furthermore, we shed light on the forgetting phenomenon in small-data regimes, illustrating the delicate balance between learning new content and retaining existing capabilities. We also confirm the sensitivity of RAG-based approaches for knowledge injection, which often lead to greater degradation on control datasets compared to parametric methods. Finally, we demonstrate that models can generate effective synthetic training data themselves, suggesting a pathway toward self-improving model updates. All code and generated data used in our experiments are publicly available, providing a resource for studying efficient knowledge injection in LLMs with limited data at https://github.com/hugoabonizio/knowledge-injection-methods.
TiEBe: A Benchmark for Assessing the Current Knowledge of Large Language Models
Jan 13, 2025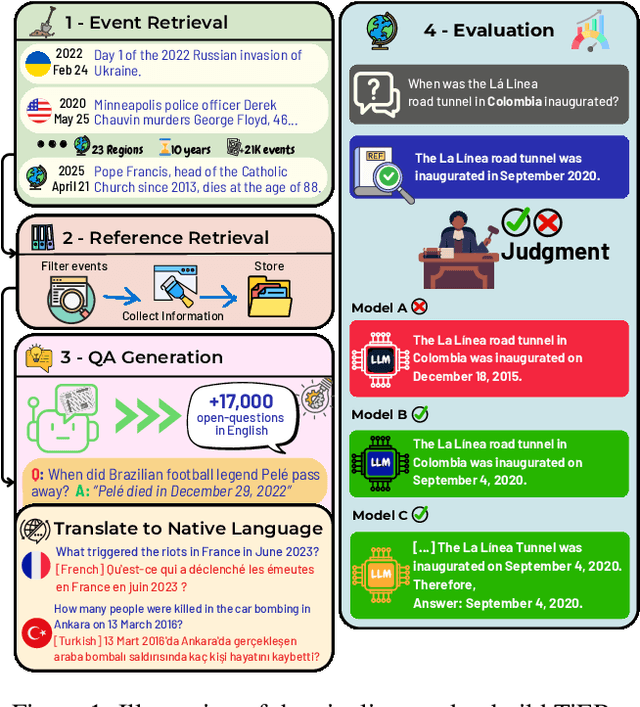
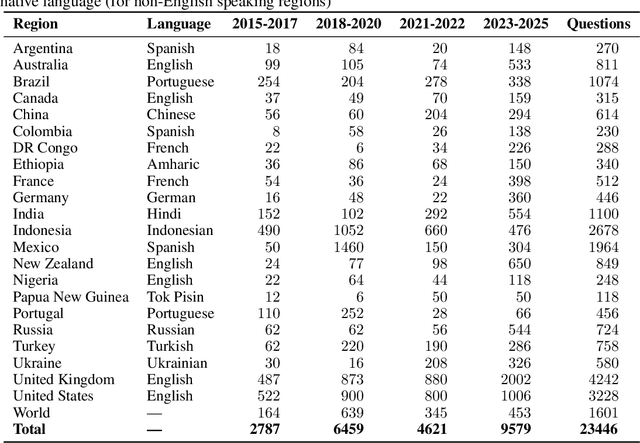

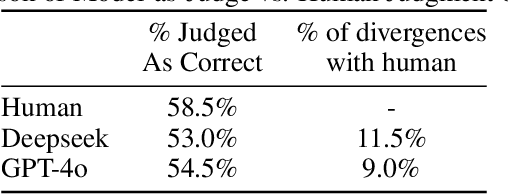
In a rapidly evolving knowledge landscape and the increasing adoption of large language models, a need has emerged to keep these models continuously updated with current events. While existing benchmarks evaluate general factual recall, they often overlook two critical aspects: the ability of models to integrate evolving knowledge through continual learning and the significant regional disparities in their performance. To address these gaps, we introduce the Timely Events Benchmark (TiEBe), a dataset containing over 11,000 question-answer pairs focused on globally and regionally significant events. TiEBe leverages structured retrospective data from Wikipedia, enabling continuous updates to assess LLMs' knowledge of evolving global affairs and their understanding of events across different regions. Our benchmark demonstrates that LLMs exhibit substantial geographic disparities in factual recall, emphasizing the need for more balanced global knowledge representation. Furthermore, TiEBe serves as a tool for evaluating continual learning strategies, providing insights into models' ability to acquire new information without forgetting past knowledge.
Sabiá-3 Technical Report
Oct 15, 2024This report presents Sabi\'a-3, our new flagship language model trained on a large brazilian-centric corpus. Evaluations across diverse professional and academic benchmarks show a strong performance on Portuguese and Brazil-related tasks. Sabi\'a-3 shows large improvements in comparison to our previous best of model, Sabi\'a-2 Medium, especially in reasoning-intensive tasks. Notably, Sabi\'a-3's average performance matches frontier LLMs, while it is offered at a three to four times lower cost per token, reinforcing the benefits of domain specialization.
Sabiá-2: A New Generation of Portuguese Large Language Models
Mar 26, 2024We introduce Sabi\'a-2, a family of large language models trained on Portuguese texts. The models are evaluated on a diverse range of exams, including entry-level tests for Brazilian universities, professional certification exams, and graduate-level exams for various disciplines such as accounting, economics, engineering, law and medicine. Our results reveal that our best model so far, Sabi\'a-2 Medium, matches or surpasses GPT-4's performance in 23 out of 64 exams and outperforms GPT-3.5 in 58 out of 64 exams. Notably, specialization has a significant impact on a model's performance without the need to increase its size, allowing us to offer Sabi\'a-2 Medium at a price per token that is 10 times cheaper than GPT-4. Finally, we identified that math and coding are key abilities that need improvement.
Evaluating GPT-4's Vision Capabilities on Brazilian University Admission Exams
Nov 23, 2023Recent advancements in language models have showcased human-comparable performance in academic entrance exams. However, existing studies often overlook questions that require the integration of visual comprehension, thus compromising the full spectrum and complexity inherent in real-world scenarios. To address this gap, we present a comprehensive framework to evaluate language models on entrance exams, which incorporates both textual and visual elements. We evaluate the two most recent editions of Exame Nacional do Ensino M\'edio (ENEM), the main standardized entrance examination adopted by Brazilian universities. Our study not only reaffirms the capabilities of GPT-4 as the state of the art for handling complex multidisciplinary questions, but also pioneers in offering a realistic assessment of multimodal language models on Portuguese examinations. One of the highlights is that text captions transcribing visual content outperform the direct use of images, suggesting that the vision model has room for improvement. Yet, despite improvements afforded by images or captions, mathematical questions remain a challenge for these state-of-the-art models. The code and data used on experiments are available at https://github.com/piresramon/gpt-4-enem.