 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Defense of Cross-Encoders for Zero-Shot Retrieval
Dec 12, 2022Bi-encoders and cross-encoders are widely used in many state-of-the-art retrieval pipelines. In this work we study the generalization ability of these two types of architectures on a wide range of parameter count on both in-domain and out-of-domain scenarios. We find that the number of parameters and early query-document interactions of cross-encoders play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that cross-encoders largely outperform bi-encoders of similar size in several tasks. In the BEIR benchmark, our largest cross-encoder surpasses a state-of-the-art bi-encoder by more than 4 average points. Finally, we show that using bi-encoders as first-stage retrievers provides no gains in comparison to a simpler retriever such as BM25 on out-of-domain tasks. The code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
A Boring-yet-effective Approach for the Product Ranking Task of the Amazon KDD Cup 2022
Aug 09, 2022
In this work we describe our submission to the product ranking task of the Amazon KDD Cup 2022. We rely on a receipt that showed to be effective in previous competitions: we focus our efforts towards efficiently training and deploying large language odels, such as mT5, while reducing to a minimum the number of task-specific adaptations. Despite the simplicity of our approach, our best model was less than 0.004 nDCG@20 below the top submission. As the top 20 teams achieved an nDCG@20 close to .90, we argue that we need more difficult e-Commerce evaluation datasets to discriminate retrieval methods.
Sequence-to-Sequence Models for Extracting Information from Registration and Legal Documents
Jan 14, 2022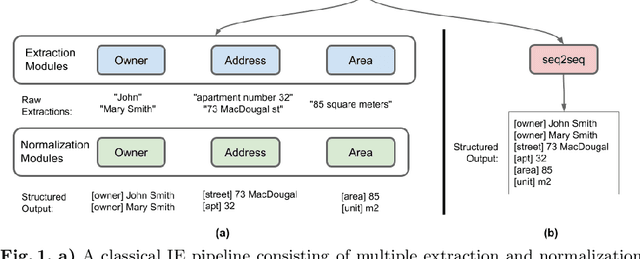



A typical information extraction pipeline consists of token- or span-level classification models coupled with a series of pre- and post-processing scripts. In a production pipeline, requirements often change, with classes being added and removed, which leads to nontrivial modifications to the source code and the possible introduction of bugs. In this work, we evaluate sequence-to-sequence models as an alternative to token-level classification methods for information extraction of legal and registration documents. We finetune models that jointly extract the information and generate the output already in a structured format. Post-processing steps are learned during training, thus eliminating the need for rule-based methods and simplifying the pipeline. Furthermore, we propose a novel method to align the output with the input text, thus facilitating system inspection and auditing. Our experiments on four real-world datasets show that the proposed method is an alternative to classical pipelines.