 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Explanation Methods for NLP Models
Jun 24, 2022



Explanation methods have emerged as an important tool to highlight the features responsible for the predictions of neural networks. There is mounting evidence that many explanation methods are rather unreliable and susceptible to malicious manipulations. In this paper, we particularly aim to understand the robustness of explanation methods in the context of text modality. We provide initial insights and results towards devising a successful adversarial attack against text explanations. To our knowledge, this is the first attempt to evaluate the adversarial robustness of an explanation method. Our experiments show the explanation method can be largely disturbed for up to 86% of the tested samples with small changes in the input sentence and its semantics.
Image Based Fashion Product Recommendation with Deep Learning
Jul 17, 2018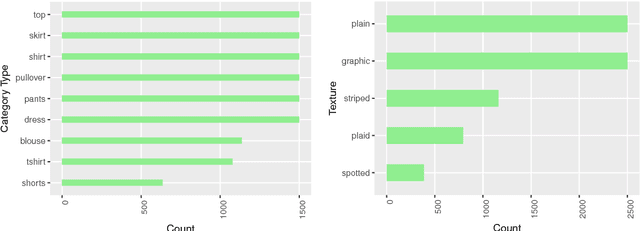
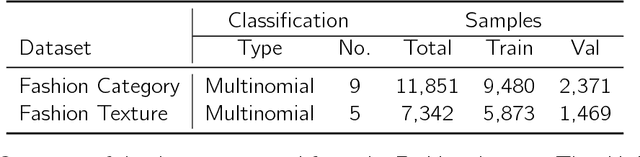
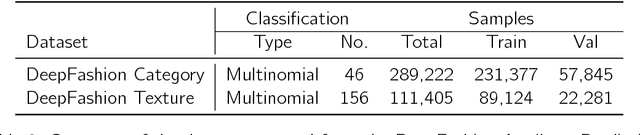

We develop a two-stage deep learning framework that recommends fashion images based on other input images of similar style. For that purpose, a neural network classifier is used as a data-driven, visually-aware feature extractor. The latter then serves as input for similarity-based recommendations using a ranking algorithm. Our approach is tested on the publicly available Fashion dataset. Initialization strategies using transfer learning from larger product databases are presented. Combined with more traditional content-based recommendation systems, our framework can help to increase robustness and performance, for example, by better matching a particular customer style.