 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Named Entity Recognition using Contextualized Token Representations
Jun 23, 2021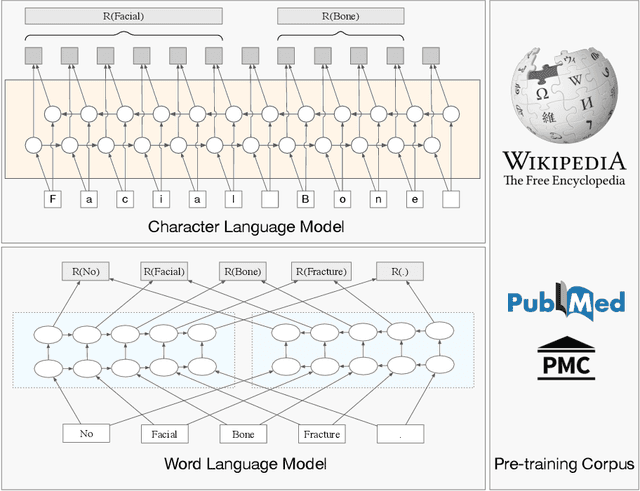

The clinical named entity recognition (CNER) task seeks to locate and classify clinical terminologies into predefined categories, such as diagnostic procedure, disease disorder, severity, medication, medication dosage, and sign symptom. CNER facilitates the study of side-effect on medications including identification of novel phenomena and human-focused information extraction. Existing approaches in extracting the entities of interests focus on using static word embeddings to represent each word. However, one word can have different interpretations that depend on the context of the sentences. Evidently, static word embeddings are insufficient to integrate the diverse interpretation of a word. To overcome this challenge, the technique of contextualized word embedding has been introduced to better capture the semantic meaning of each word based on its context. Two of these language models, ELMo and Flair, have been widely used in the field of Natural Language Processing to generate the contextualized word embeddings on domain-generic documents. However, these embeddings are usually too general to capture the proximity among vocabularies of specific domains. To facilitate various downstream applications using clinical case reports (CCRs), we pre-train two deep contextualized language models, Clinical Embeddings from Language Model (C-ELMo) and Clinical Contextual String Embeddings (C-Flair) using the clinical-related corpus from the PubMed Central. Explicit experiments show that our models gain dramatic improvements compared to both static word embeddings and domain-generic language models.
Bio-JOIE: Joint Representation Learning of Biological Knowledge Bases
Mar 07, 2021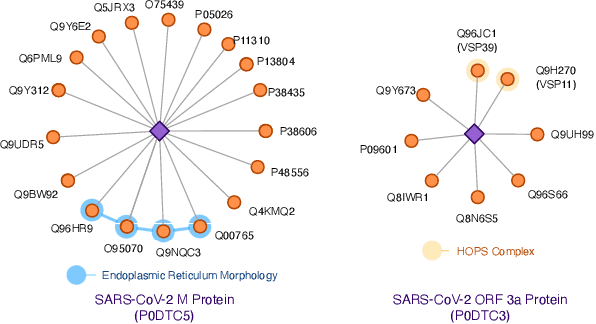
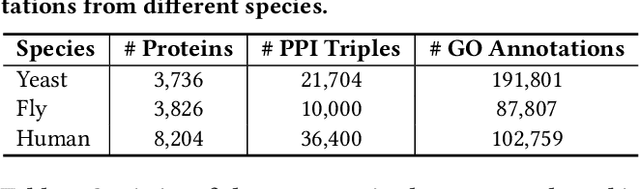
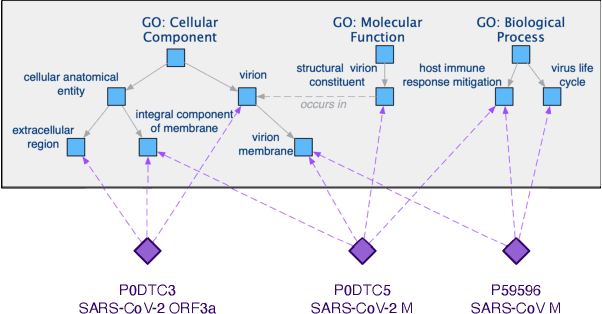
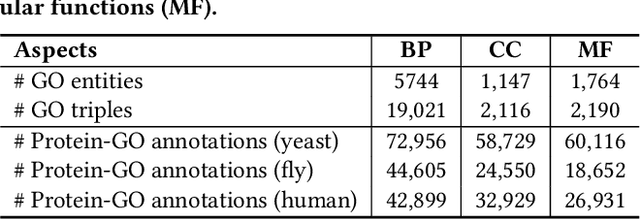
The widespread of Coronavirus has led to a worldwide pandemic with a high mortality rate. Currently, the knowledge accumulated from different studies about this virus is very limited. Leveraging a wide-range of biological knowledge, such as gene ontology and protein-protein interaction (PPI) networks from other closely related species presents a vital approach to infer the molecular impact of a new species. In this paper, we propose the transferred multi-relational embedding model Bio-JOIE to capture the knowledge of gene ontology and PPI networks, which demonstrates superb capability in modeling the SARS-CoV-2-human protein interactions. Bio-JOIE jointly trains two model components. The knowledge model encodes the relational facts from the protein and GO domains into separated embedding spaces, using a hierarchy-aware encoding technique employed for the GO terms. On top of that, the transfer model learns a non-linear transformation to transfer the knowledge of PPIs and gene ontology annotations across their embedding spaces. By leveraging only structured knowledge, Bio-JOIE significantly outperforms existing state-of-the-art methods in PPI type prediction on multiple species. Furthermore, we also demonstrate the potential of leveraging the learned representations on clustering proteins with enzymatic function into enzyme commission families. Finally, we show that Bio-JOIE can accurately identify PPIs between the SARS-CoV-2 proteins and human proteins, providing valuable insights for advancing research on this new disease.
* ACM BCB 2020, Best Student Paper