 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCNear: A Hybrid Architecture for Efficient GCN Training with Near-Memory Processing
Nov 01, 2021


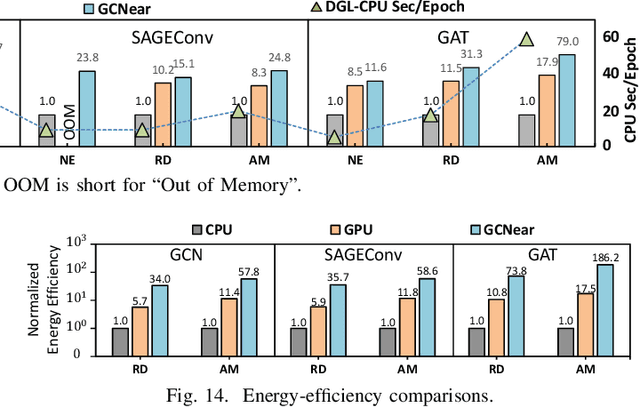
Recently, Graph Convolutional Networks (GCNs) have become state-of-the-art algorithms for analyzing non-euclidean graph data. However, it is challenging to realize efficient GCN training, especially on large graphs. The reasons are many-folded: 1) GCN training incurs a substantial memory footprint. Full-batch training on large graphs even requires hundreds to thousands of gigabytes of memory to buffer the intermediate data for back-propagation. 2) GCN training involves both memory-intensive data reduction and computation-intensive features/gradients update operations. Such a heterogeneous nature challenges current CPU/GPU platforms. 3) The irregularity of graphs and the complex training dataflow jointly increase the difficulty of improving a GCN training system's efficiency. This paper presents GCNear, a hybrid architecture to tackle these challenges. Specifically, GCNear adopts a DIMM-based memory system to provide easy-to-scale memory capacity. To match the heterogeneous nature, we categorize GCN training operations as memory-intensive Reduce and computation-intensive Update operations. We then offload Reduce operations to on-DIMM NMEs, making full use of the high aggregated local bandwidth. We adopt a CAE with sufficient computation capacity to process Update operations. We further propose several optimization strategies to deal with the irregularity of GCN tasks and improve GCNear's performance. We also propose a Multi-GCNear system to evaluate the scalability of GCNear.