 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Structure Guided Transformer for Source Code Summarization
Apr 19, 2021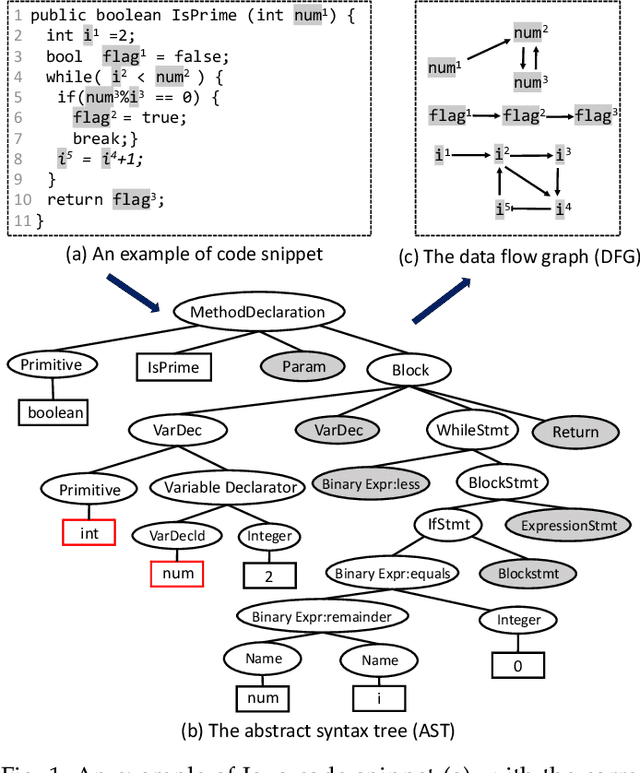
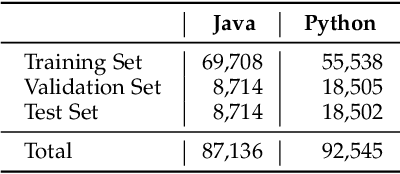
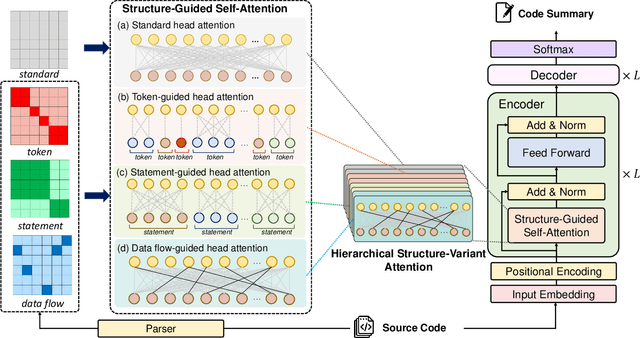
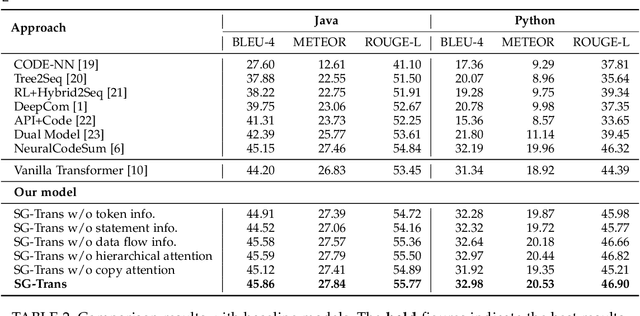
Source code summarization aims at generating concise descriptions of given programs' functionalities. While Transformer-based approaches achieve promising performance, they do not explicitly incorporate the code structure information which is important for capturing code semantics. Besides, without explicit constraints, multi-head attentions in Transformer may suffer from attention collapse, leading to poor code representations for summarization. Effectively integrating the code structure information into Transformer is under-explored in this task domain. In this paper, we propose a novel approach named SG-Trans to incorporate code structural properties into Transformer. Specifically, to capture the hierarchical characteristics of code, we inject the local symbolic information (e.g., code tokens) and global syntactic structure (e.g., data flow) into the self-attention module as inductive bias. Extensive evaluation shows the superior performance of SG-Trans over the state-of-the-art approaches.
Emerging App Issue Identification via Online Joint Sentiment-Topic Tracing
Aug 23, 2020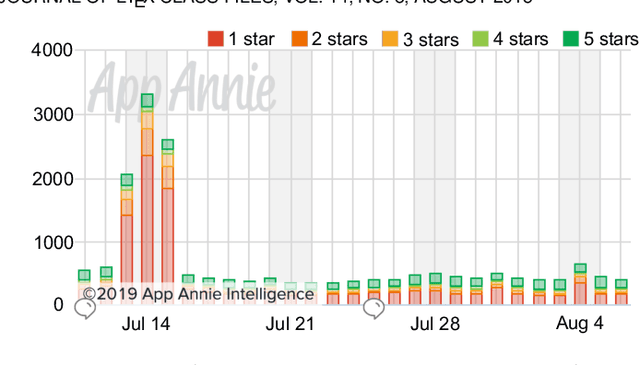
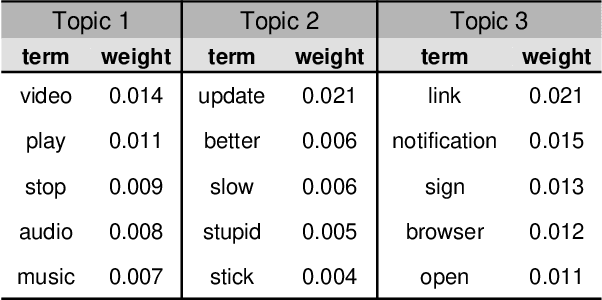
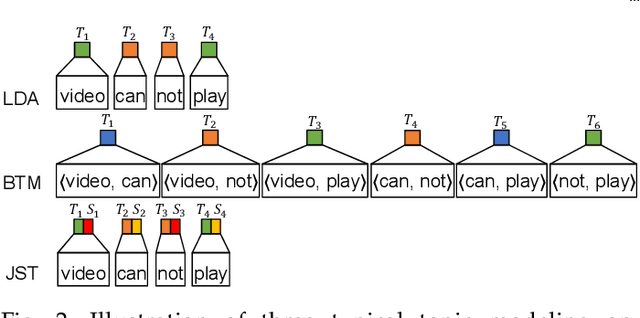
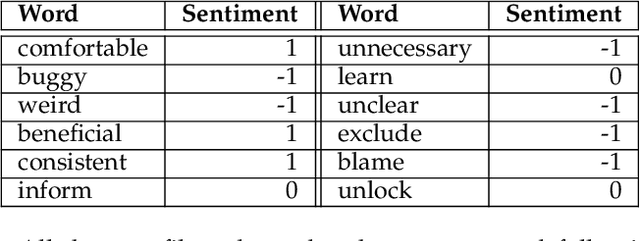
Millions of mobile apps are available in app stores, such as Apple's App Store and Google Play. For a mobile app, it would be increasingly challenging to stand out from the enormous competitors and become prevalent among users. Good user experience and well-designed functionalities are the keys to a successful app. To achieve this, popular apps usually schedule their updates frequently. If we can capture the critical app issues faced by users in a timely and accurate manner, developers can make timely updates, and good user experience can be ensured. There exist prior studies on analyzing reviews for detecting emerging app issues. These studies are usually based on topic modeling or clustering techniques. However, the short-length characteristics and sentiment of user reviews have not been considered. In this paper, we propose a novel emerging issue detection approach named MERIT to take into consideration the two aforementioned characteristics. Specifically, we propose an Adaptive Online Biterm Sentiment-Topic (AOBST) model for jointly modeling topics and corresponding sentiments that takes into consideration app versions. Based on the AOBST model, we infer the topics negatively reflected in user reviews for one app version, and automatically interpret the meaning of the topics with most relevant phrases and sentences. Experiments on popular apps from Google Play and Apple's App Store demonstrate the effectiveness of MERIT in identifying emerging app issues, improving the state-of-the-art method by 22.3% in terms of F1-score. In terms of efficiency, MERIT can return results within acceptable time.
Photon: A Robust Cross-Domain Text-to-SQL System
Aug 03, 2020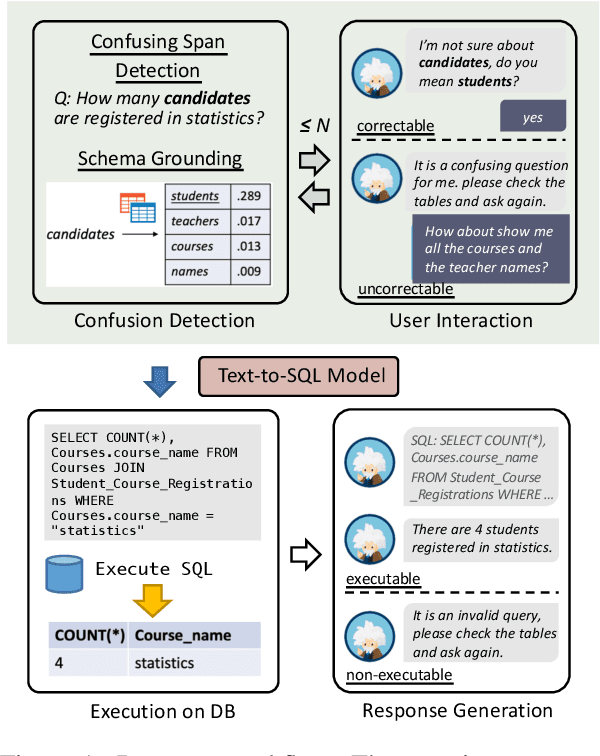
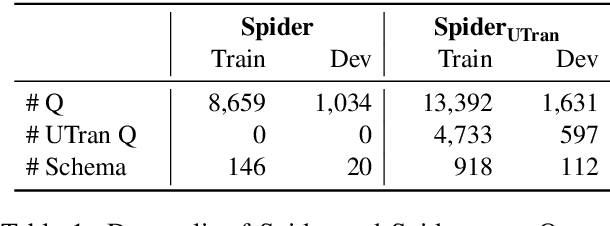
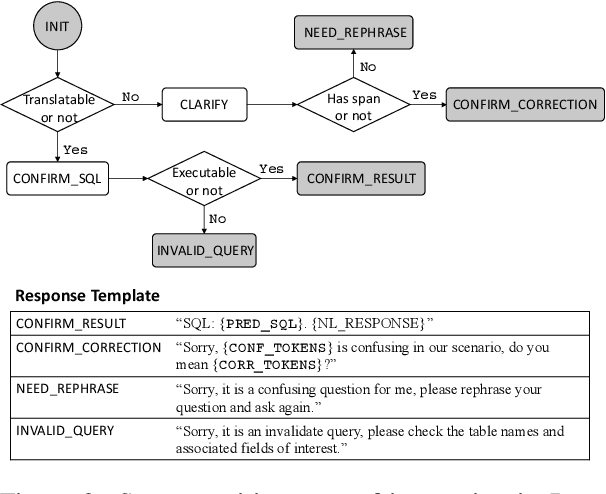
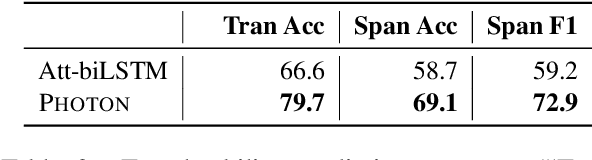
Natural language interfaces to databases (NLIDB) democratize end user access to relational data. Due to fundamental differences between natural language communication and programming, it is common for end users to issue questions that are ambiguous to the system or fall outside the semantic scope of its underlying query language. We present Photon, a robust, modular, cross-domain NLIDB that can flag natural language input to which a SQL mapping cannot be immediately determined. Photon consists of a strong neural semantic parser (63.2\% structure accuracy on the Spider dev benchmark), a human-in-the-loop question corrector, a SQL executor and a response generator. The question corrector is a discriminative neural sequence editor which detects confusion span(s) in the input question and suggests rephrasing until a translatable input is given by the user or a maximum number of iterations are conducted. Experiments on simulated data show that the proposed method effectively improves the robustness of text-to-SQL system against untranslatable user input. The live demo of our system is available at http://naturalsql.com.
Automating App Review Response Generation
Feb 10, 2020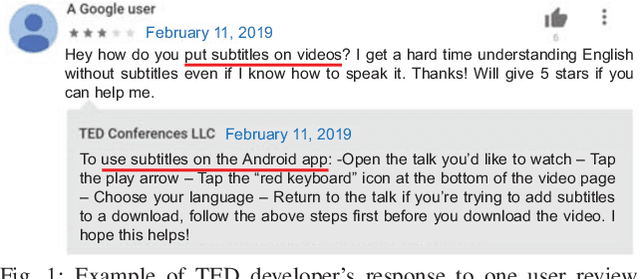
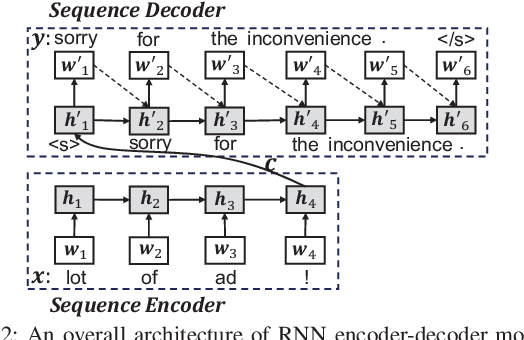
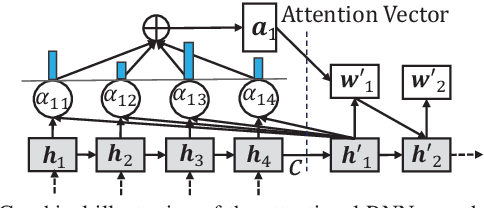
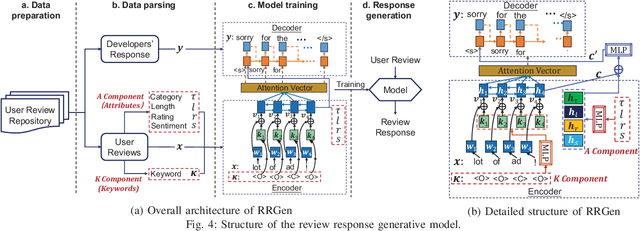
Previous studies showed that replying to a user review usually has a positive effect on the rating that is given by the user to the app. For example, Hassan et al. found that responding to a review increases the chances of a user updating their given rating by up to six times compared to not responding. To alleviate the labor burden in replying to the bulk of user reviews, developers usually adopt a template-based strategy where the templates can express appreciation for using the app or mention the company email address for users to follow up. However, reading a large number of user reviews every day is not an easy task for developers. Thus, there is a need for more automation to help developers respond to user reviews. Addressing the aforementioned need, in this work we propose a novel approach RRGen that automatically generates review responses by learning knowledge relations between reviews and their responses. RRGen explicitly incorporates review attributes, such as user rating and review length, and learns the relations between reviews and corresponding responses in a supervised way from the available training data. Experiments on 58 apps and 309,246 review-response pairs highlight that RRGen outperforms the baselines by at least 67.4% in terms of BLEU-4 (an accuracy measure that is widely used to evaluate dialogue response generation systems). Qualitative analysis also confirms the effectiveness of RRGen in generating relevant and accurate responses.
What Changed Your Mind: The Roles of Dynamic Topics and Discourse in Argumentation Process
Feb 10, 2020

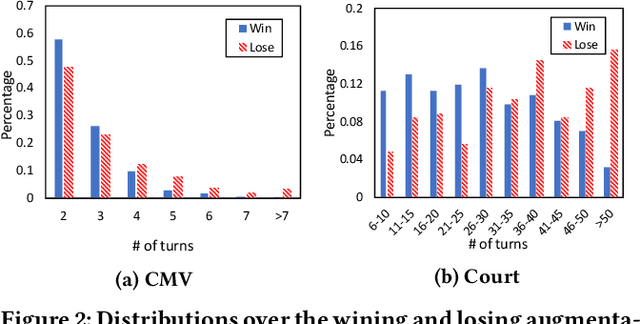
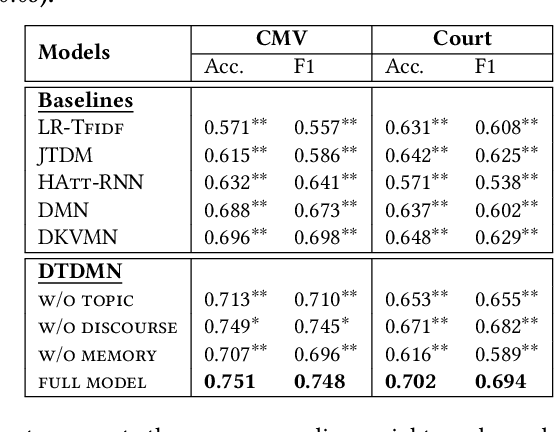
In our world with full of uncertainty, debates and argumentation contribute to the progress of science and society. Despite of the increasing attention to characterize human arguments, most progress made so far focus on the debate outcome, largely ignoring the dynamic patterns in argumentation processes. This paper presents a study that automatically analyzes the key factors in argument persuasiveness, beyond simply predicting who will persuade whom. Specifically, we propose a novel neural model that is able to dynamically track the changes of latent topics and discourse in argumentative conversations, allowing the investigation of their roles in influencing the outcomes of persuasion. Extensive experiments have been conducted on argumentative conversations on both social media and supreme court. The results show that our model outperforms state-of-the-art models in identifying persuasive arguments via explicitly exploring dynamic factors of topic and discourse. We further analyze the effects of topics and discourse on persuasiveness, and find that they are both useful - topics provide concrete evidence while superior discourse styles may bias participants, especially in social media arguments. In addition, we draw some findings from our empirical results, which will help people better engage in future persuasive conversations.
What You Say and How You Say it: Joint Modeling of Topics and Discourse in Microblog Conversations
Mar 18, 2019This paper presents an unsupervised framework for jointly modeling topic content and discourse behavior in microblog conversations. Concretely, we propose a neural model to discover word clusters indicating what a conversation concerns (i.e., topics) and those reflecting how participants voice their opinions (i.e., discourse). Extensive experiments show that our model can yield both coherent topics and meaningful discourse behavior. Further study shows that our topic and discourse representations can benefit the classification of microblog messages, especially when they are jointly trained with the classifier.
Topic Memory Networks for Short Text Classification
Sep 11, 2018


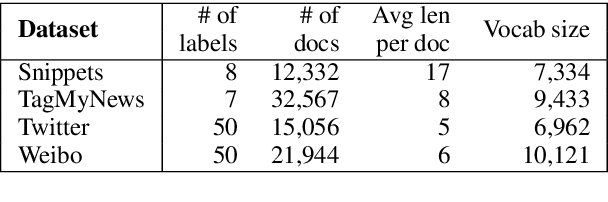
Many classification models work poorly on short texts due to data sparsity. To address this issue, we propose topic memory networks for short text classification with a novel topic memory mechanism to encode latent topic representations indicative of class labels. Different from most prior work that focuses on extending features with external knowledge or pre-trained topics, our model jointly explores topic inference and text classification with memory networks in an end-to-end manner. Experimental results on four benchmark datasets show that our model outperforms state-of-the-art models on short text classification, meanwhile generates coherent topics.