 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIL: Search-Augmented Instruction Learning
Paper and Code



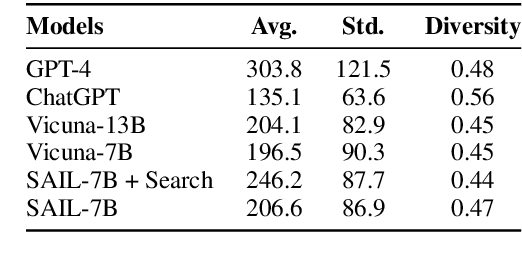
Large language models (LLMs) have been significantly improved by instruction fine-tuning, but still lack transparency and the ability to utilize up-to-date knowledge and information. In this work, we propose search-augmented instruction learning (SAIL), which grounds the language generation and instruction following abilities on complex search results generated by in-house and external search engines. With an instruction tuning corpus, we collect search results for each training case from different search APIs and domains, and construct a new search-grounded training set containing \textit{(instruction, grounding information, response)} triplets. We then fine-tune the LLaMA-7B model on the constructed training set. Since the collected results contain unrelated and disputing languages, the model needs to learn to ground on trustworthy search results, filter out distracting passages, and generate the target response. The search result-denoising process entails explicit trustworthy information selection and multi-hop reasoning, since the retrieved passages might be informative but not contain the instruction-following answer. Experiments show that the fine-tuned SAIL-7B model has a strong instruction-following ability, and it performs significantly better on transparency-sensitive tasks, including open-ended question answering and fact checking.