 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting TED Talk Ratings from Language and Prosody
May 21, 2019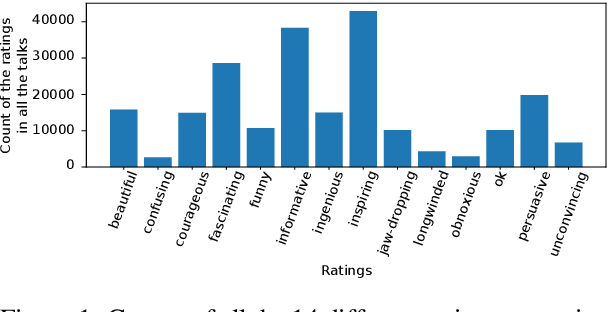
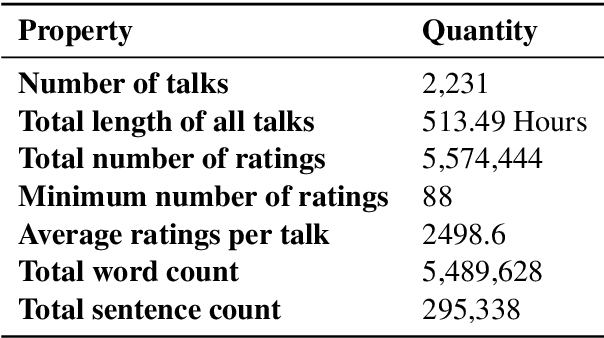
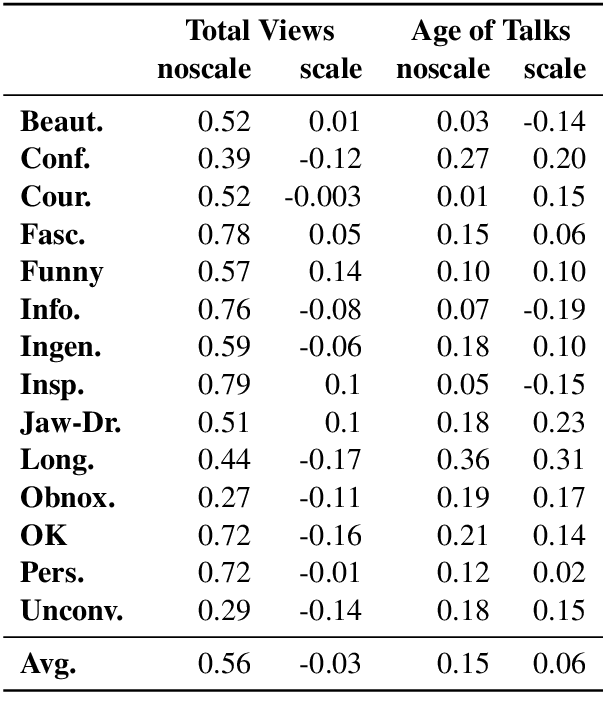
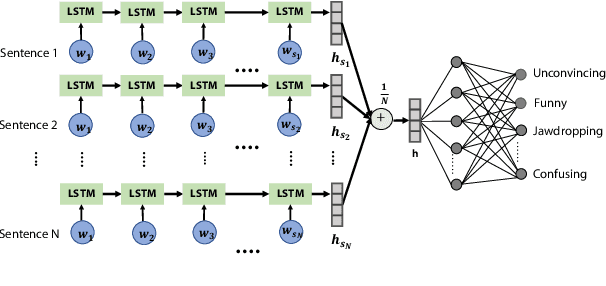
We use the largest open repository of public speaking---TED Talks---to predict the ratings of the online viewers. Our dataset contains over 2200 TED Talk transcripts (includes over 200 thousand sentences), audio features and the associated meta information including about 5.5 Million ratings from spontaneous visitors of the website. We propose three neural network architectures and compare with statistical machine learning. Our experiments reveal that it is possible to predict all the 14 different ratings with an average AUC of 0.83 using the transcripts and prosody features only. The dataset and the complete source code is available for further analysis.
A Causality-Guided Prediction of the TED Talk Ratings from the Speech-Transcripts using Neural Networks
May 21, 2019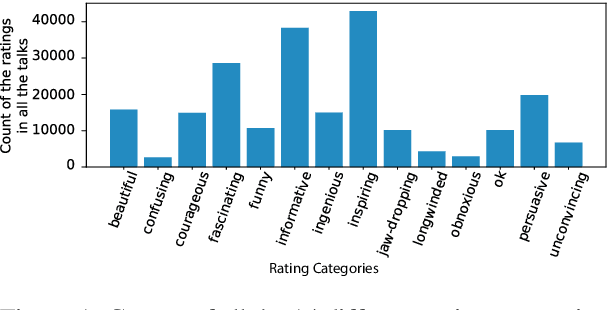
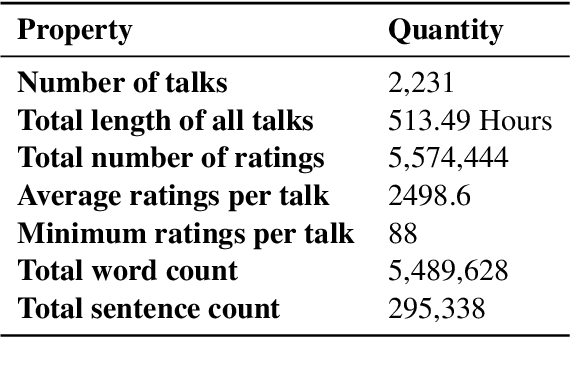
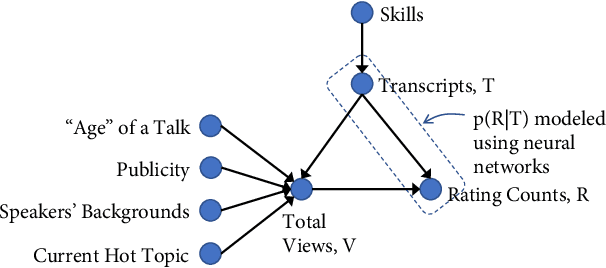
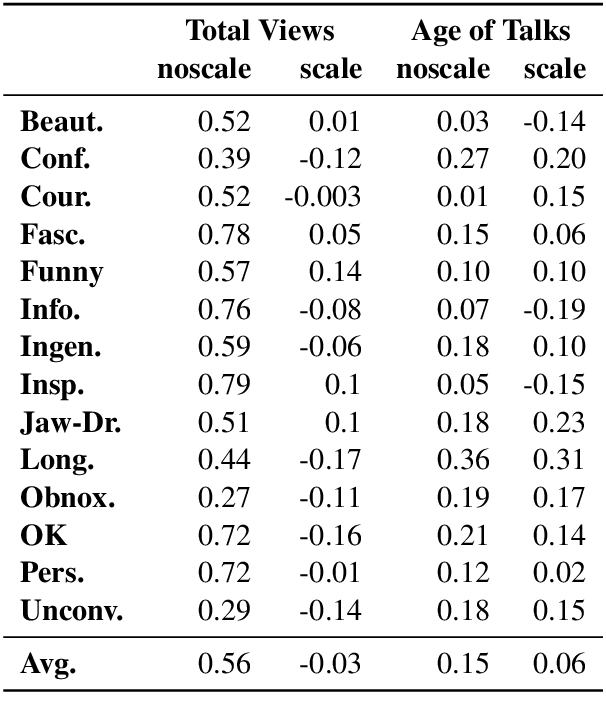
Automated prediction of public speaking performance enables novel systems for tutoring public speaking skills. We use the largest open repository---TED Talks---to predict the ratings provided by the online viewers. The dataset contains over 2200 talk transcripts and the associated meta information including over 5.5 million ratings from spontaneous visitors to the website. We carefully removed the bias present in the dataset (e.g., the speakers' reputations, popularity gained by publicity, etc.) by modeling the data generating process using a causal diagram. We use a word sequence based recurrent architecture and a dependency tree based recursive architecture as the neural networks for predicting the TED talk ratings. Our neural network models can predict the ratings with an average F-score of 0.77 which largely outperforms the competitive baseline method.