 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Machine Translation to Localize Task Oriented NLG Output
Jul 09, 2021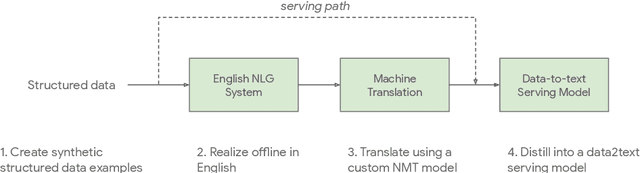
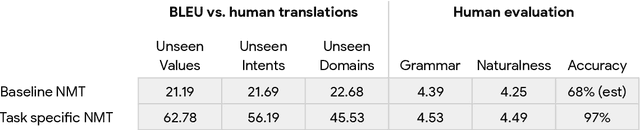
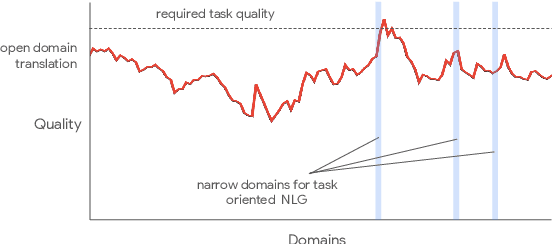
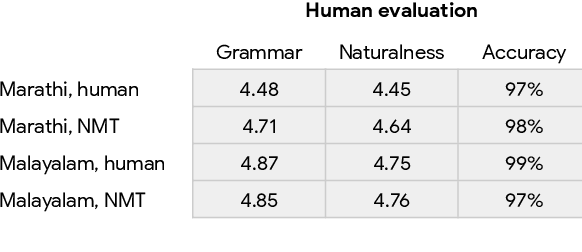
One of the challenges in a task oriented natural language application like the Google Assistant, Siri, or Alexa is to localize the output to many languages. This paper explores doing this by applying machine translation to the English output. Using machine translation is very scalable, as it can work with any English output and can handle dynamic text, but otherwise the problem is a poor fit. The required quality bar is close to perfection, the range of sentences is extremely narrow, and the sentences are often very different than the ones in the machine translation training data. This combination of requirements is novel in the field of domain adaptation for machine translation. We are able to reach the required quality bar by building on existing ideas and adding new ones: finetuning on in-domain translations, adding sentences from the Web, adding semantic annotations, and using automatic error detection. The paper shares our approach and results, together with a distillation model to serve the translation models at scale.