 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovingFashion: a Benchmark for the Video-to-Shop Challenge
Oct 14, 2021
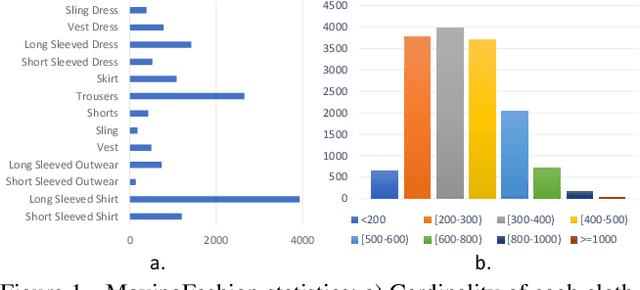

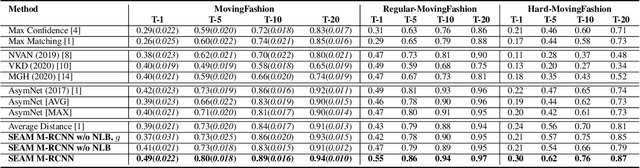
Retrieving clothes which are worn in social media videos (Instagram, TikTok) is the latest frontier of e-fashion, referred to as "video-to-shop" in the computer vision literature. In this paper we present MovingFashion, the first publicly available dataset to cope with this challenge. MovingFashion is composed of 14855 social videos, each one of them associated to e-commerce "shop" images where the corresponding clothing items are clearly portrayed. In addition, we present a network for retrieving the shop images in this scenario, dubbed SEAM Match-RCNN. The model is trained by image-to-video domain adaptation, allowing to use video sequences where only their association with a shop image is given, eliminating the need of millions of annotated bounding boxes. SEAM Match-RCNN builds an embedding, where an attention-based weighted sum of few frames (10) of a social video is enough to individuate the correct product within the first 5 retrieved items in a 14K+ shop element gallery with an accuracy of 80%. This provides the best performance on MovingFashion, comparing exhaustively against the related state-of-the-art approaches and alternative baselines.
Texture Retrieval in the Wild through detection-based attributes
Oct 04, 2019



Capturing the essence of a textile image in a robust way is important to retrieve it in a large repository, especially if it has been acquired in the wild (by taking a photo of the textile of interest). In this paper we show that a texel-based representation fits well with this task. In particular, we refer to Texel-Att, a recent texel-based descriptor which has shown to capture fine grained variations of a texture, for retrieval purposes. After a brief explanation of Texel-Att, we will show in our experiments that this descriptor is robust to distortions resulting from acquisitions in the wild by setting up an experiment in which textures from the ElBa (an Element-Based texture dataset) are artificially distorted and then used to retrieve the original image. We compare our approach with existing descriptors using a simple ranking framework based on distance functions. Results show that even under extreme conditions (such as a down-sampling with a factor of 10), we perform better than alternative approaches.
Texel-Att: Representing and Classifying Element-based Textures by Attributes
Aug 30, 2019


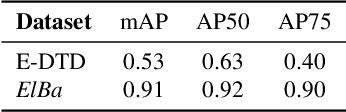
Element-based textures are a kind of texture formed by nameable elements, the texels [1], distributed according to specific statistical distributions; it is of primary importance in many sectors, namely textile, fashion and interior design industry. State-of-theart texture descriptors fail to properly characterize element-based texture, so we present Texel-Att to fill this gap. Texel-Att is the first fine-grained, attribute-based representation and classification framework for element-based textures. It first individuates texels, characterizing them with individual attributes; subsequently, texels are grouped and characterized through layout attributes, which give the Texel-Att representation. Texels are detected by a Mask-RCNN, trained on a brand-new element-based texture dataset, ElBa, containing 30K texture images with 3M fully-annotated texels. Examples of individual and layout attributes are exhibited to give a glimpse on the level of achievable graininess. In the experiments, we present detection results to show that texels can be precisely individuated, even on textures "in the wild"; to this sake, we individuate the element-based classes of the Describable Texture Dataset (DTD), where almost 900K texels have been manually annotated, leading to the Element-based DTD (E-DTD). Subsequently, classification and ranking results demonstrate the expressivity of Texel-Att on ElBa and E-DTD, overcoming the alternative features and relative attributes, doubling the best performance in some cases; finally, we report interactive search results on ElBa and E-DTD: with Texel-Att on the E-DTD dataset we are able to individuate within 10 iterations the desired texture in the 90% of cases, against the 71% obtained with a combination of the finest existing attributes so far. Dataset and code is available at https://github.com/godimarcovr/Texel-Att
SIMCO: SIMilarity-based object COunting
Apr 15, 2019
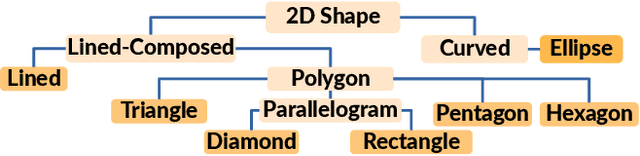
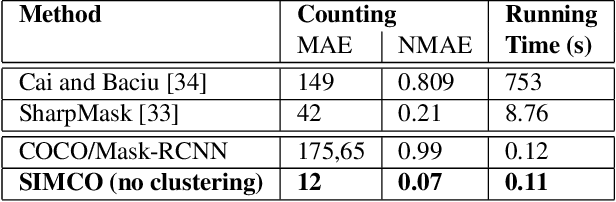
We present SIMCO, the first agnostic multi-class object counting approach. SIMCO starts by detecting foreground objects through a novel Mask RCNN-based architecture trained beforehand (just once) on a brand-new synthetic 2D shape dataset, InShape; the idea is to highlight every object resembling a primitive 2D shape (circle, square, rectangle, etc.). Each object detected is described by a low-dimensional embedding, obtained from a novel similarity-based head branch; this latter implements a triplet loss, encouraging similar objects (same 2D shape + color and scale) to map close. Subsequently, SIMCO uses this embedding for clustering, so that different types of objects can emerge and be counted, making SIMCO the very first multi-class unsupervised counter. Experiments show that SIMCO provides state-of-the-art scores on counting benchmarks and that it can also help in many challenging image understanding tasks.
Understanding Deep Architectures by Visual Summaries
Jul 18, 2018
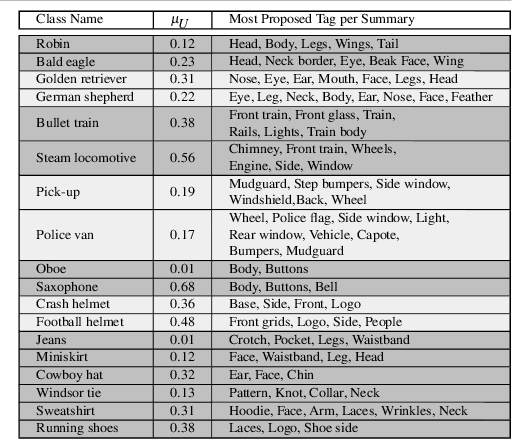


In deep learning, visualization techniques extract the salient patterns exploited by deep networks for image classification, focusing on single images; no effort has been spent in investigating whether these patterns are systematically related to precise semantic entities over multiple images belonging to a same class, thus failing to capture the very understanding of the image class the network has realized. This paper goes in this direction, presenting a visualization framework which produces a group of clusters or summaries, each one formed by crisp salient image regions focusing on a particular part that the network has exploited with high regularity to decide for a given class. The approach is based on a sparse optimization step providing sharp image saliency masks that are clustered together by means of a semantic flow similarity measure. The summaries communicate clearly what a network has exploited of a particular image class, and this is proved through automatic image tagging and with a user study. Beyond the deep network understanding, summaries are also useful for many quantitative reasons: their number is correlated with ability of a network to classify (more summaries, better performances), and they can be used to improve the classification accuracy of a network through summary-driven specializations.
Indirect Match Highlights Detection with Deep Convolutional Neural Networks
Oct 02, 2017


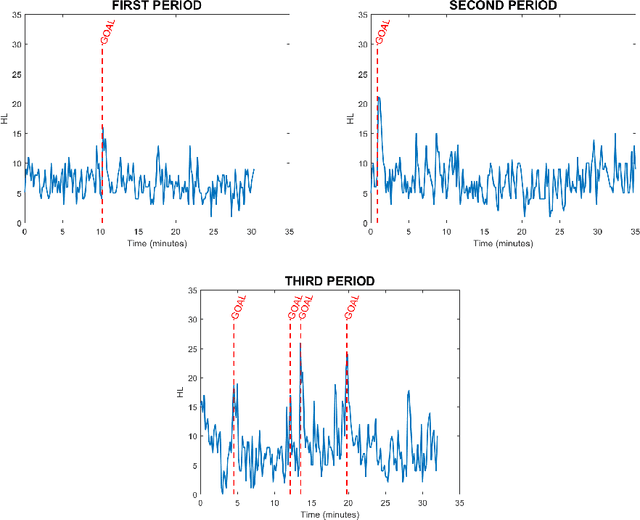
Highlights in a sport video are usually referred as actions that stimulate excitement or attract attention of the audience. A big effort is spent in designing techniques which find automatically highlights, in order to automatize the otherwise manual editing process. Most of the state-of-the-art approaches try to solve the problem by training a classifier using the information extracted on the tv-like framing of players playing on the game pitch, learning to detect game actions which are labeled by human observers according to their perception of highlight. Obviously, this is a long and expensive work. In this paper, we reverse the paradigm: instead of looking at the gameplay, inferring what could be exciting for the audience, we directly analyze the audience behavior, which we assume is triggered by events happening during the game. We apply deep 3D Convolutional Neural Network (3D-CNN) to extract visual features from cropped video recordings of the supporters that are attending the event. Outputs of the crops belonging to the same frame are then accumulated to produce a value indicating the Highlight Likelihood (HL) which is then used to discriminate between positive (i.e. when a highlight occurs) and negative samples (i.e. standard play or time-outs). Experimental results on a public dataset of ice-hockey matches demonstrate the effectiveness of our method and promote further research in this new exciting direction.