 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovingFashion: a Benchmark for the Video-to-Shop Challenge
Paper and Code

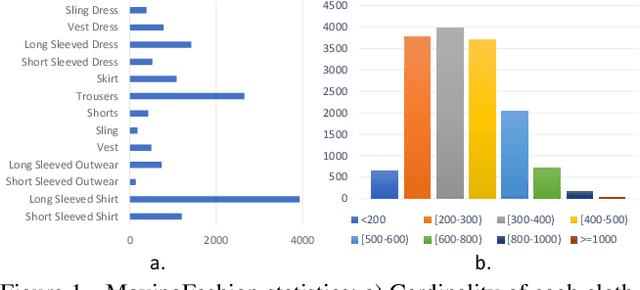

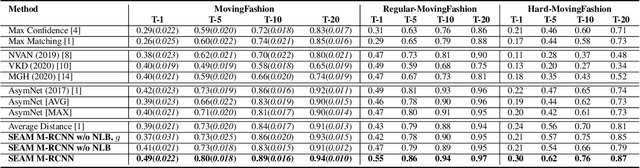
Retrieving clothes which are worn in social media videos (Instagram, TikTok) is the latest frontier of e-fashion, referred to as "video-to-shop" in the computer vision literature. In this paper we present MovingFashion, the first publicly available dataset to cope with this challenge. MovingFashion is composed of 14855 social videos, each one of them associated to e-commerce "shop" images where the corresponding clothing items are clearly portrayed. In addition, we present a network for retrieving the shop images in this scenario, dubbed SEAM Match-RCNN. The model is trained by image-to-video domain adaptation, allowing to use video sequences where only their association with a shop image is given, eliminating the need of millions of annotated bounding boxes. SEAM Match-RCNN builds an embedding, where an attention-based weighted sum of few frames (10) of a social video is enough to individuate the correct product within the first 5 retrieved items in a 14K+ shop element gallery with an accuracy of 80%. This provides the best performance on MovingFashion, comparing exhaustively against the related state-of-the-art approaches and alternative baselines.