 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the use of learning-based forecasting methods for ameliorating fashion business processes: A position paper
Nov 09, 2022The fashion industry is one of the most active and competitive markets in the world, manufacturing millions of products and reaching large audiences every year. A plethora of business processes are involved in this large-scale industry, but due to the generally short life-cycle of clothing items, supply-chain management and retailing strategies are crucial for good market performance. Correctly understanding the wants and needs of clients, managing logistic issues and marketing the correct products are high-level problems with a lot of uncertainty associated to them given the number of influencing factors, but most importantly due to the unpredictability often associated with the future. It is therefore straightforward that forecasting methods, which generate predictions of the future, are indispensable in order to ameliorate all the various business processes that deal with the true purpose and meaning of fashion: having a lot of people wear a particular product or style, rendering these items, people and consequently brands fashionable. In this paper, we provide an overview of three concrete forecasting tasks that any fashion company can apply in order to improve their industrial and market impact. We underline advances and issues in all three tasks and argue about their importance and the impact they can have at an industrial level. Finally, we highlight issues and directions of future work, reflecting on how learning-based forecasting methods can further aid the fashion industry.
POP: Mining POtential Performance of new fashion products via webly cross-modal query expansion
Jul 22, 2022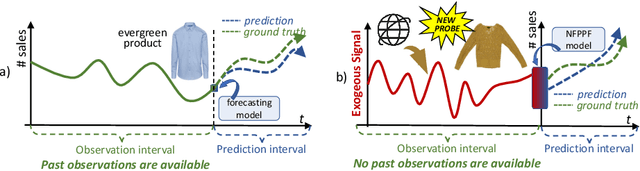


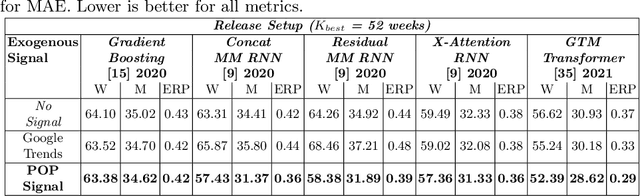
We propose a data-centric pipeline able to generate exogenous observation data for the New Fashion Product Performance Forecasting (NFPPF) problem, i.e., predicting the performance of a brand-new clothing probe with no available past observations. Our pipeline manufactures the missing past starting from a single, available image of the clothing probe. It starts by expanding textual tags associated with the image, querying related fashionable or unfashionable images uploaded on the web at a specific time in the past. A binary classifier is robustly trained on these web images by confident learning, to learn what was fashionable in the past and how much the probe image conforms to this notion of fashionability. This compliance produces the POtential Performance (POP) time series, indicating how performing the probe could have been if it were available earlier. POP proves to be highly predictive for the probe's future performance, ameliorating the sales forecasts of all state-of-the-art models on the recent VISUELLE fast-fashion dataset. We also show that POP reflects the ground-truth popularity of new styles (ensembles of clothing items) on the Fashion Forward benchmark, demonstrating that our webly-learned signal is a truthful expression of popularity, accessible by everyone and generalizable to any time of analysis. Forecasting code, data and the POP time series are available at: https://github.com/HumaticsLAB/POP-Mining-POtential-Performance
The multi-modal universe of fast-fashion: the Visuelle 2.0 benchmark
Apr 14, 2022
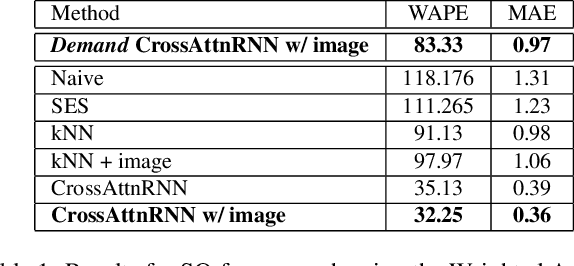
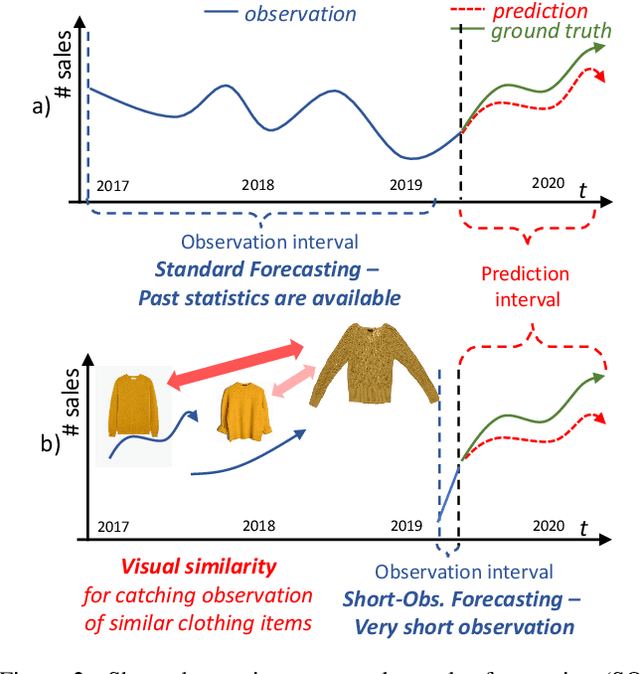
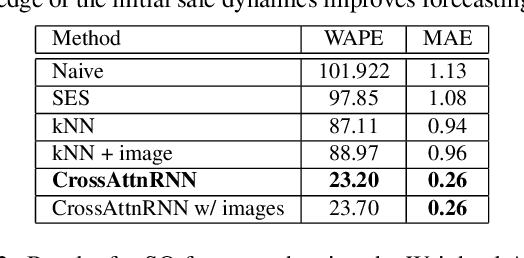
We present Visuelle 2.0, the first dataset useful for facing diverse prediction problems that a fast-fashion company has to manage routinely. Furthermore, we demonstrate how the use of computer vision is substantial in this scenario. Visuelle 2.0 contains data for 6 seasons / 5355 clothing products of Nuna Lie, a famous Italian company with hundreds of shops located in different areas within the country. In particular, we focus on a specific prediction problem, namely short-observation new product sale forecasting (SO-fore). SO-fore assumes that the season has started and a set of new products is on the shelves of the different stores. The goal is to forecast the sales for a particular horizon, given a short, available past (few weeks), since no earlier statistics are available. To be successful, SO-fore approaches should capture this short past and exploit other modalities or exogenous data. To these aims, Visuelle 2.0 is equipped with disaggregated data at the item-shop level and multi-modal information for each clothing item, allowing computer vision approaches to come into play. The main message that we deliver is that the use of image data with deep networks boosts performances obtained when using the time series in long-term forecasting scenarios, ameliorating the WAPE by 8.2% and the MAE by 7.7%. The dataset is available at: https://humaticslab.github.io/forecasting/visuelle.
MovingFashion: a Benchmark for the Video-to-Shop Challenge
Oct 14, 2021
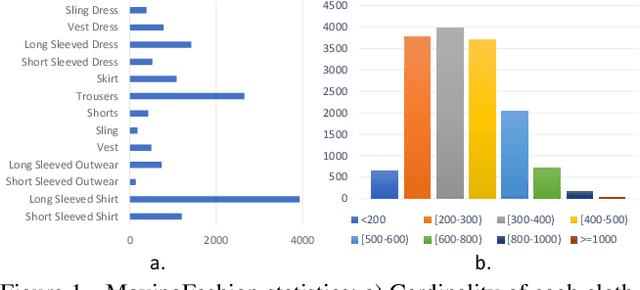

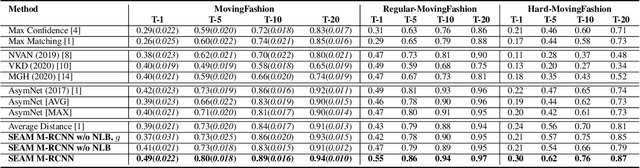
Retrieving clothes which are worn in social media videos (Instagram, TikTok) is the latest frontier of e-fashion, referred to as "video-to-shop" in the computer vision literature. In this paper we present MovingFashion, the first publicly available dataset to cope with this challenge. MovingFashion is composed of 14855 social videos, each one of them associated to e-commerce "shop" images where the corresponding clothing items are clearly portrayed. In addition, we present a network for retrieving the shop images in this scenario, dubbed SEAM Match-RCNN. The model is trained by image-to-video domain adaptation, allowing to use video sequences where only their association with a shop image is given, eliminating the need of millions of annotated bounding boxes. SEAM Match-RCNN builds an embedding, where an attention-based weighted sum of few frames (10) of a social video is enough to individuate the correct product within the first 5 retrieved items in a 14K+ shop element gallery with an accuracy of 80%. This provides the best performance on MovingFashion, comparing exhaustively against the related state-of-the-art approaches and alternative baselines.
Well Googled is Half Done: Multimodal Forecasting of New Fashion Product Sales with Image-based Google Trends
Oct 08, 2021
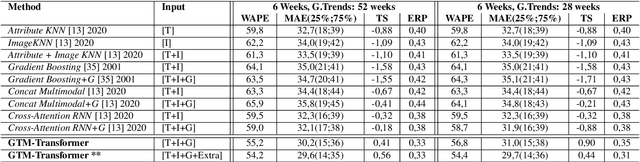
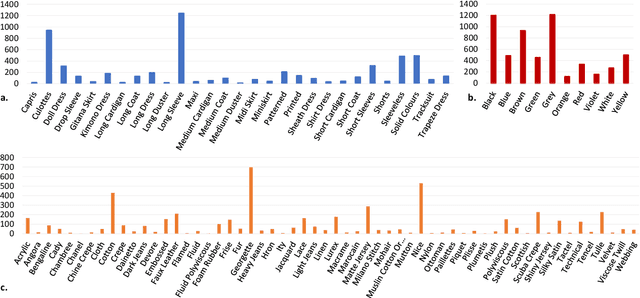
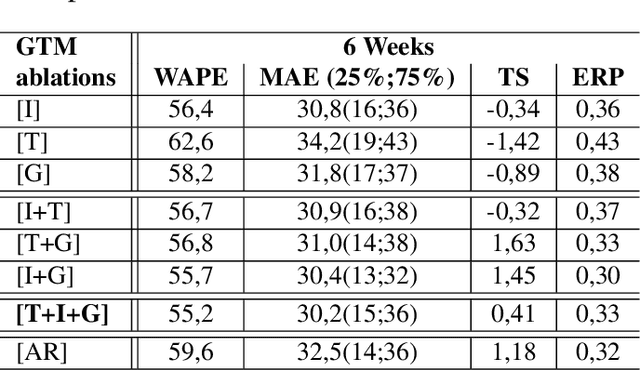
This paper investigates the effectiveness of systematically probing Google Trendsagainst textual translations of visual aspects as exogenous knowledge to predict the sales of brand-new fashion items, where past sales data is not available, but only an image and few metadata are available. In particular, we propose GTM-Transformer, standing for Google Trends Multimodal Transformer, whose encoder works on the representation of the exogenous time series, while the decoder forecasts the sales using the Google Trends encoding, and the available visual and metadata information. Our model works in a non-autoregressive manner, avoiding the compounding effect of the first-step errors. As a second contribution, we present the VISUELLE dataset, which is the first publicly available dataset for the task of new fashion product sales forecasting, containing the sales of 5577 new products sold between 2016-2019, derived from genuine historical data ofNunalie, an Italian fast-fashion company. Our dataset is equipped with images of products, metadata, related sales, and associated Google Trends. We use VISUELLE to compare our approach against state-of-the-art alternatives and numerous baselines, showing that GTM-Transformer is the most accurate in terms of both percentage and absolute error. It is worth noting that the addition of exogenous knowledge boosts the forecasting accuracy by 1.5% WAPE wise, showing the importance of exploiting Google Trends. The code and dataset are both available at https://github.com/HumaticsLAB/GTM-Transformer.
Texture Retrieval in the Wild through detection-based attributes
Oct 04, 2019



Capturing the essence of a textile image in a robust way is important to retrieve it in a large repository, especially if it has been acquired in the wild (by taking a photo of the textile of interest). In this paper we show that a texel-based representation fits well with this task. In particular, we refer to Texel-Att, a recent texel-based descriptor which has shown to capture fine grained variations of a texture, for retrieval purposes. After a brief explanation of Texel-Att, we will show in our experiments that this descriptor is robust to distortions resulting from acquisitions in the wild by setting up an experiment in which textures from the ElBa (an Element-Based texture dataset) are artificially distorted and then used to retrieve the original image. We compare our approach with existing descriptors using a simple ranking framework based on distance functions. Results show that even under extreme conditions (such as a down-sampling with a factor of 10), we perform better than alternative approaches.
Texel-Att: Representing and Classifying Element-based Textures by Attributes
Aug 30, 2019


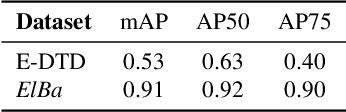
Element-based textures are a kind of texture formed by nameable elements, the texels [1], distributed according to specific statistical distributions; it is of primary importance in many sectors, namely textile, fashion and interior design industry. State-of-theart texture descriptors fail to properly characterize element-based texture, so we present Texel-Att to fill this gap. Texel-Att is the first fine-grained, attribute-based representation and classification framework for element-based textures. It first individuates texels, characterizing them with individual attributes; subsequently, texels are grouped and characterized through layout attributes, which give the Texel-Att representation. Texels are detected by a Mask-RCNN, trained on a brand-new element-based texture dataset, ElBa, containing 30K texture images with 3M fully-annotated texels. Examples of individual and layout attributes are exhibited to give a glimpse on the level of achievable graininess. In the experiments, we present detection results to show that texels can be precisely individuated, even on textures "in the wild"; to this sake, we individuate the element-based classes of the Describable Texture Dataset (DTD), where almost 900K texels have been manually annotated, leading to the Element-based DTD (E-DTD). Subsequently, classification and ranking results demonstrate the expressivity of Texel-Att on ElBa and E-DTD, overcoming the alternative features and relative attributes, doubling the best performance in some cases; finally, we report interactive search results on ElBa and E-DTD: with Texel-Att on the E-DTD dataset we are able to individuate within 10 iterations the desired texture in the 90% of cases, against the 71% obtained with a combination of the finest existing attributes so far. Dataset and code is available at https://github.com/godimarcovr/Texel-Att
SIMCO: SIMilarity-based object COunting
Apr 15, 2019
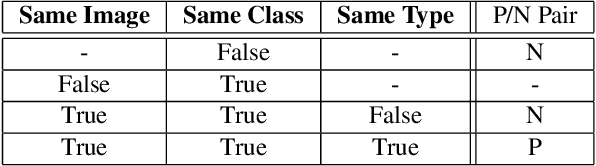
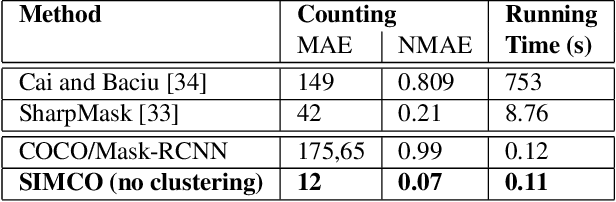
We present SIMCO, the first agnostic multi-class object counting approach. SIMCO starts by detecting foreground objects through a novel Mask RCNN-based architecture trained beforehand (just once) on a brand-new synthetic 2D shape dataset, InShape; the idea is to highlight every object resembling a primitive 2D shape (circle, square, rectangle, etc.). Each object detected is described by a low-dimensional embedding, obtained from a novel similarity-based head branch; this latter implements a triplet loss, encouraging similar objects (same 2D shape + color and scale) to map close. Subsequently, SIMCO uses this embedding for clustering, so that different types of objects can emerge and be counted, making SIMCO the very first multi-class unsupervised counter. Experiments show that SIMCO provides state-of-the-art scores on counting benchmarks and that it can also help in many challenging image understanding tasks.