 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOP: Mining POtential Performance of new fashion products via webly cross-modal query expansion
Paper and Code
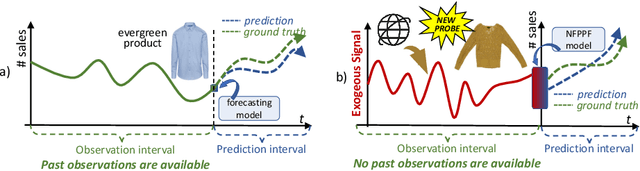


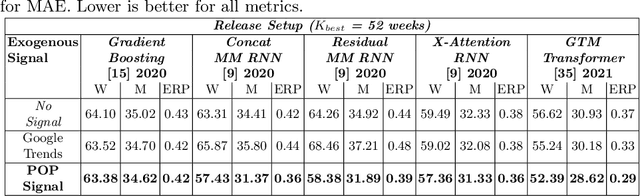
We propose a data-centric pipeline able to generate exogenous observation data for the New Fashion Product Performance Forecasting (NFPPF) problem, i.e., predicting the performance of a brand-new clothing probe with no available past observations. Our pipeline manufactures the missing past starting from a single, available image of the clothing probe. It starts by expanding textual tags associated with the image, querying related fashionable or unfashionable images uploaded on the web at a specific time in the past. A binary classifier is robustly trained on these web images by confident learning, to learn what was fashionable in the past and how much the probe image conforms to this notion of fashionability. This compliance produces the POtential Performance (POP) time series, indicating how performing the probe could have been if it were available earlier. POP proves to be highly predictive for the probe's future performance, ameliorating the sales forecasts of all state-of-the-art models on the recent VISUELLE fast-fashion dataset. We also show that POP reflects the ground-truth popularity of new styles (ensembles of clothing items) on the Fashion Forward benchmark, demonstrating that our webly-learned signal is a truthful expression of popularity, accessible by everyone and generalizable to any time of analysis. Forecasting code, data and the POP time series are available at: https://github.com/HumaticsLAB/POP-Mining-POtential-Performance