 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Latent Spaces Facilitate Data-Driven Auxiliary Learning
Oct 13, 2023


In deep learning, auxiliary objectives are often used to facilitate learning in situations where data is scarce, or the principal task is extremely complex. This idea is primarily inspired by the improved generalization capability induced by solving multiple tasks simultaneously, which leads to a more robust shared representation. Nevertheless, finding optimal auxiliary tasks that give rise to the desired improvement is a crucial problem that often requires hand-crafted solutions or expensive meta-learning approaches. In this paper, we propose a novel framework, dubbed Detaux, whereby a weakly supervised disentanglement procedure is used to discover new unrelated classification tasks and the associated labels that can be exploited with the principal task in any Multi-Task Learning (MTL) model. The disentanglement procedure works at a representation level, isolating a subspace related to the principal task, plus an arbitrary number of orthogonal subspaces. In the most disentangled subspaces, through a clustering procedure, we generate the additional classification tasks, and the associated labels become their representatives. Subsequently, the original data, the labels associated with the principal task, and the newly discovered ones can be fed into any MTL framework. Extensive validation on both synthetic and real data, along with various ablation studies, demonstrate promising results, revealing the potential in what has been, so far, an unexplored connection between learning disentangled representations and MTL. The code will be made publicly available upon acceptance.
On the use of learning-based forecasting methods for ameliorating fashion business processes: A position paper
Nov 09, 2022The fashion industry is one of the most active and competitive markets in the world, manufacturing millions of products and reaching large audiences every year. A plethora of business processes are involved in this large-scale industry, but due to the generally short life-cycle of clothing items, supply-chain management and retailing strategies are crucial for good market performance. Correctly understanding the wants and needs of clients, managing logistic issues and marketing the correct products are high-level problems with a lot of uncertainty associated to them given the number of influencing factors, but most importantly due to the unpredictability often associated with the future. It is therefore straightforward that forecasting methods, which generate predictions of the future, are indispensable in order to ameliorate all the various business processes that deal with the true purpose and meaning of fashion: having a lot of people wear a particular product or style, rendering these items, people and consequently brands fashionable. In this paper, we provide an overview of three concrete forecasting tasks that any fashion company can apply in order to improve their industrial and market impact. We underline advances and issues in all three tasks and argue about their importance and the impact they can have at an industrial level. Finally, we highlight issues and directions of future work, reflecting on how learning-based forecasting methods can further aid the fashion industry.
The multi-modal universe of fast-fashion: the Visuelle 2.0 benchmark
Apr 14, 2022
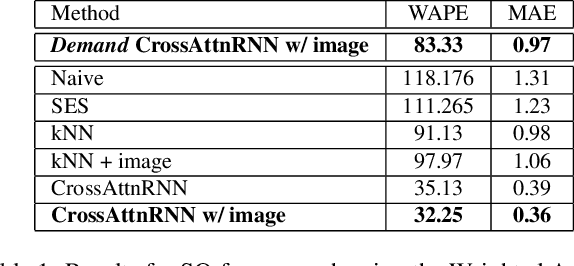
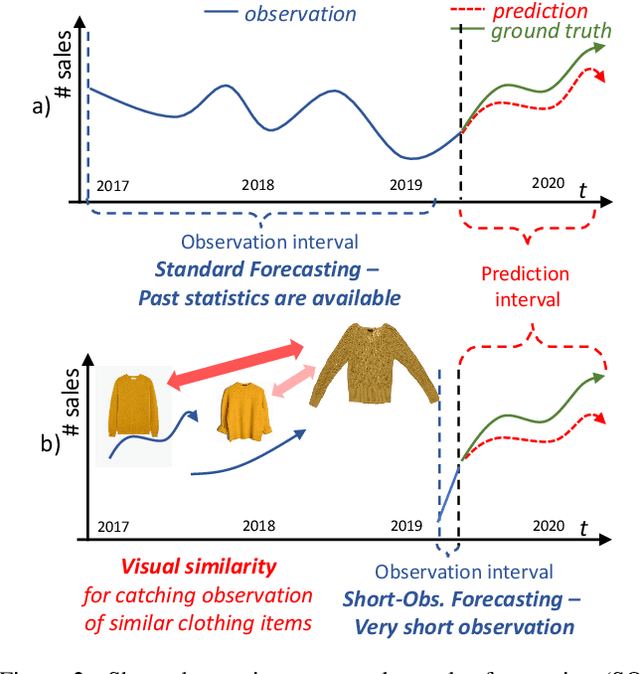
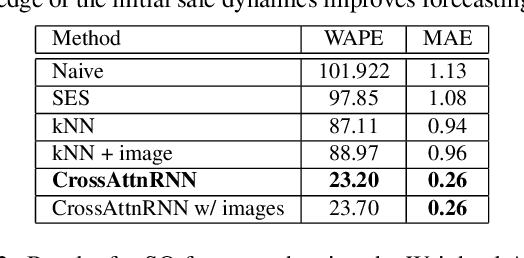
We present Visuelle 2.0, the first dataset useful for facing diverse prediction problems that a fast-fashion company has to manage routinely. Furthermore, we demonstrate how the use of computer vision is substantial in this scenario. Visuelle 2.0 contains data for 6 seasons / 5355 clothing products of Nuna Lie, a famous Italian company with hundreds of shops located in different areas within the country. In particular, we focus on a specific prediction problem, namely short-observation new product sale forecasting (SO-fore). SO-fore assumes that the season has started and a set of new products is on the shelves of the different stores. The goal is to forecast the sales for a particular horizon, given a short, available past (few weeks), since no earlier statistics are available. To be successful, SO-fore approaches should capture this short past and exploit other modalities or exogenous data. To these aims, Visuelle 2.0 is equipped with disaggregated data at the item-shop level and multi-modal information for each clothing item, allowing computer vision approaches to come into play. The main message that we deliver is that the use of image data with deep networks boosts performances obtained when using the time series in long-term forecasting scenarios, ameliorating the WAPE by 8.2% and the MAE by 7.7%. The dataset is available at: https://humaticslab.github.io/forecasting/visuelle.
Well Googled is Half Done: Multimodal Forecasting of New Fashion Product Sales with Image-based Google Trends
Oct 08, 2021
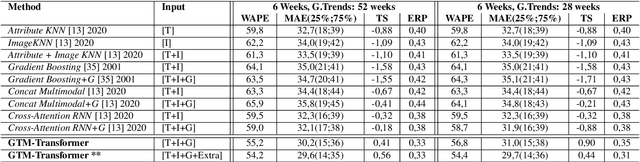
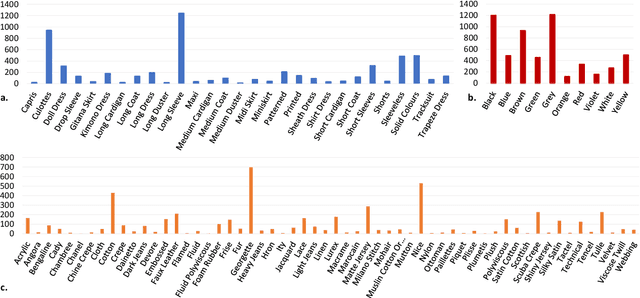
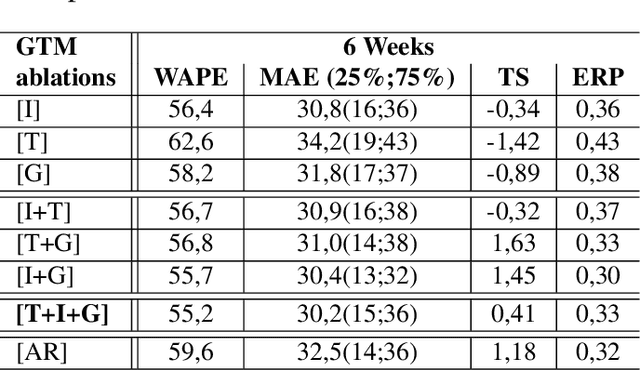
This paper investigates the effectiveness of systematically probing Google Trendsagainst textual translations of visual aspects as exogenous knowledge to predict the sales of brand-new fashion items, where past sales data is not available, but only an image and few metadata are available. In particular, we propose GTM-Transformer, standing for Google Trends Multimodal Transformer, whose encoder works on the representation of the exogenous time series, while the decoder forecasts the sales using the Google Trends encoding, and the available visual and metadata information. Our model works in a non-autoregressive manner, avoiding the compounding effect of the first-step errors. As a second contribution, we present the VISUELLE dataset, which is the first publicly available dataset for the task of new fashion product sales forecasting, containing the sales of 5577 new products sold between 2016-2019, derived from genuine historical data ofNunalie, an Italian fast-fashion company. Our dataset is equipped with images of products, metadata, related sales, and associated Google Trends. We use VISUELLE to compare our approach against state-of-the-art alternatives and numerous baselines, showing that GTM-Transformer is the most accurate in terms of both percentage and absolute error. It is worth noting that the addition of exogenous knowledge boosts the forecasting accuracy by 1.5% WAPE wise, showing the importance of exploiting Google Trends. The code and dataset are both available at https://github.com/HumaticsLAB/GTM-Transformer.