 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveGazen: Event-Based Driving Status Recognition using Conventional Camera
Dec 16, 2024
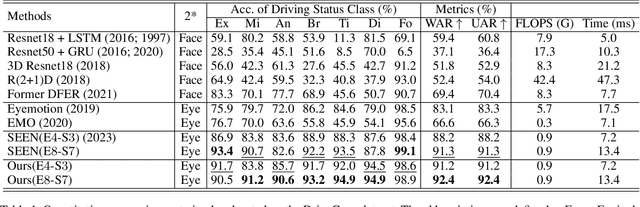
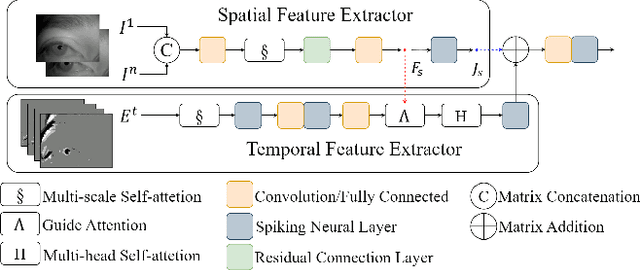
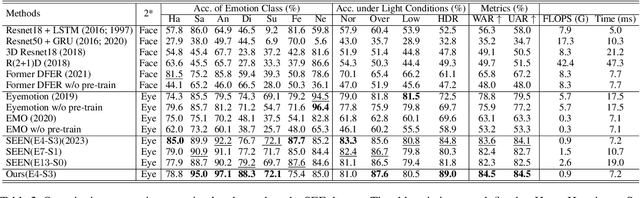
We introduce a wearable driving status recognition device and our open-source dataset, along with a new real-time method robust to changes in lighting conditions for identifying driving status from eye observations of drivers. The core of our method is generating event frames from conventional intensity frames, and the other is a newly designed Attention Driving State Network (ADSN). Compared to event cameras, conventional cameras offer complete information and lower hardware costs, enabling captured frames to encode rich spatial information. However, these textures lack temporal information, posing challenges in effectively identifying driving status. DriveGazen addresses this issue from three perspectives. First, we utilize video frames to generate realistic synthetic dynamic vision sensor (DVS) events. Second, we adopt a spiking neural network to decode pertinent temporal information. Lastly, ADSN extracts crucial spatial cues from corresponding intensity frames and conveys spatial attention to convolutional spiking layers during both training and inference through a novel guide attention module to guide the feature learning and feature enhancement of the event frame. We specifically collected the Driving Status (DriveGaze) dataset to demonstrate the effectiveness of our approach. Additionally, we validate the superiority of the DriveGazen on the Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first to utilize guide attention spiking neural networks and eye-based event frames generated from conventional cameras for driving status recognition. Please refer to our project page for more details: https://github.com/TooyoungALEX/AAAI25-DriveGazen.
Explainable Object-induced Action Decision for Autonomous Vehicles
Mar 20, 2020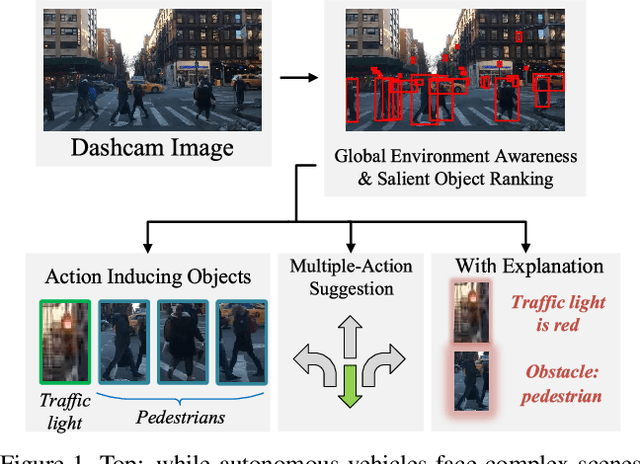
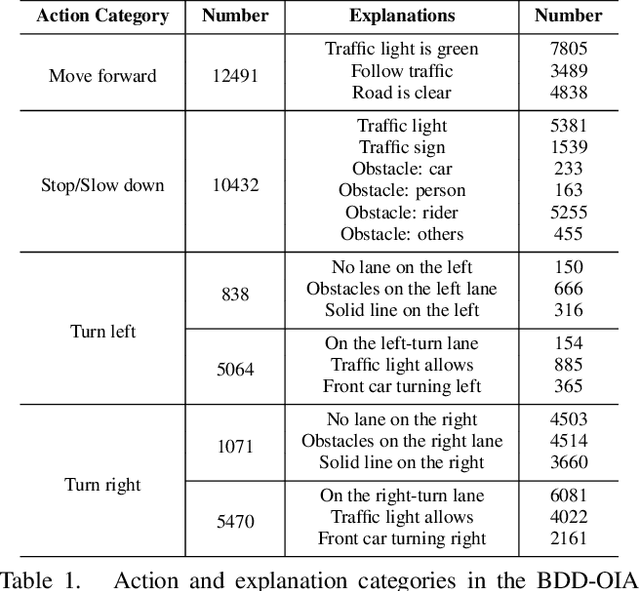
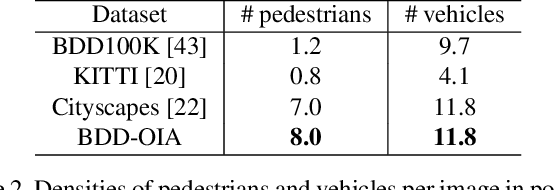

A new paradigm is proposed for autonomous driving. The new paradigm lies between the end-to-end and pipelined approaches, and is inspired by how humans solve the problem. While it relies on scene understanding, the latter only considers objects that could originate hazard. These are denoted as action-inducing, since changes in their state should trigger vehicle actions. They also define a set of explanations for these actions, which should be produced jointly with the latter. An extension of the BDD100K dataset, annotated for a set of 4 actions and 21 explanations, is proposed. A new multi-task formulation of the problem, which optimizes the accuracy of both action commands and explanations, is then introduced. A CNN architecture is finally proposed to solve this problem, by combining reasoning about action inducing objects and global scene context. Experimental results show that the requirement of explanations improves the recognition of action-inducing objects, which in turn leads to better action predictions.