 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTE2Rules: Extracting Rule Lists from Tree Ensembles
Jun 30, 2022

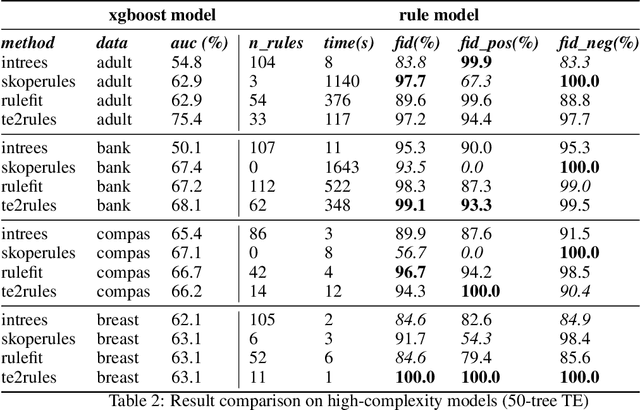

Tree Ensemble (TE) models (e.g. Gradient Boosted Trees and Random Forests) often provide higher prediction performance compared to single decision trees. However, TE models generally lack transparency and interpretability, as humans have difficulty understanding their decision logic. This paper presents a novel approach to convert a TE trained for a binary classification task, to a rule list (RL) that is a global equivalent to the TE and is comprehensible for a human. This RL captures all necessary and sufficient conditions for decision making by the TE. Experiments on benchmark datasets demonstrate that, compared to state-of-the-art methods, (i) predictions from the RL generated by TE2Rules have high fidelity with respect to the original TE, (ii) the RL from TE2Rules has high interpretability measured by the number and the length of the decision rules, (iii) the run-time of TE2Rules algorithm can be reduced significantly at the cost of a slightly lower fidelity, and (iv) the RL is a fast alternative to the state-of-the-art rule-based instance-level outcome explanation techniques.
Fairness-Aware Online Personalization
Sep 06, 2020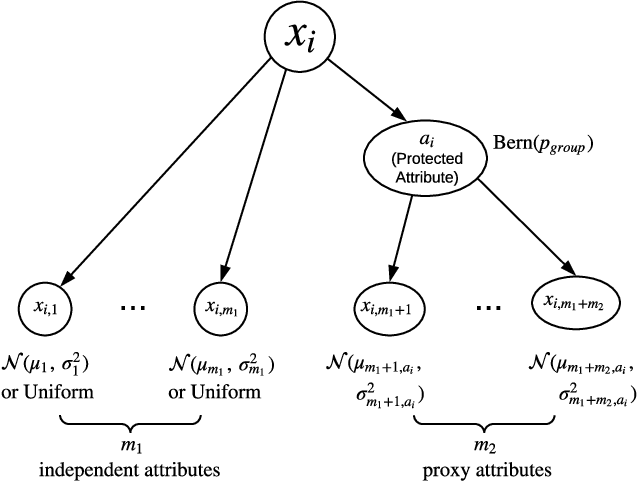
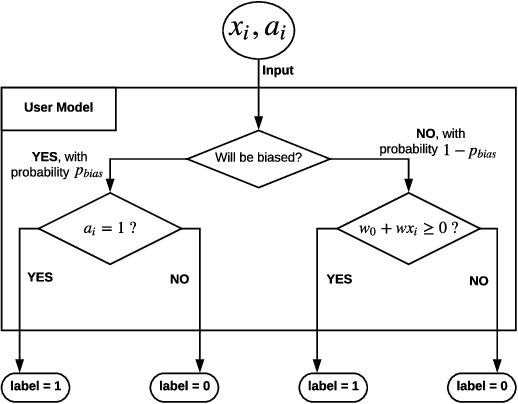
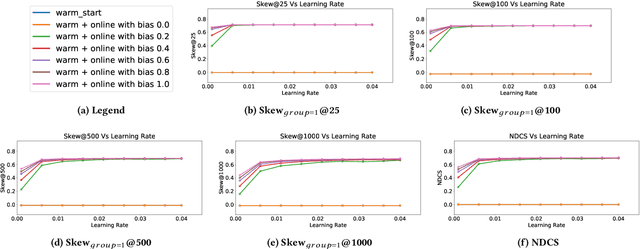
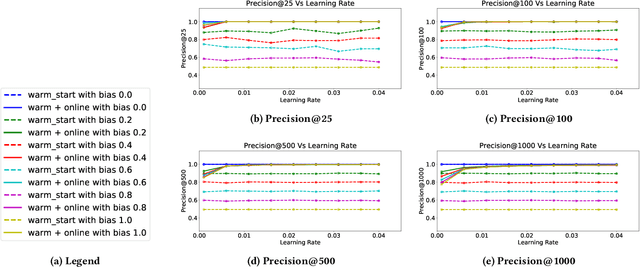
Decision making in crucial applications such as lending, hiring, and college admissions has witnessed increasing use of algorithmic models and techniques as a result of a confluence of factors such as ubiquitous connectivity, ability to collect, aggregate, and process large amounts of fine-grained data using cloud computing, and ease of access to applying sophisticated machine learning models. Quite often, such applications are powered by search and recommendation systems, which in turn make use of personalized ranking algorithms. At the same time, there is increasing awareness about the ethical and legal challenges posed by the use of such data-driven systems. Researchers and practitioners from different disciplines have recently highlighted the potential for such systems to discriminate against certain population groups, due to biases in the datasets utilized for learning their underlying recommendation models. We present a study of fairness in online personalization settings involving the ranking of individuals. Starting from a fair warm-start machine-learned model, we first demonstrate that online personalization can cause the model to learn to act in an unfair manner if the user is biased in his/her responses. For this purpose, we construct a stylized model for generating training data with potentially biased features as well as potentially biased labels and quantify the extent of bias that is learned by the model when the user responds in a biased manner as in many real-world scenarios. We then formulate the problem of learning personalized models under fairness constraints and present a regularization based approach for mitigating biases in machine learning. We demonstrate the efficacy of our approach through extensive simulations with different parameter settings. Code: https://github.com/groshanlal/Fairness-Aware-Online-Personalization