 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Hierarchical Representations for Preserving Privacy and Utility in Text
Oct 20, 2019



Guaranteeing a certain level of user privacy in an arbitrary piece of text is a challenging issue. However, with this challenge comes the potential of unlocking access to vast data stores for training machine learning models and supporting data driven decisions. We address this problem through the lens of dx-privacy, a generalization of Differential Privacy to non Hamming distance metrics. In this work, we explore word representations in Hyperbolic space as a means of preserving privacy in text. We provide a proof satisfying dx-privacy, then we define a probability distribution in Hyperbolic space and describe a way to sample from it in high dimensions. Privacy is provided by perturbing vector representations of words in high dimensional Hyperbolic space to obtain a semantic generalization. We conduct a series of experiments to demonstrate the tradeoff between privacy and utility. Our privacy experiments illustrate protections against an authorship attribution algorithm while our utility experiments highlight the minimal impact of our perturbations on several downstream machine learning models. Compared to the Euclidean baseline, we observe > 20x greater guarantees on expected privacy against comparable worst case statistics.
Privacy- and Utility-Preserving Textual Analysis via Calibrated Multivariate Perturbations
Oct 20, 2019



Accurately learning from user data while providing quantifiable privacy guarantees provides an opportunity to build better ML models while maintaining user trust. This paper presents a formal approach to carrying out privacy preserving text perturbation using the notion of dx-privacy designed to achieve geo-indistinguishability in location data. Our approach applies carefully calibrated noise to vector representation of words in a high dimension space as defined by word embedding models. We present a privacy proof that satisfies dx-privacy where the privacy parameter epsilon provides guarantees with respect to a distance metric defined by the word embedding space. We demonstrate how epsilon can be selected by analyzing plausible deniability statistics backed up by large scale analysis on GloVe and fastText embeddings. We conduct privacy audit experiments against 2 baseline models and utility experiments on 3 datasets to demonstrate the tradeoff between privacy and utility for varying values of epsilon on different task types. Our results demonstrate practical utility (< 2% utility loss for training binary classifiers) while providing better privacy guarantees than baseline models.
Privacy-preserving Active Learning on Sensitive Data for User Intent Classification
Mar 26, 2019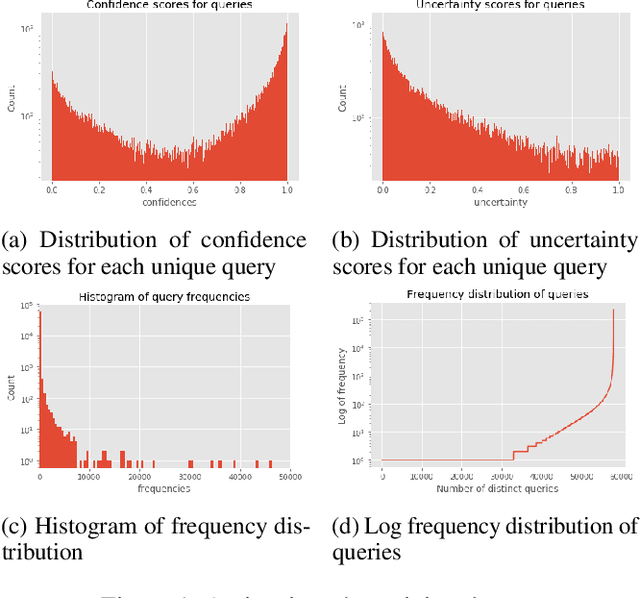

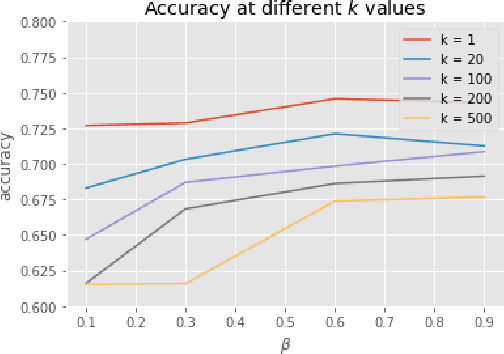
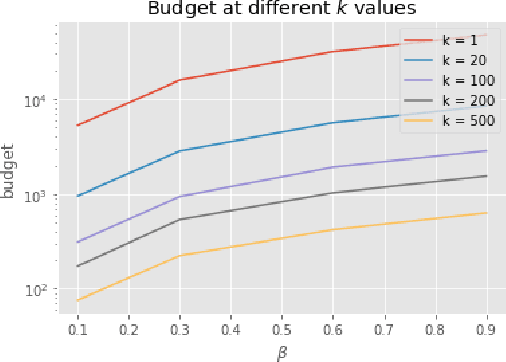
Active learning holds promise of significantly reducing data annotation costs while maintaining reasonable model performance. However, it requires sending data to annotators for labeling. This presents a possible privacy leak when the training set includes sensitive user data. In this paper, we describe an approach for carrying out privacy preserving active learning with quantifiable guarantees. We evaluate our approach by showing the tradeoff between privacy, utility and annotation budget on a binary classification task in a active learning setting.
Leveraging Crowdsourcing Data For Deep Active Learning - An Application: Learning Intents in Alexa
Mar 12, 2018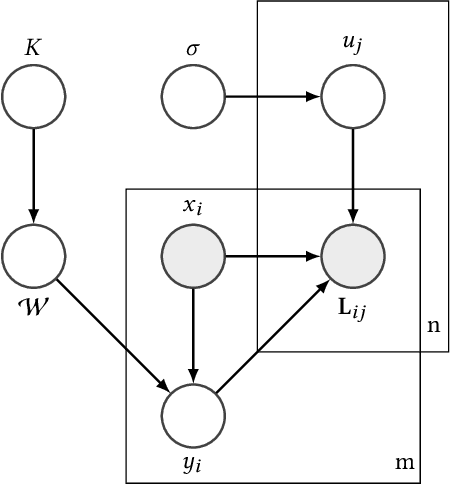

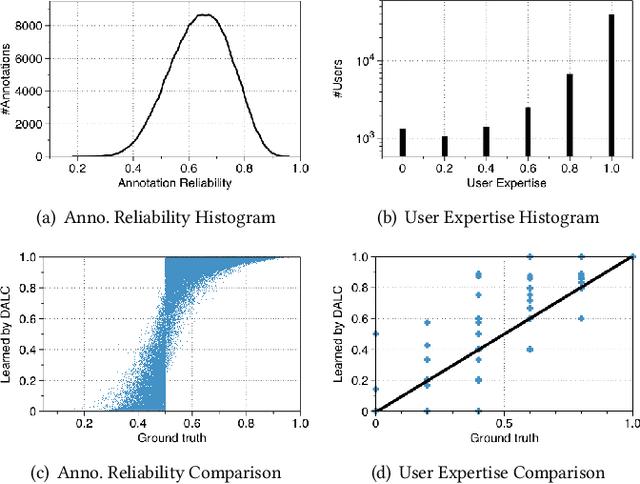

This paper presents a generic Bayesian framework that enables any deep learning model to actively learn from targeted crowds. Our framework inherits from recent advances in Bayesian deep learning, and extends existing work by considering the targeted crowdsourcing approach, where multiple annotators with unknown expertise contribute an uncontrolled amount (often limited) of annotations. Our framework leverages the low-rank structure in annotations to learn individual annotator expertise, which then helps to infer the true labels from noisy and sparse annotations. It provides a unified Bayesian model to simultaneously infer the true labels and train the deep learning model in order to reach an optimal learning efficacy. Finally, our framework exploits the uncertainty of the deep learning model during prediction as well as the annotators' estimated expertise to minimize the number of required annotations and annotators for optimally training the deep learning model. We evaluate the effectiveness of our framework for intent classification in Alexa (Amazon's personal assistant), using both synthetic and real-world datasets. Experiments show that our framework can accurately learn annotator expertise, infer true labels, and effectively reduce the amount of annotations in model training as compared to state-of-the-art approaches. We further discuss the potential of our proposed framework in bridging machine learning and crowdsourcing towards improved human-in-the-loop systems.