 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDR: Efficient Neural Re-ranking using Succinct Document Representation
Paper and Code
Oct 03, 2021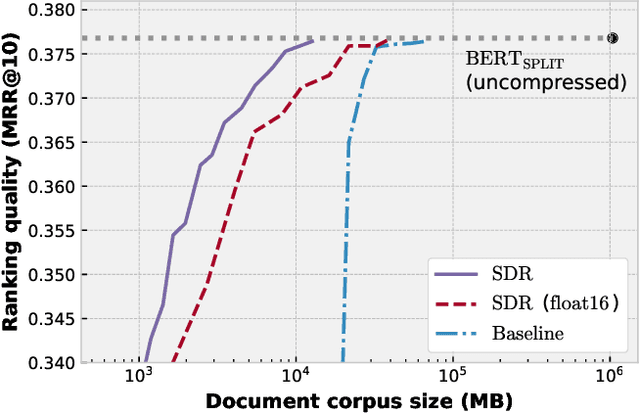
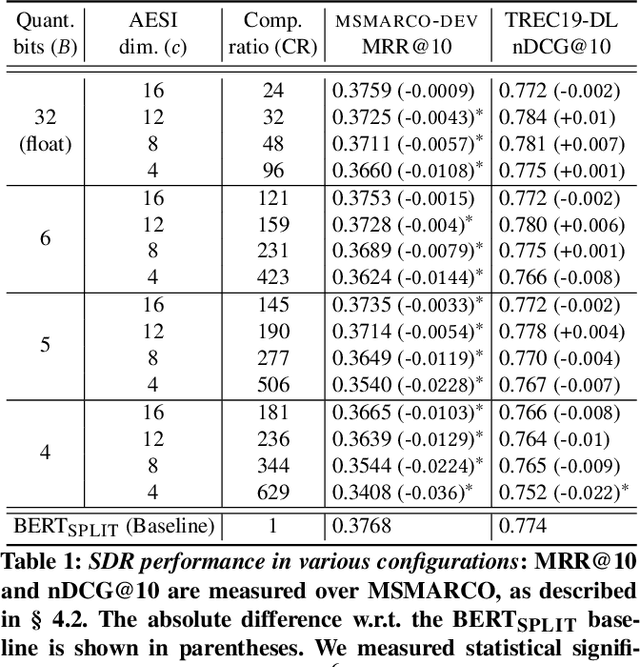
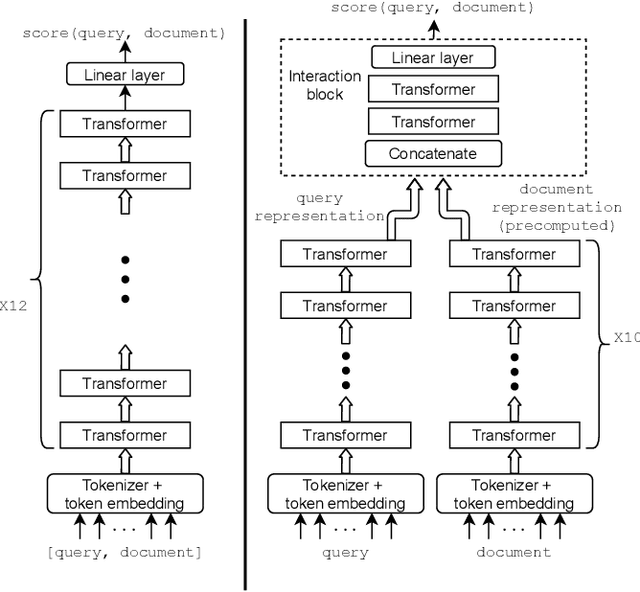
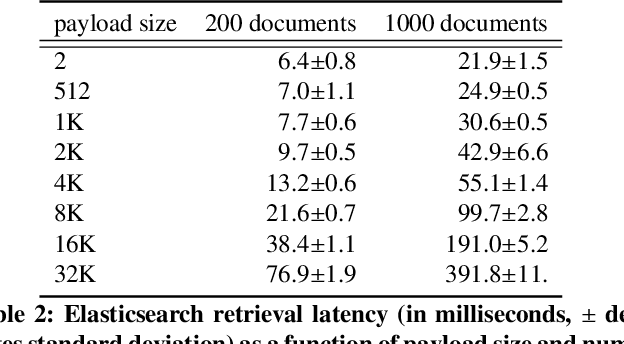
BERT based ranking models have achieved superior performance on various information retrieval tasks. However, the large number of parameters and complex self-attention operation come at a significant latency overhead. To remedy this, recent works propose late-interaction architectures, which allow pre-computation of intermediate document representations, thus reducing the runtime latency. Nonetheless, having solved the immediate latency issue, these methods now introduce storage costs and network fetching latency, which limits their adoption in real-life production systems. In this work, we propose the Succinct Document Representation (SDR) scheme that computes highly compressed intermediate document representations, mitigating the storage/network issue. Our approach first reduces the dimension of token representations by encoding them using a novel autoencoder architecture that uses the document's textual content in both the encoding and decoding phases. After this token encoding step, we further reduce the size of entire document representations using a modern quantization technique. Extensive evaluations on passage re-reranking on the MSMARCO dataset show that compared to existing approaches using compressed document representations, our method is highly efficient, achieving 4x-11.6x better compression rates for the same ranking quality.