 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPLqa: An Unsupervised Information-Theoretic Quality Metric for Comparing Generative Large Language Models
Nov 22, 2024We propose PPLqa, an easy to compute, language independent, information-theoretic metric to measure the quality of responses of generative Large Language Models (LLMs) in an unsupervised way, without requiring ground truth annotations or human supervision. The method and metric enables users to rank generative language models for quality of responses, so as to make a selection of the best model for a given task. Our single metric assesses LLMs with an approach that subsumes, but is not explicitly based on, coherence and fluency (quality of writing) and relevance and consistency (appropriateness of response) to the query. PPLqa performs as well as other related metrics, and works better with long-form Q\&A. Thus, PPLqa enables bypassing the lengthy annotation process required for ground truth evaluations, and it also correlates well with human and LLM rankings.
Improving language models fine-tuning with representation consistency targets
May 23, 2022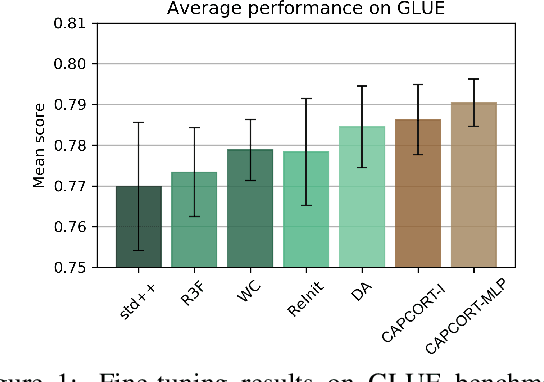

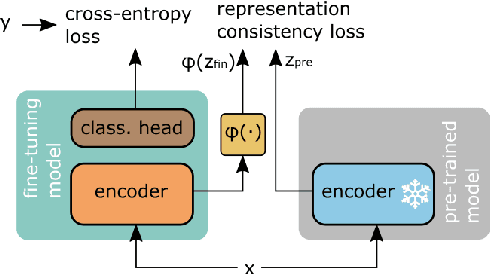

Fine-tuning contextualized representations learned by pre-trained language models has become a standard practice in the NLP field. However, pre-trained representations are prone to degradation (also known as representation collapse) during fine-tuning, which leads to instability, suboptimal performance, and weak generalization. In this paper, we propose a novel fine-tuning method that avoids representation collapse during fine-tuning by discouraging undesirable changes in the representations. We show that our approach matches or exceeds the performance of the existing regularization-based fine-tuning methods across 13 language understanding tasks (GLUE benchmark and six additional datasets). We also demonstrate its effectiveness in low-data settings and robustness to label perturbation. Furthermore, we extend previous studies of representation collapse and propose several metrics to quantify it. Using these metrics and previously proposed experiments, we show that our approach obtains significant improvements in retaining the expressive power of representations.
Improving Early Sepsis Prediction with Multi Modal Learning
Jul 23, 2021
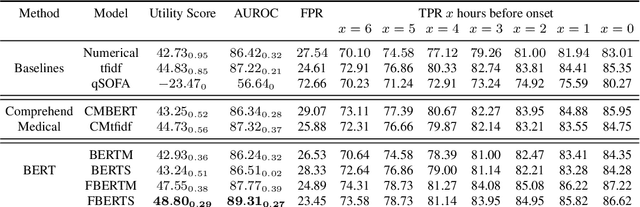


Sepsis is a life-threatening disease with high morbidity, mortality and healthcare costs. The early prediction and administration of antibiotics and intravenous fluids is considered crucial for the treatment of sepsis and can save potentially millions of lives and billions in health care costs. Professional clinical care practitioners have proposed clinical criterion which aid in early detection of sepsis; however, performance of these criterion is often limited. Clinical text provides essential information to estimate the severity of the sepsis in addition to structured clinical data. In this study, we explore how clinical text can complement structured data towards early sepsis prediction task. In this paper, we propose multi modal model which incorporates both structured data in the form of patient measurements as well as textual notes on the patient. We employ state-of-the-art NLP models such as BERT and a highly specialized NLP model in Amazon Comprehend Medical to represent the text. On the MIMIC-III dataset containing records of ICU admissions, we show that by using these notes, one achieves an improvement of 6.07 points in a standard utility score for Sepsis prediction and 2.89% in AUROC score. Our methods significantly outperforms a clinical criteria suggested by experts, qSOFA, as well as the winning model of the PhysioNet Computing in Cardiology Challenge for predicting Sepsis.