 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisTIRA: Closing the Image-Text Modality Gap in Visual Math Reasoning via Structured Tool Integration
Jan 20, 2026Vision-language models (VLMs) lag behind text-only language models on mathematical reasoning when the same problems are presented as images rather than text. We empirically characterize this as a modality gap: the same question in text form yields markedly higher accuracy than its visually typeset counterpart, due to compounded failures in reading dense formulas, layout, and mixed symbolic-diagrammatic context. First, we introduce VisTIRA (Vision and Tool-Integrated Reasoning Agent), a tool-integrated reasoning framework that enables structured problem solving by iteratively decomposing a given math problem (as an image) into natural language rationales and executable Python steps to determine the final answer. Second, we build a framework to measure and improve visual math reasoning: a LaTeX-based pipeline that converts chain-of-thought math corpora (e.g., NuminaMath) into challenging image counterparts, and a large set of synthetic tool-use trajectories derived from a real-world, homework-style image dataset (called SnapAsk) for fine-tuning VLMs. Our experiments show that tool-integrated supervision improves image-based reasoning, and OCR grounding can further narrow the gap for smaller models, although its benefit diminishes at scale. These findings highlight that modality gap severity inversely correlates with model size, and that structured reasoning and OCR-based grounding are complementary strategies for advancing visual mathematical reasoning.
Comparison of Machine Learning Methods for Predicting Winter Wheat Yield in Germany
May 04, 2021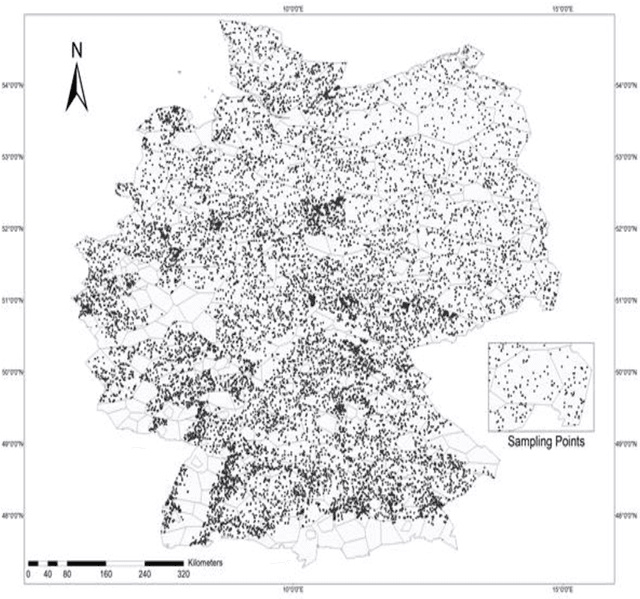
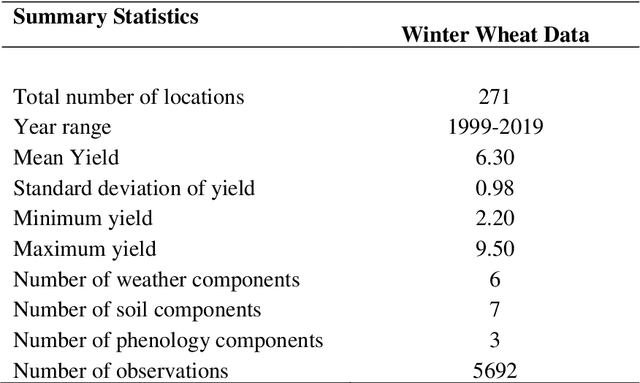
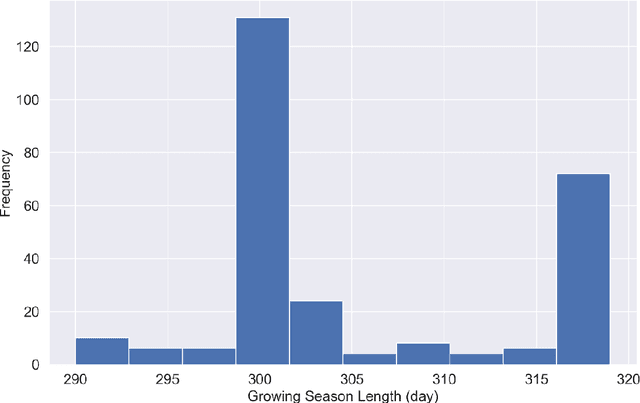
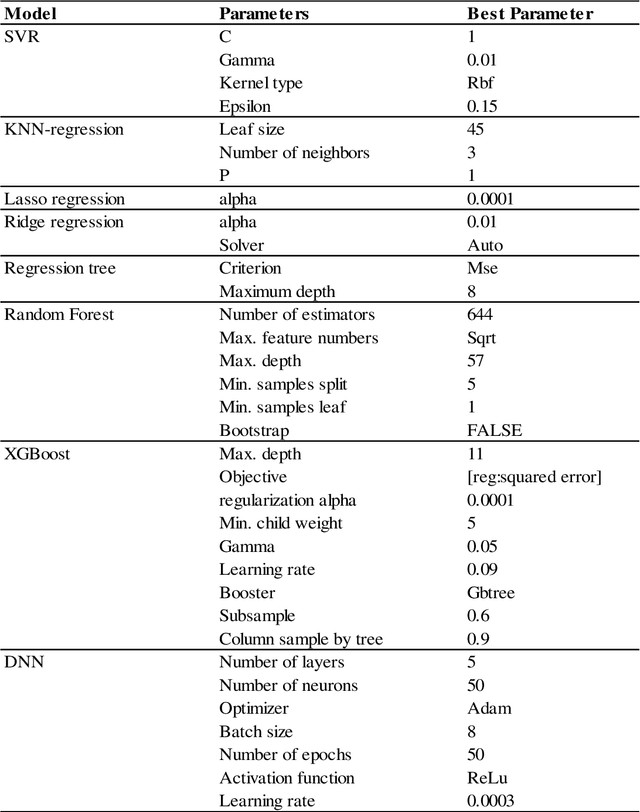
This study analyzed the performance of different machine learning methods for winter wheat yield prediction using extensive datasets of weather, soil, and crop phenology. To address the seasonality, weekly features were used that explicitly take soil moisture conditions and meteorological events into account. Our results indicated that nonlinear models such as deep neural networks (DNN) and XGboost are more effective in finding the functional relationship between the crop yield and input data compared to linear models. The results also revealed that the deep neural networks often had a higher prediction accuracy than XGboost. One of the main limitations of machine learning models is their black box property. As a result, we moved beyond prediction and performed feature selection, as it provides key results towards explaining yield prediction (variable importance by time). The feature selection method estimated the individual effect of weather components, soil conditions, and phenology variables as well as the time that these variables become important. As such, our study indicates which variables have the most significant effect on winter wheat yield.
WheatNet: A Lightweight Convolutional Neural Network for High-throughput Image-based Wheat Head Detection and Counting
Mar 20, 2021
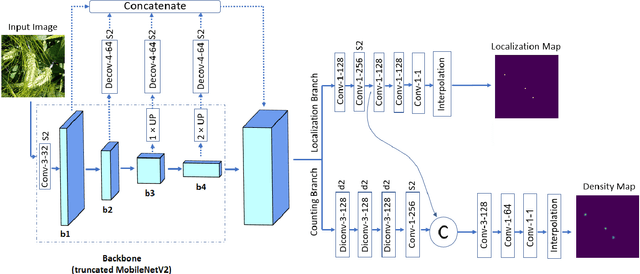
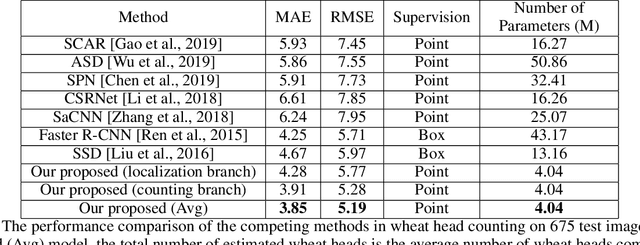

For a globally recognized planting breeding organization, manually-recorded field observation data is crucial for plant breeding decision making. However, certain phenotypic traits such as plant color, height, kernel counts, etc. can only be collected during a specific time-window of a crop's growth cycle. Due to labor-intensive requirements, only a small subset of possible field observations are recorded each season. To help mitigate this data collection bottleneck in wheat breeding, we propose a novel deep learning framework to accurately and efficiently count wheat heads to aid in the gathering of real-time data for decision making. We call our model WheatNet and show that our approach is robust and accurate for a wide range of environmental conditions of the wheat field. WheatNet uses a truncated MobileNetV2 as a lightweight backbone feature extractor which merges feature maps with different scales to counter image scale variations. Then, extracted multi-scale features go to two parallel sub-networks for simultaneous density-based counting and localization tasks. Our proposed method achieves an MAE and RMSE of 3.85 and 5.19 in our wheat head counting task, respectively, while having significantly fewer parameters when compared to other state-of-the-art methods. Our experiments and comparisons with other state-of-the-art methods demonstrate the superiority and effectiveness of our proposed method.
Regularization and False Alarms Quantification: Two Sides of the Explainability Coin
Dec 02, 2020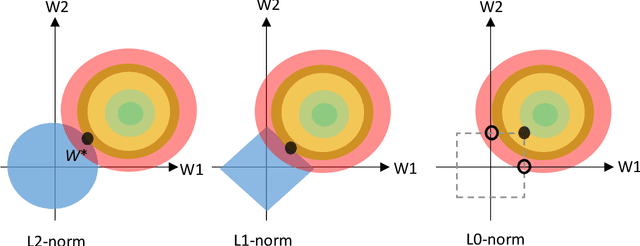
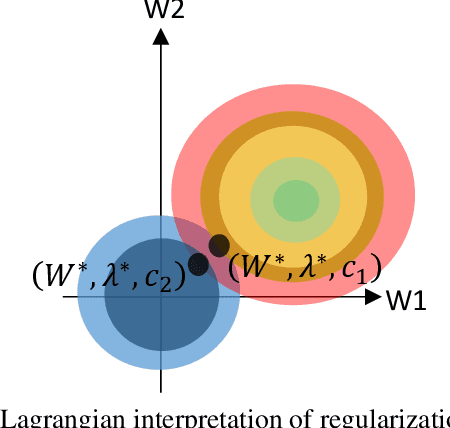
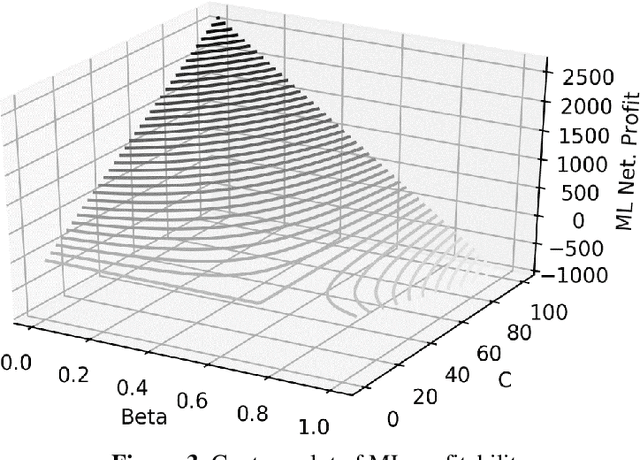
Regularization is a well-established technique in machine learning (ML) to achieve an optimal bias-variance trade-off which in turn reduces model complexity and enhances explainability. To this end, some hyper-parameters must be tuned, enabling the ML model to accurately fit the unseen data as well as the seen data. In this article, the authors argue that the regularization of hyper-parameters and quantification of costs and risks of false alarms are in reality two sides of the same coin, explainability. Incorrect or non-existent estimation of either quantities undermines the measurability of the economic value of using ML, to the extent that might make it practically useless.
Correspondent Banking Networks: Theory and Experiment
Dec 06, 2019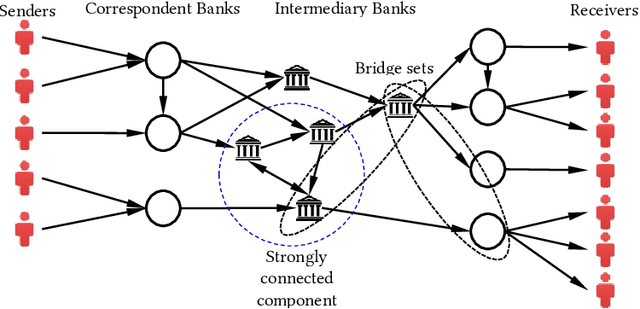


We employ the mathematical programming approach in conjunction with the graph theory to study the structure of correspondent banking networks. Optimizing the network requires decisions to be made to onboard, terminate or restrict the bank relationships to optimize the size and overall risk of the network. This study provides theoretical foundation to detect the components, the removal of which does not affect some key properties of the network such as connectivity and diameter. We find that the correspondent banking networks have a feature we call k-accessibility, which helps to drastically reduce the computational burden required for finding the above mentioned components. We prove a number of fundamental theorems related to k-accessible directed graphs, which should be also applicable beyond the particular problem of financial networks. The theoretical findings are verified through the data from a large international bank.
A Swift Heuristic Method for Work Order Scheduling under the Skilled-Workforce Constraint
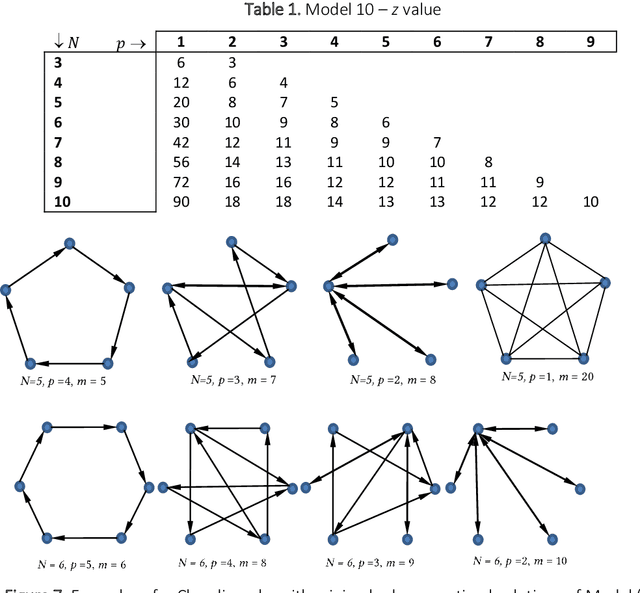
Mar 03, 2018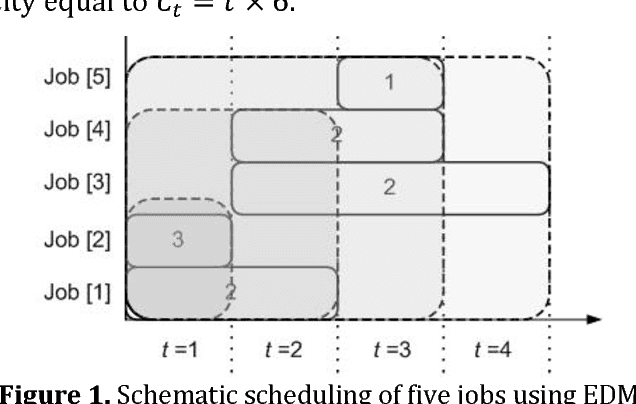
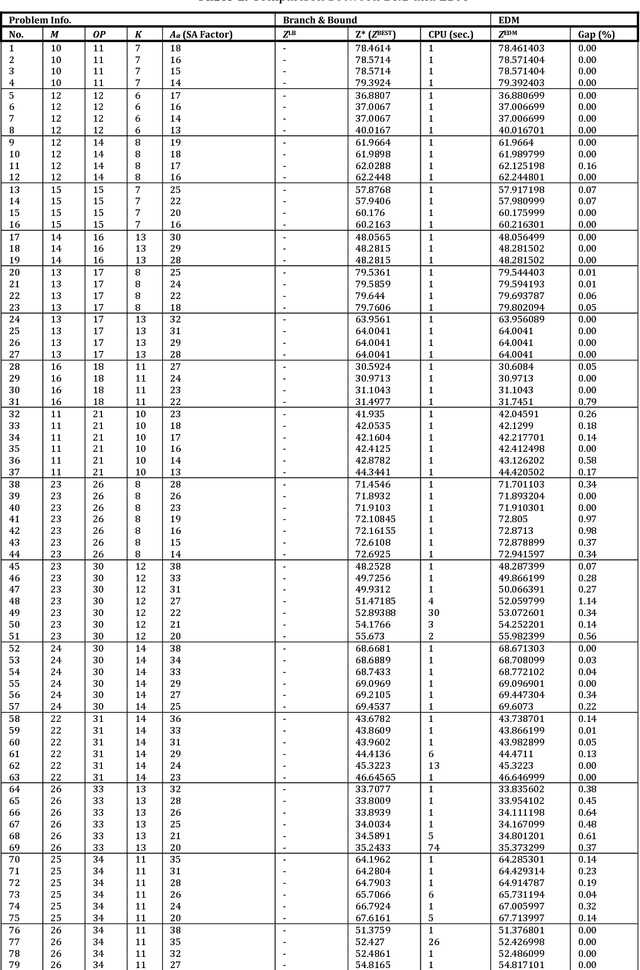
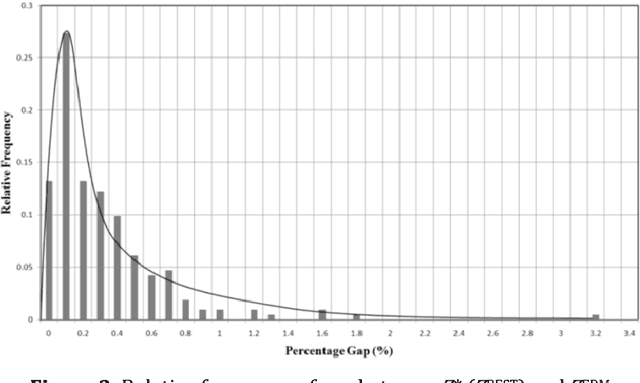
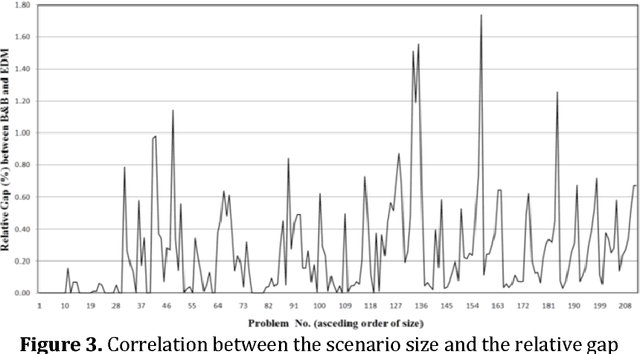
The considered problem is how to optimally allocate a set of jobs to technicians of different skills such that the number of technicians of each skill does not exceed the number of persons with that skill designation. The key motivation is the quick sensitivity analysis in terms of the workforce size which is quite necessary in many industries in the presence of unexpected work orders. A time-indexed mathematical model is proposed to minimize the total weighted completion time of the jobs. The proposed model is decomposed into a number of single-skill sub-problems so that each one is a combination of a series of nested binary Knapsack problems. A heuristic procedure is proposed to solve the problem. Our experimental results, based on a real-world case study, reveal that the proposed method quickly produces a schedule statistically close to the optimal one while the classical optimal procedure is very time-consuming.