Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization and False Alarms Quantification: Two Sides of the Explainability Coin
Dec 02, 2020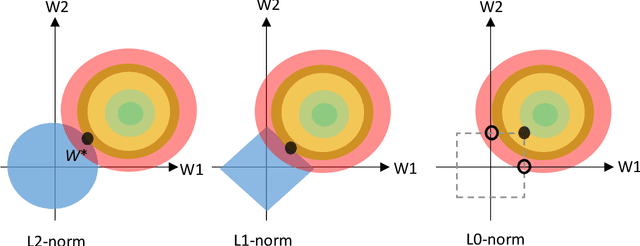
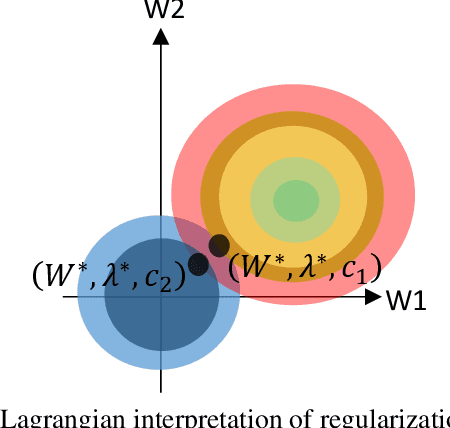
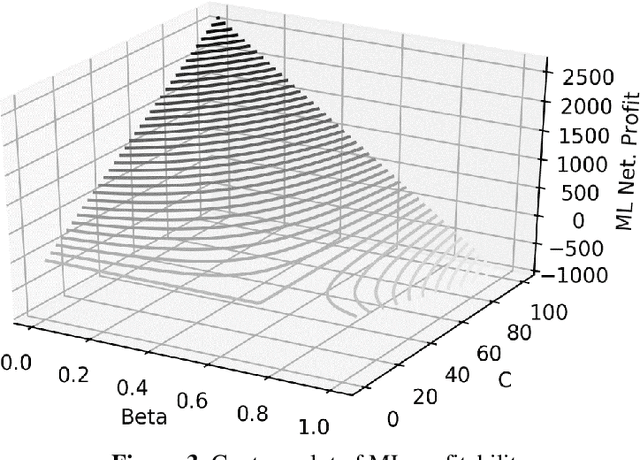
Regularization is a well-established technique in machine learning (ML) to achieve an optimal bias-variance trade-off which in turn reduces model complexity and enhances explainability. To this end, some hyper-parameters must be tuned, enabling the ML model to accurately fit the unseen data as well as the seen data. In this article, the authors argue that the regularization of hyper-parameters and quantification of costs and risks of false alarms are in reality two sides of the same coin, explainability. Incorrect or non-existent estimation of either quantities undermines the measurability of the economic value of using ML, to the extent that might make it practically useless.
Via