 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom WSI-level to Patch-level: Structure Prior Guided Binuclear Cell Fine-grained Detection
Aug 26, 2022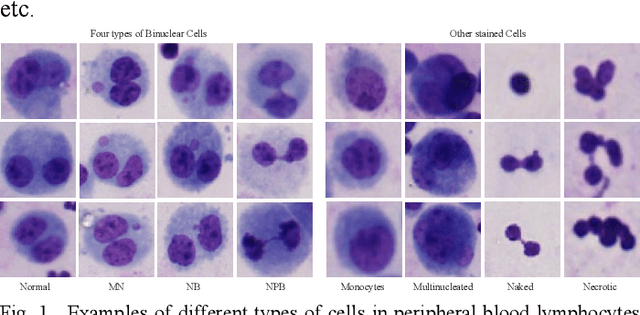
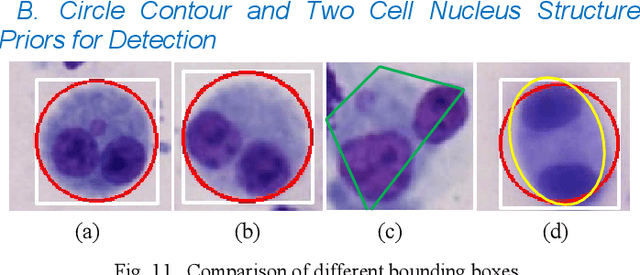
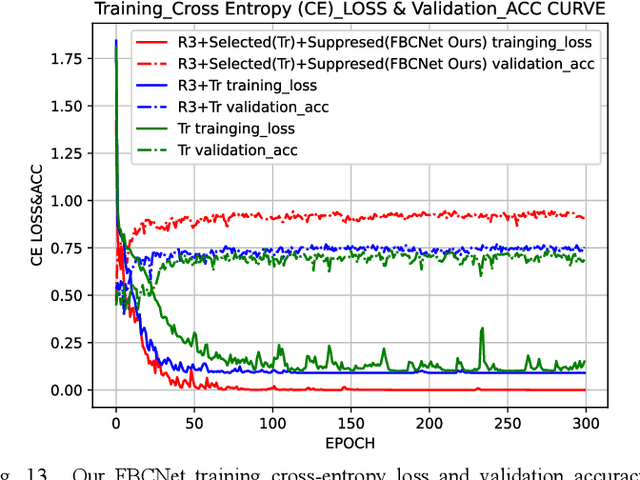
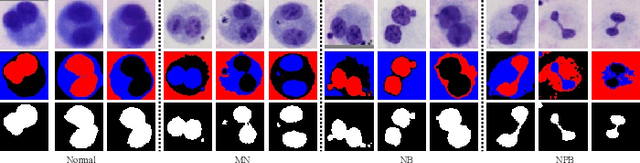
Accurately and quickly binuclear cell (BC) detection plays a significant role in predicting the risk of leukemia and other malignant tumors. However, manual microscopy counting is time-consuming and lacks objectivity. Moreover, with the limitation of staining quality and diversity of morphology features in BC microscopy whole slide images (WSIs), traditional image processing approaches are helpless. To overcome this challenge, we propose a two-stage detection method inspired by the structure prior of BC based on deep learning, which cascades to implement BCs coarse detection at the WSI-level and fine-grained classification in patch-level. The coarse detection network is a multi-task detection framework based on circular bounding boxes for cells detection, and central key points for nucleus detection. The circle representation reduces the degrees of freedom, mitigates the effect of surrounding impurities compared to usual rectangular boxes and can be rotation invariant in WSI. Detecting key points in the nucleus can assist network perception and be used for unsupervised color layer segmentation in later fine-grained classification. The fine classification network consists of a background region suppression module based on color layer mask supervision and a key region selection module based on a transformer due to its global modeling capability. Additionally, an unsupervised and unpaired cytoplasm generator network is firstly proposed to expand the long-tailed distribution dataset. Finally, experiments are performed on BC multicenter datasets. The proposed BC fine detection method outperforms other benchmarks in almost all the evaluation criteria, providing clarification and support for tasks such as cancer screenings.
An Applied Deep Learning Approach for Estimating Soybean Relative Maturity from UAV Imagery to Aid Plant Breeding Decisions
Aug 02, 2021
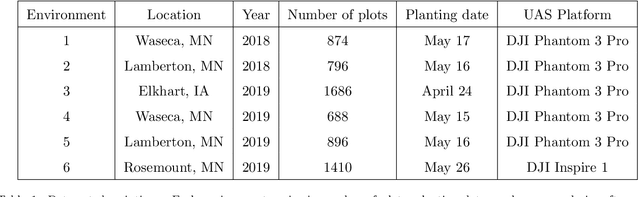
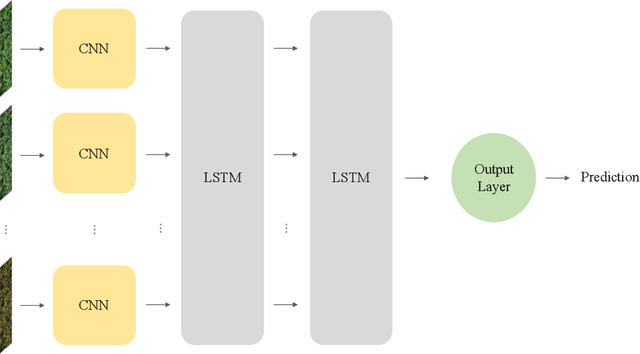
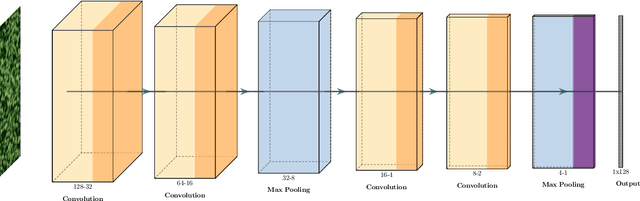
For a global breeding organization, identifying the next generation of superior crops is vital for its success. Recognizing new genetic varieties requires years of in-field testing to gather data about the crop's yield, pest resistance, heat resistance, etc. At the conclusion of the growing season, organizations need to determine which varieties will be advanced to the next growing season (or sold to farmers) and which ones will be discarded from the candidate pool. Specifically for soybeans, identifying their relative maturity is a vital piece of information used for advancement decisions. However, this trait needs to be physically observed, and there are resource limitations (time, money, etc.) that bottleneck the data collection process. To combat this, breeding organizations are moving toward advanced image capturing devices. In this paper, we develop a robust and automatic approach for estimating the relative maturity of soybeans using a time series of UAV images. An end-to-end hybrid model combining Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) is proposed to extract features and capture the sequential behavior of time series data. The proposed deep learning model was tested on six different environments across the United States. Results suggest the effectiveness of our proposed CNN-LSTM model compared to the local regression method. Furthermore, we demonstrate how this newfound information can be used to aid in plant breeding advancement decisions.
A reinforcement learning approach to resource allocation in genomic selection
Jul 22, 2021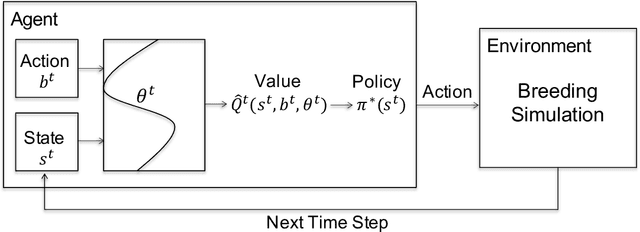
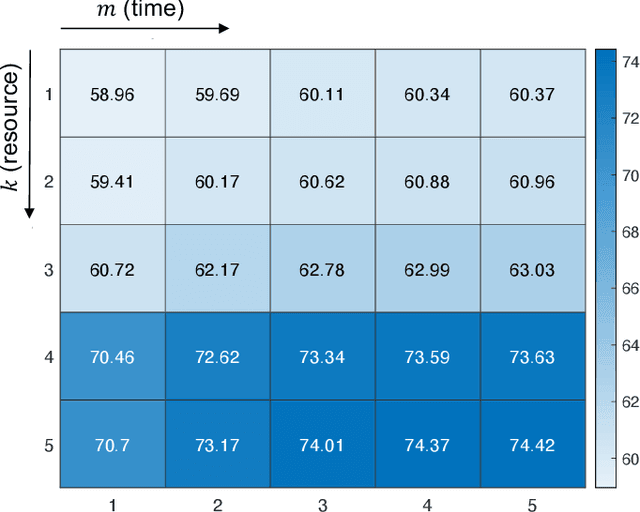
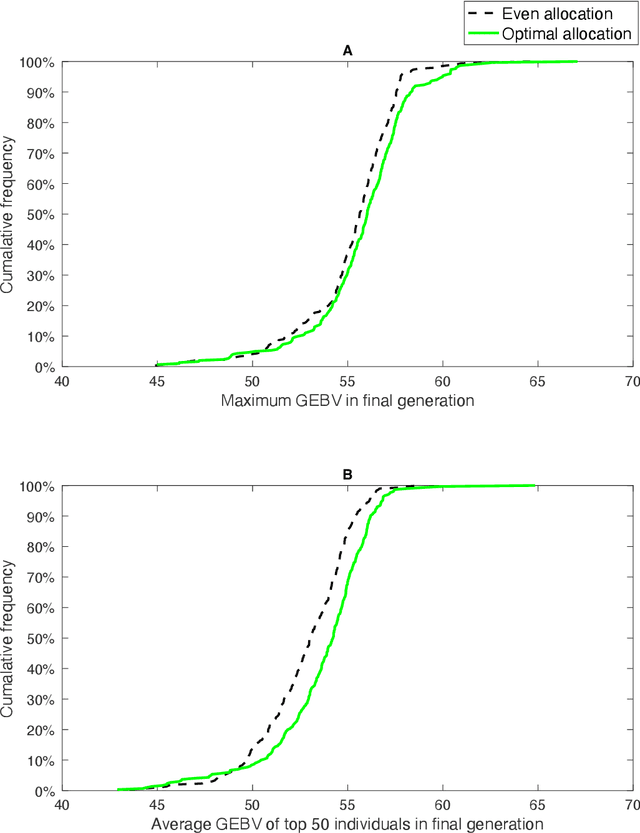
Genomic selection (GS) is a technique that plant breeders use to select individuals to mate and produce new generations of species. Allocation of resources is a key factor in GS. At each selection cycle, breeders are facing the choice of budget allocation to make crosses and produce the next generation of breeding parents. Inspired by recent advances in reinforcement learning for AI problems, we develop a reinforcement learning-based algorithm to automatically learn to allocate limited resources across different generations of breeding. We mathematically formulate the problem in the framework of Markov Decision Process (MDP) by defining state and action spaces. To avoid the explosion of the state space, an integer linear program is proposed that quantifies the trade-off between resources and time. Finally, we propose a value function approximation method to estimate the action-value function and then develop a greedy policy improvement technique to find the optimal resources. We demonstrate the effectiveness of the proposed method in enhancing genetic gain using a case study with realistic data.
Corn Yield Prediction with Ensemble CNN-DNN
May 29, 2021
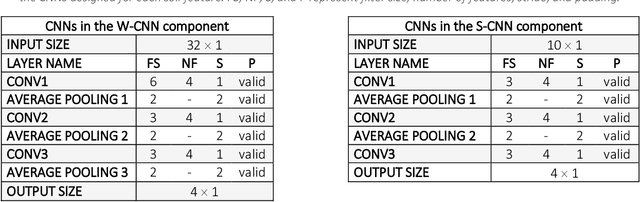
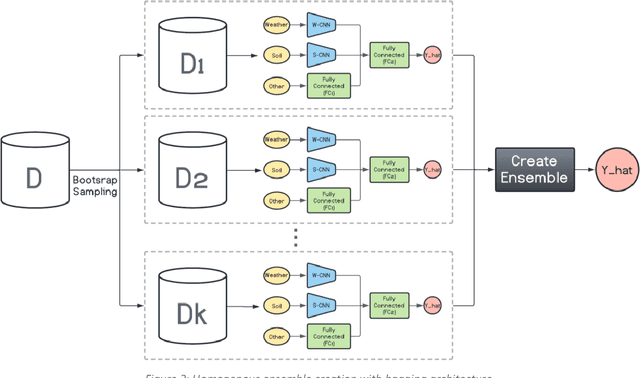
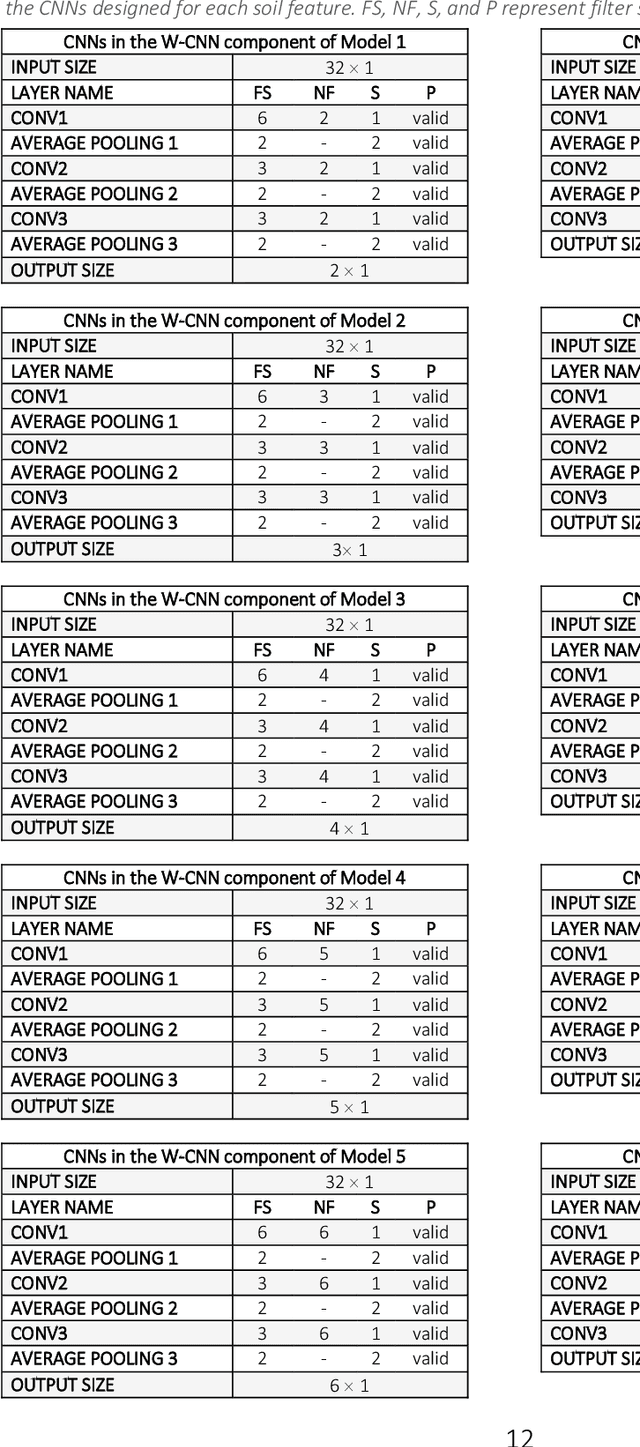
We investigate the predictive performance of two novel CNN-DNN machine learning ensemble models in predicting county-level corn yields across the US Corn Belt (12 states). The developed data set is a combination of management, environment, and historical corn yields from 1980-2019. Two scenarios for ensemble creation are considered: homogenous and heterogeneous ensembles. In homogenous ensembles, the base CNN-DNN models are all the same, but they are generated with a bagging procedure to ensure they exhibit a certain level of diversity. Heterogenous ensembles are created from different base CNN-DNN models which share the same architecture but have different levels of depth. Three types of ensemble creation methods were used to create several ensembles for either of the scenarios: Basic Ensemble Method (BEM), Generalized Ensemble Method (GEM), and stacked generalized ensembles. Results indicated that both designed ensemble types (heterogenous and homogenous) outperform the ensembles created from five individual ML models (linear regression, LASSO, random forest, XGBoost, and LightGBM). Furthermore, by introducing improvements over the heterogeneous ensembles, the homogenous ensembles provide the most accurate yield predictions across US Corn Belt states. This model could make 2019 yield predictions with a root mean square error of 866 kg/ha, equivalent to 8.5% relative root mean square, and could successfully explain about 77% of the spatio-temporal variation in the corn grain yields. The significant predictive power of this model can be leveraged for designing a reliable tool for corn yield prediction which will, in turn, assist agronomic decision-makers.
Improved Weighted Random Forest for Classification Problems
Sep 01, 2020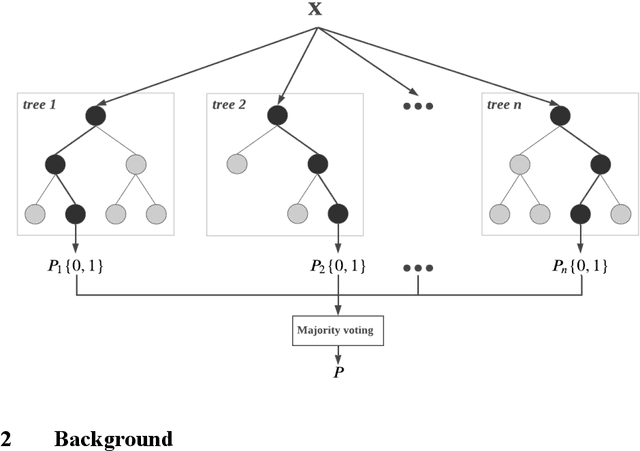



Several studies have shown that combining machine learning models in an appropriate way will introduce improvements in the individual predictions made by the base models. The key to make well-performing ensemble model is in the diversity of the base models. Of the most common solutions for introducing diversity into the decision trees are bagging and random forest. Bagging enhances the diversity by sampling with replacement and generating many training data sets, while random forest adds selecting a random number of features as well. This has made the random forest a winning candidate for many machine learning applications. However, assuming equal weights for all base decision trees does not seem reasonable as the randomization of sampling and input feature selection may lead to different levels of decision-making abilities across base decision trees. Therefore, we propose several algorithms that intend to modify the weighting strategy of regular random forest and consequently make better predictions. The designed weighting frameworks include optimal weighted random forest based on ac-curacy, optimal weighted random forest based on the area under the curve (AUC), performance-based weighted random forest, and several stacking-based weighted random forest models. The numerical results show that the proposed models are able to introduce significant improvements compared to regular random forest.
Coupling Machine Learning and Crop Modeling Improves Crop Yield Prediction in the US Corn Belt
Jul 28, 2020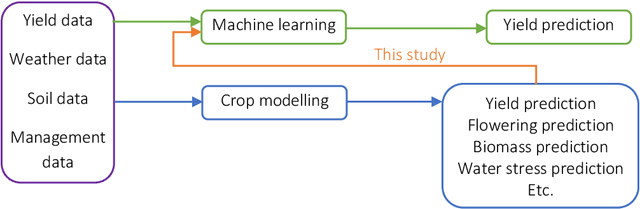

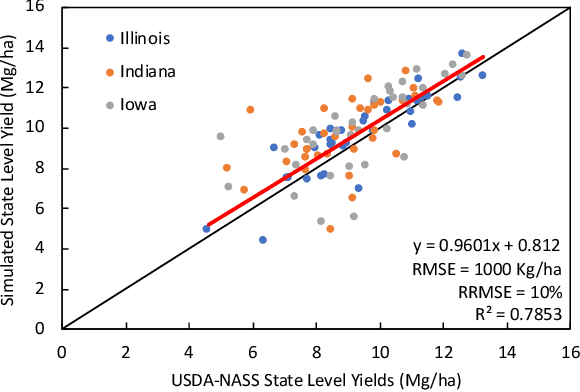
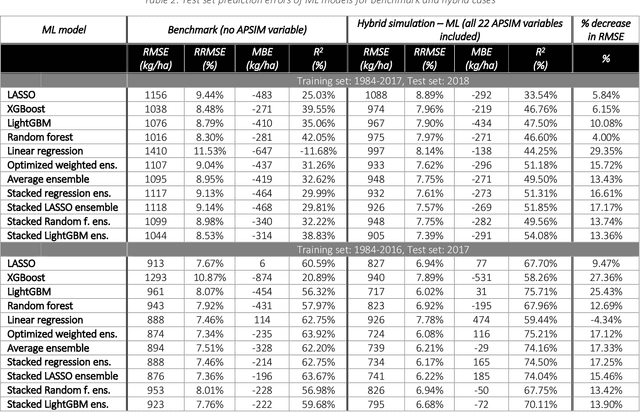
This study investigates whether coupling crop modeling and machine learning (ML) improves corn yield predictions in the US Corn Belt. The main objectives are to explore whether a hybrid approach (crop modeling + ML) would result in better predictions, investigate which combinations of hybrid models provide the most accurate predictions and determine the features from the crop modeling that are most effective to be integrated with ML for corn yield prediction. Five ML models and six ensemble models have been designed to address the research question. The results suggest that adding simulation crop model variables (APSIM) as input features to ML models can make a significant difference in the performance of ML models, and it can boost ML performance by up to 29%. Furthermore, we investigated partial inclusion of APSIM features in the ML prediction models, and we found that soil and weather-related APSIM variables are most influential on the ML predictions followed by crop-related and phenology-related variables. Finally, based on feature importance measure, it has been observed that simulated APSIM average drought stress and average water table depth during the growing season are the most important APSIM inputs to ML. This result indicates that weather information alone is not sufficient, and ML models need more hydrological inputs to make improved yield predictions.
A Hybrid Two-layer Feature Selection Method Using GeneticAlgorithm and Elastic Net
Jan 30, 2020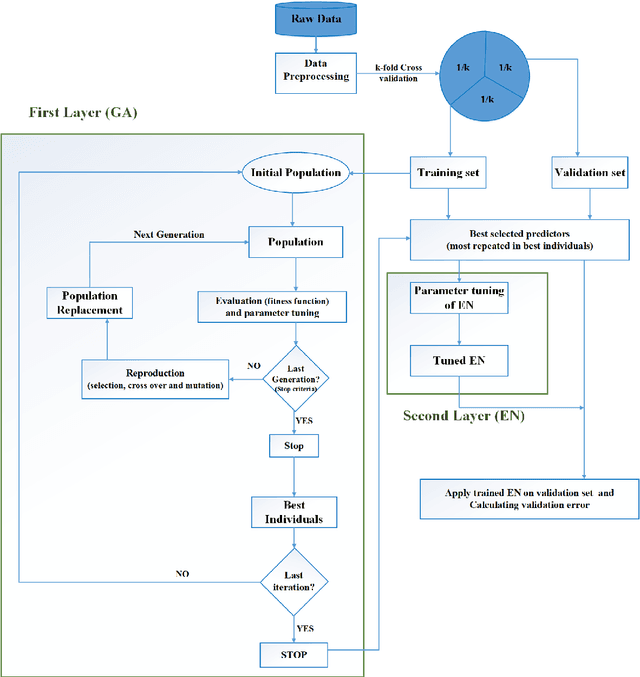



Feature selection, as a critical pre-processing step for machine learning, aims at determining representative predictors from a high-dimensional feature space dataset to improve the prediction accuracy. However, the increase in feature space dimensionality, comparing to the number of observations, poses a severe challenge to many existing feature selection methods with respect to computational efficiency and prediction performance. This paper presents a new hybrid two-layer feature selection approach that combines a wrapper and an embedded method in constructing an appropriate subset of predictors. In the first layer of the proposed method, the Genetic Algorithm(GA) has been adopted as a wrapper to search for the optimal subset of predictors, which aims to reduce the number of predictors and the prediction error. As one of the meta-heuristic approaches, GA is selected due to its computational efficiency; however, GAs do not guarantee the optimality. To address this issue, a second layer is added to the proposed method to eliminate any remaining redundant/irrelevant predictors to improve the prediction accuracy. Elastic Net(EN) has been selected as the embedded method in the second layer because of its flexibility in adjusting the penalty terms in regularization process and time efficiency. This hybrid two-layer approach has been applied on a Maize genetic dataset from NAM population, which consists of multiple subsets of datasets with different ratio of the number of predictors to the number of observations. The numerical results confirm the superiority of the proposed model.
Forecasting Corn Yield with Machine Learning Ensembles
Jan 18, 2020
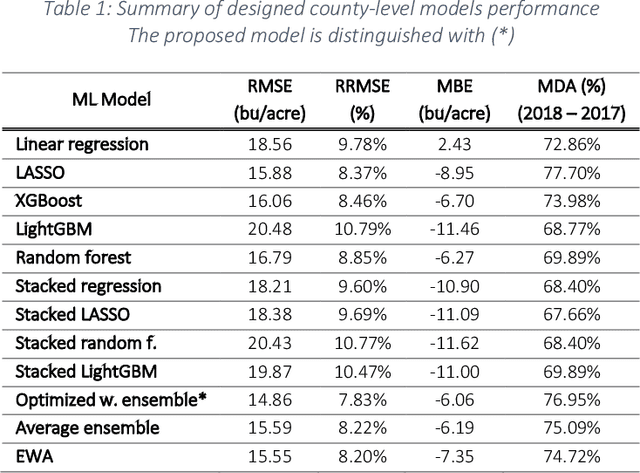


The emerge of new technologies to synthesize and analyze big data with high-performance computing, has increased our capacity to more accurately predict crop yields. Recent research has shown that Machine learning (ML) can provide reasonable predictions, faster, and with higher flexibility compared to simulation crop modeling. The earlier the prediction during the growing season the better, but this has not been thoroughly investigated as previous studies considered all data available to predict yields. This paper provides a machine learning based framework to forecast corn yields in three US Corn Belt states (Illinois, Indiana, and Iowa) considering complete and partial in-season weather knowledge. Several ensemble models are designed using blocked sequential procedure to generate out-of-bag predictions. The forecasts are made in county-level scale and aggregated for agricultural district, and state level scales. Results show that ensemble models based on weighted average of the base learners outperform individual models. Specifically, the proposed ensemble model could achieve best prediction accuracy (RRMSE of 7.8%) and least mean bias error (-6.06 bu/acre) compared to other developed models. Comparing our proposed model forecasts with the literature demonstrates the superiority of forecasts made by our proposed ensemble model. Results from the scenario of having partial in-season weather knowledge reveal that decent yield forecasts can be made as early as June 1st. To find the marginal effect of each input feature on the forecasts made by the proposed ensemble model, a methodology is suggested that is the basis for finding feature importance for the ensemble model. The findings suggest that weather features corresponding to weather in weeks 18-24 (May 1st to June 1st) are the most important input features.
Optimizing Ensemble Weights and Hyperparameters of Machine Learning Models for Regression Problems
Sep 11, 2019Aggregating multiple learners through an ensemble of models aims to make better predictions by capturing the underlying distribution more accurately. Different ensembling methods, such as bagging, boosting and stacking/blending, have been studied and adopted extensively in research and practice. While bagging and boosting intend to reduce variance and bias, respectively, blending approaches target both by finding the optimal way to combine base learners to find the best trade-off between bias and variance. In blending, ensembles are created from weighted averages of multiple base learners. In this study, a systematic approach is proposed to find the optimal weights to create these ensembles for bias-variance tradeoff using cross-validation for regression problems (Cross-validated Optimal Weighted Ensemble (COWE)). Furthermore, it is known that tuning hyperparameters of each base learner inside the ensemble weight optimization process can produce better performing ensembles. To this end, a nested algorithm based on bi-level optimization that considers tuning hyperparameters as well as finding the optimal weights to combine ensembles (Cross-validated Optimal Weighted Ensemble with Internally Tuned Hyperparameters (COWE-ITH)) was proposed. The algorithm is shown to be generalizable to real data sets though analyses with ten publicly available data sets. The prediction accuracies of COWE-ITH and COWE have been compared to base learners and the state-of-art ensemble methods. The results show that COWE-ITH outperforms other benchmarks as well as base learners in 9 out of 10 data sets.
Maize Yield and Nitrate Loss Prediction with Machine Learning Algorithms
Aug 29, 2019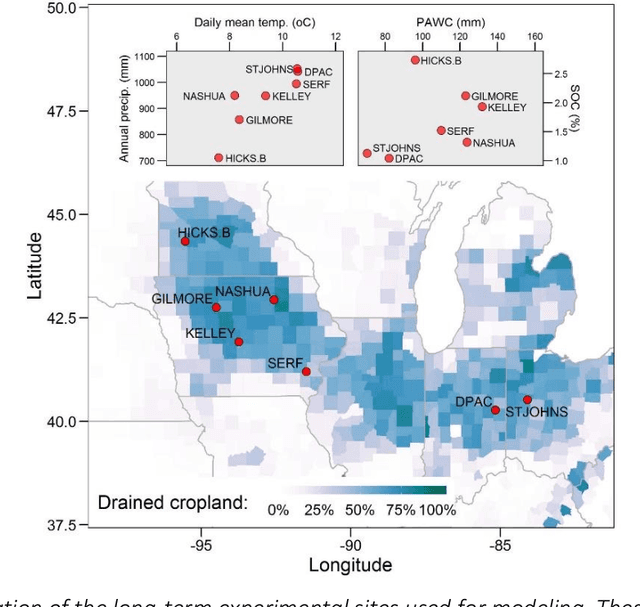
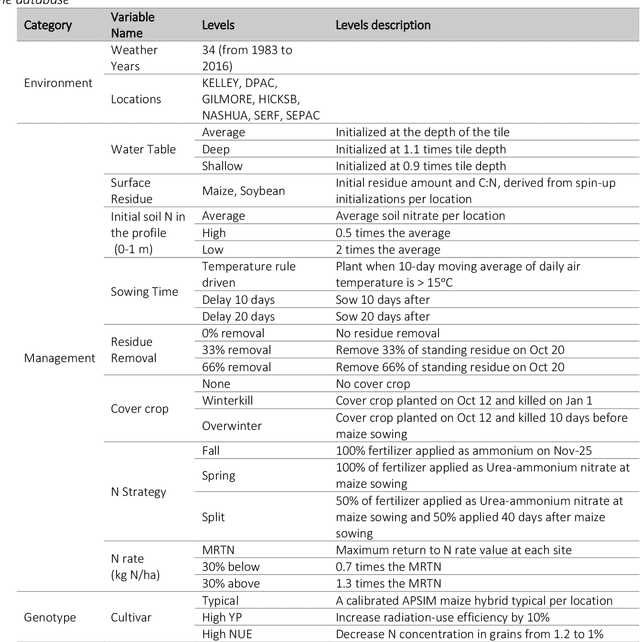
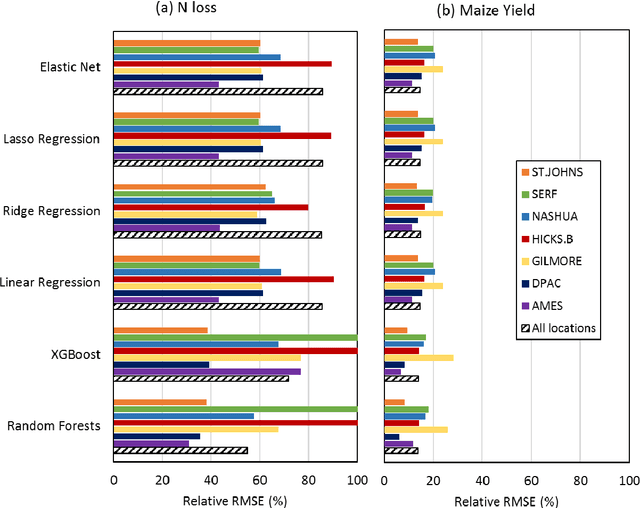
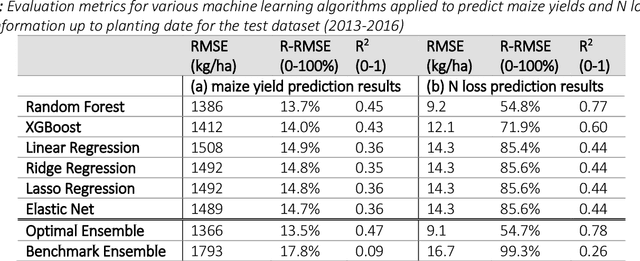
Pre-season prediction of crop production outcomes such as grain yields and N losses can provide insights to stakeholders when making decisions. Simulation models can assist in scenario planning, but their use is limited because of data requirements and long run times. Thus, there is a need for more computationally expedient approaches to scale up predictions. We evaluated the potential of five machine learning (ML) algorithms as meta-models for a cropping systems simulator (APSIM) to inform future decision-support tool development. We asked: 1) How well do ML meta-models predict maize yield and N losses using pre-season information? 2) How many data are needed to train ML algorithms to achieve acceptable predictions?; 3) Which input data variables are most important for accurate prediction?; and 4) Do ensembles of ML meta-models improve prediction? The simulated dataset included more than 3 million genotype, environment and management scenarios. Random forests most accurately predicted maize yield and N loss at planting time, with a RRMSE of 14% and 55%, respectively. ML meta-models reasonably reproduced simulated maize yields but not N loss. They also differed in their sensitivities to the size of the training dataset. Across all ML models, yield prediction error decreased by 10-40% as the training dataset increased from 0.5 to 1.8 million data points, whereas N loss prediction error showed no consistent pattern. ML models also differed in their sensitivities to input variables. Averaged across all ML models, weather conditions, soil properties, management information and initial conditions were roughly equally important when predicting yields. Modest prediction improvements resulted from ML ensembles. These results can help accelerate progress in coupling simulation models and ML toward developing dynamic decision support tools for pre-season management.