 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaize Yield and Nitrate Loss Prediction with Machine Learning Algorithms
Paper and Code
Aug 29, 2019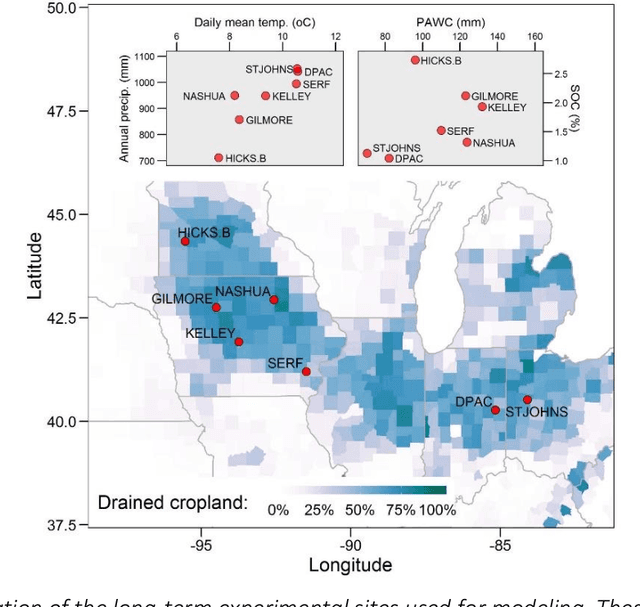
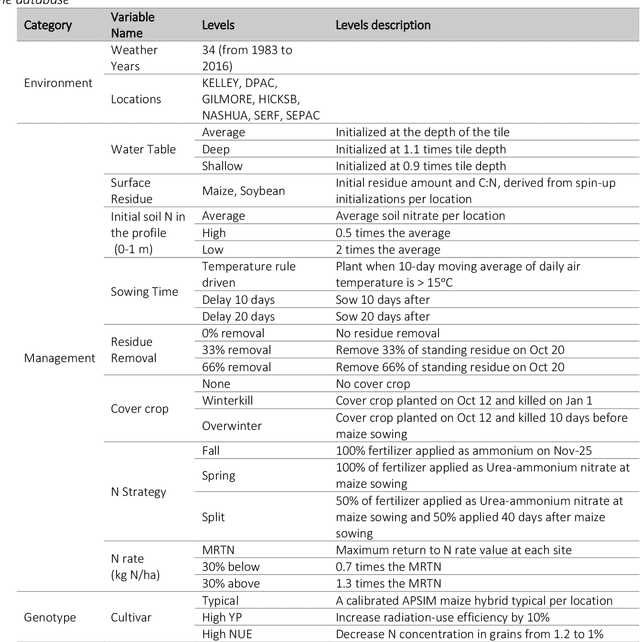
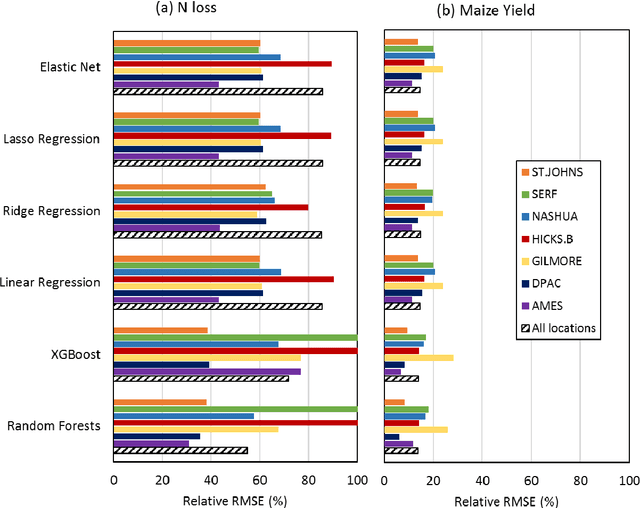
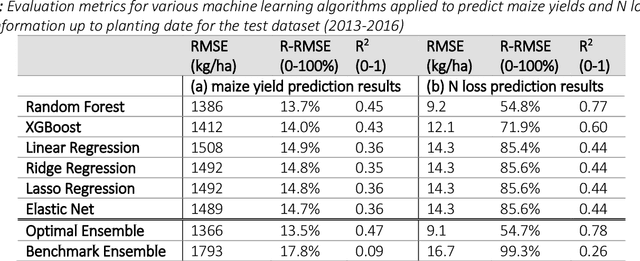
Pre-season prediction of crop production outcomes such as grain yields and N losses can provide insights to stakeholders when making decisions. Simulation models can assist in scenario planning, but their use is limited because of data requirements and long run times. Thus, there is a need for more computationally expedient approaches to scale up predictions. We evaluated the potential of five machine learning (ML) algorithms as meta-models for a cropping systems simulator (APSIM) to inform future decision-support tool development. We asked: 1) How well do ML meta-models predict maize yield and N losses using pre-season information? 2) How many data are needed to train ML algorithms to achieve acceptable predictions?; 3) Which input data variables are most important for accurate prediction?; and 4) Do ensembles of ML meta-models improve prediction? The simulated dataset included more than 3 million genotype, environment and management scenarios. Random forests most accurately predicted maize yield and N loss at planting time, with a RRMSE of 14% and 55%, respectively. ML meta-models reasonably reproduced simulated maize yields but not N loss. They also differed in their sensitivities to the size of the training dataset. Across all ML models, yield prediction error decreased by 10-40% as the training dataset increased from 0.5 to 1.8 million data points, whereas N loss prediction error showed no consistent pattern. ML models also differed in their sensitivities to input variables. Averaged across all ML models, weather conditions, soil properties, management information and initial conditions were roughly equally important when predicting yields. Modest prediction improvements resulted from ML ensembles. These results can help accelerate progress in coupling simulation models and ML toward developing dynamic decision support tools for pre-season management.