 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-GS: An Extensible Open Framework for Perceiving and Thinking via 3D Gaussian Splatting
Mar 12, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for novel view synthesis, subsequently extending into numerous spatial AI applications. However, most existing 3DGS methods operate in isolation, focusing on specific domains such as pose-free 3DGS, online SLAM, and semantic enrichment. In this paper, we introduce X-GS, an extensible open framework consisting of two major components: the X-GS-Perceiver, which unifies a broad range of 3DGS techniques to enable real-time online SLAM and distill semantic features; and the X-GS-Thinker, which interfaces with downstream multimodal models. In our implementation of the Perceiver, we integrate various 3DGS methods through three novel mechanisms: an online Vector Quantization (VQ) module, a GPU-accelerated grid-sampling scheme, and a highly parallelized pipeline design. The Thinker accommodates vision-language models and utilizes the resulting 3D semantic Gaussians, enabling downstream applications such as object detection, caption generation, and potentially embodied tasks. Experimental results on real-world datasets demonstrate the efficiency and newly unlocked multimodal capabilities of the X-GS framework.
3D-MoE: A Mixture-of-Experts Multi-modal LLM for 3D Vision and Pose Diffusion via Rectified Flow
Jan 28, 2025



3D vision and spatial reasoning have long been recognized as preferable for accurately perceiving our three-dimensional world, especially when compared with traditional visual reasoning based on 2D images. Due to the difficulties in collecting high-quality 3D data, research in this area has only recently gained momentum. With the advent of powerful large language models (LLMs), multi-modal LLMs for 3D vision have been developed over the past few years. However, most of these models focus primarily on the vision encoder for 3D data. In this paper, we propose converting existing densely activated LLMs into mixture-of-experts (MoE) models, which have proven effective for multi-modal data processing. In addition to leveraging these models' instruction-following capabilities, we further enable embodied task planning by attaching a diffusion head, Pose-DiT, that employs a novel rectified flow diffusion scheduler. Experimental results on 3D question answering and task-planning tasks demonstrate that our 3D-MoE framework achieves improved performance with fewer activated parameters.
Actra: Optimized Transformer Architecture for Vision-Language-Action Models in Robot Learning
Aug 02, 2024Vision-language-action models have gained significant attention for their ability to model trajectories in robot learning. However, most existing models rely on Transformer models with vanilla causal attention, which we find suboptimal for processing segmented multi-modal sequences. Additionally, the autoregressive generation approach falls short in generating multi-dimensional actions. In this paper, we introduce Actra, an optimized Transformer architecture featuring trajectory attention and learnable action queries, designed for effective encoding and decoding of segmented vision-language-action trajectories in robot imitation learning. Furthermore, we devise a multi-modal contrastive learning objective to explicitly align different modalities, complementing the primary behavior cloning objective. Through extensive experiments conducted across various environments, Actra exhibits substantial performance improvement when compared to state-of-the-art models in terms of generalizability, dexterity, and precision.
A Survey on Vision-Language-Action Models for Embodied AI
May 23, 2024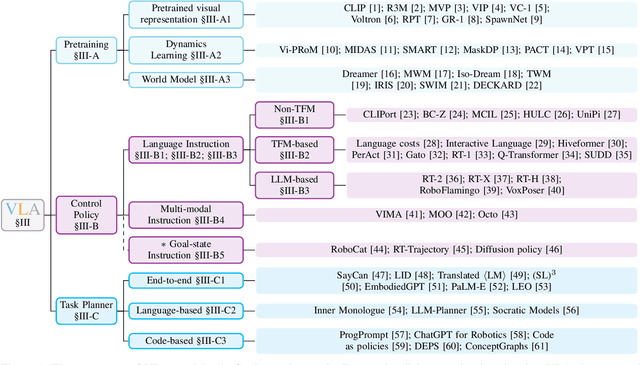
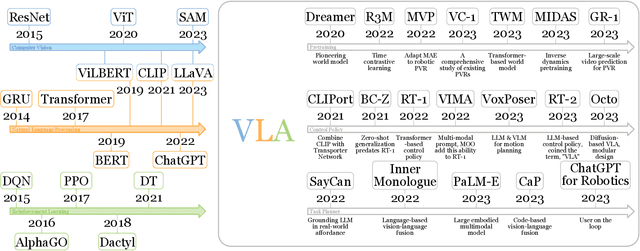


Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
VOLTA: Diverse and Controllable Question-Answer Pair Generation with Variational Mutual Information Maximizing Autoencoder
Jul 03, 2023
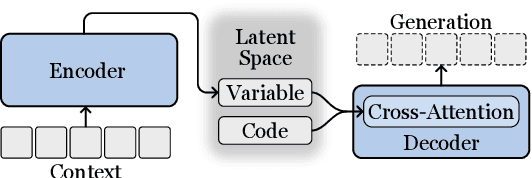

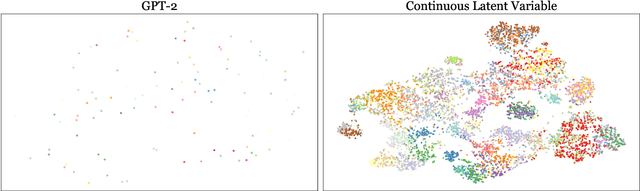
Previous question-answer pair generation methods aimed to produce fluent and meaningful question-answer pairs but tend to have poor diversity. Recent attempts addressing this issue suffer from either low model capacity or overcomplicated architecture. Furthermore, they overlooked the problem where the controllability of their models is highly dependent on the input. In this paper, we propose a model named VOLTA that enhances generative diversity by leveraging the Variational Autoencoder framework with a shared backbone network as its encoder and decoder. In addition, we propose adding InfoGAN-style latent codes to enable input-independent controllability over the generation process. We perform comprehensive experiments and the results show that our approach can significantly improve diversity and controllability over state-of-the-art models.
ConcreteGraph: A Data Augmentation Method Leveraging the Properties of Concept Relatedness Estimation
Jun 25, 2022
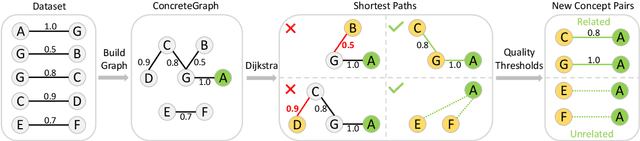
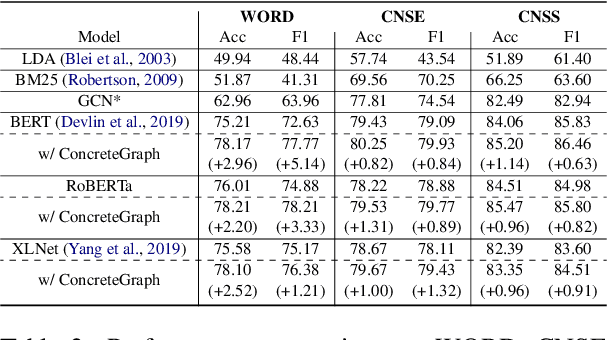
The concept relatedness estimation (CRE) task is to determine whether two given concepts are related. Although existing methods for the semantic textual similarity (STS) task can be easily adapted to this task, the CRE task has some unique properties that can be leveraged to augment the datasets for addressing its data scarcity problem. In this paper, we construct a graph named ConcreteGraph (Concept relatedness estimation Graph) to take advantage of the CRE properties. For the sampled new concept pairs from the ConcreteGraph, we add an additional step of filtering out the new concept pairs with low quality based on simple yet effective quality thresholding. We apply the ConcreteGraph data augmentation on three Transformer-based models to show its efficacy. Detailed ablation study for quality thresholding further shows that even a limited amount of high-quality data is more beneficial than a large quantity of unthresholded data. This paper is the first one to work on the WORD dataset and the proposed ConcreteGraph can boost the accuracy of the Transformers by more than 2%. All three Transformers, with the help of ConcreteGraph, can outperform the current state-of-theart method, Concept Interaction Graph (CIG), on the CNSE and CNSS datasets.
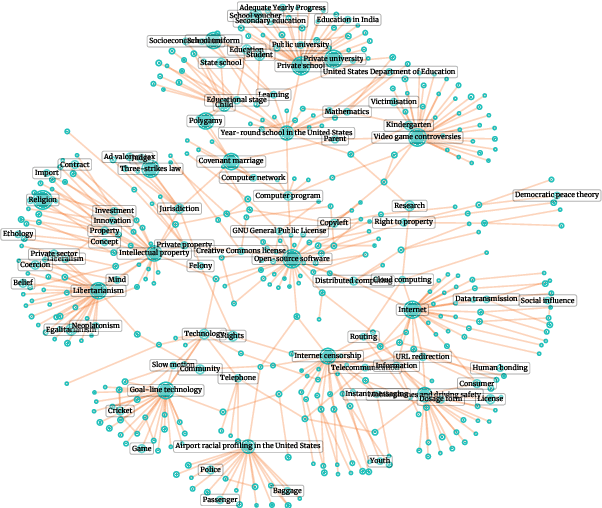
NLP in Human Rights Research -- Extracting Knowledge Graphs About Police and Army Units and Their Commanders
Jan 13, 2022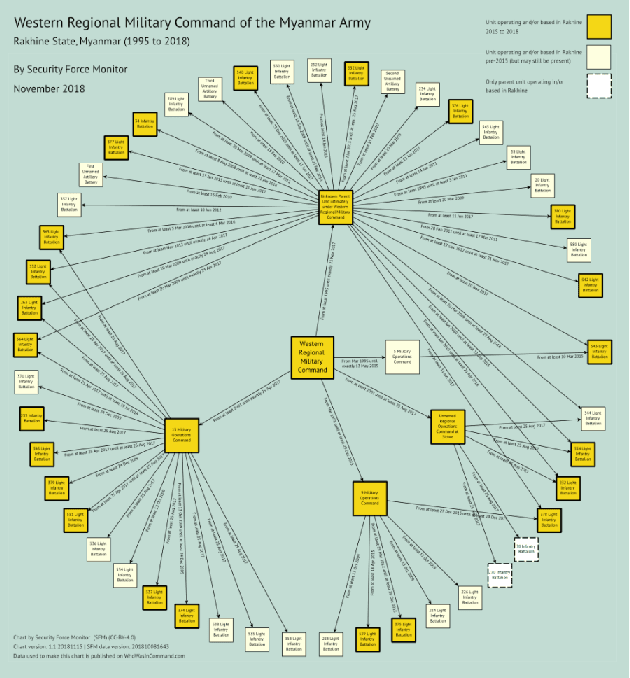
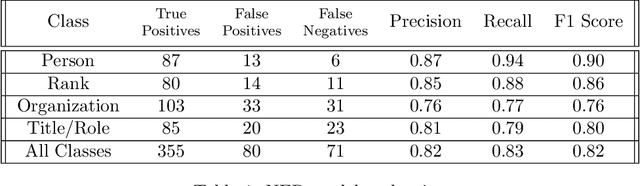
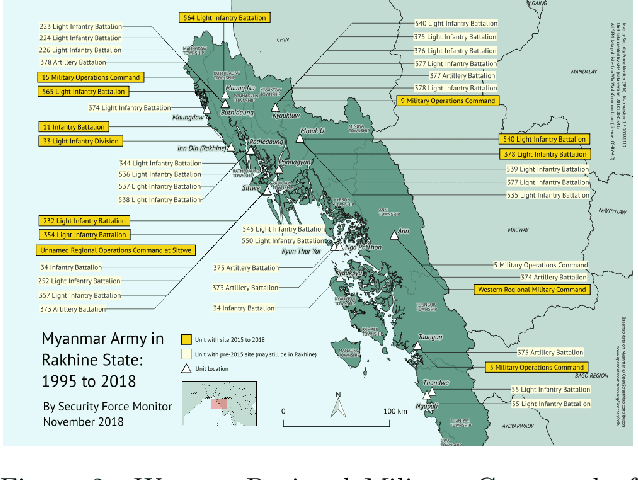

In this working paper we explore the use of an NLP system to assist the work of Security Force Monitor (SFM). SFM creates data about the organizational structure, command personnel and operations of police, army and other security forces, which assists human rights researchers, journalists and litigators in their work to help identify and bring to account specific units and personnel alleged to have committed abuses of human rights and international criminal law. This working paper presents an NLP system that extracts from English language news reports the names of security force units and the biographical details of their personnel, and infers the formal relationship between them. Published alongside this working paper are the system's code and training dataset. We find that the experimental NLP system performs the task at a fair to good level. Its performance is sufficient to justify further development into a live workflow that will give insight into whether its performance translates into savings in time and resource that would make it an effective technical intervention.