 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan 3D Vision-Language Models Truly Understand Natural Language?
Paper and Code
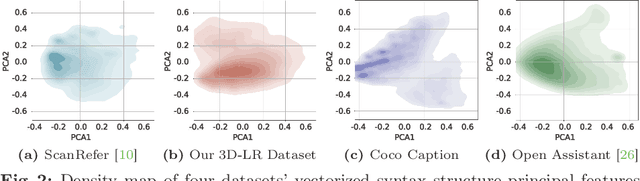
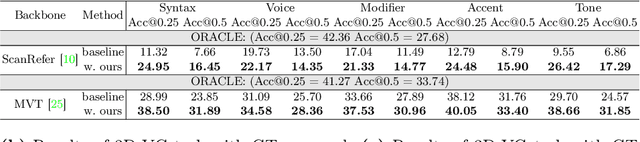
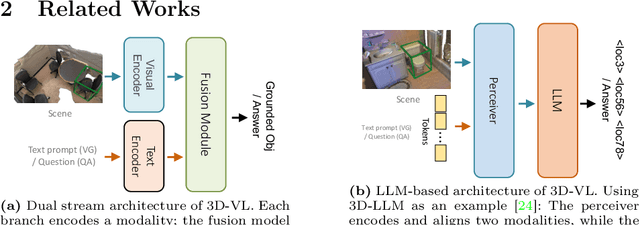
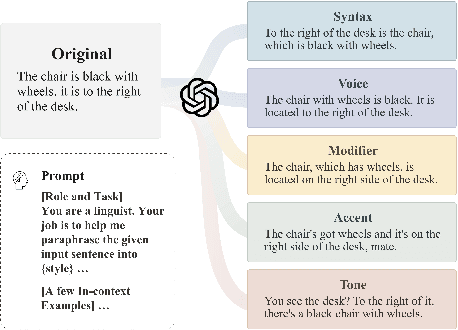
Rapid advancements in 3D vision-language (3D-VL) tasks have opened up new avenues for human interaction with embodied agents or robots using natural language. Despite this progress, we find a notable limitation: existing 3D-VL models exhibit sensitivity to the styles of language input, struggling to understand sentences with the same semantic meaning but written in different variants. This observation raises a critical question: Can 3D vision-language models truly understand natural language? To test the language understandability of 3D-VL models, we first propose a language robustness task for systematically assessing 3D-VL models across various tasks, benchmarking their performance when presented with different language style variants. Importantly, these variants are commonly encountered in applications requiring direct interaction with humans, such as embodied robotics, given the diversity and unpredictability of human language. We propose a 3D Language Robustness Dataset, designed based on the characteristics of human language, to facilitate the systematic study of robustness. Our comprehensive evaluation uncovers a significant drop in the performance of all existing models across various 3D-VL tasks. Even the state-of-the-art 3D-LLM fails to understand some variants of the same sentences. Further in-depth analysis suggests that the existing models have a fragile and biased fusion module, which stems from the low diversity of the existing dataset. Finally, we propose a training-free module driven by LLM, which improves language robustness. Datasets and code will be available at github.