 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Flow Networks for Personalized Multimedia Systems: A Case Study on Short Video Feeds
Aug 23, 2025Multimedia systems underpin modern digital interactions, facilitating seamless integration and optimization of resources across diverse multimedia applications. To meet growing personalization demands, multimedia systems must efficiently manage competing resource needs, adaptive content, and user-specific data handling. This paper introduces Generative Flow Networks (GFlowNets, GFNs) as a brave new framework for enabling personalized multimedia systems. By integrating multi-candidate generative modeling with flow-based principles, GFlowNets offer a scalable and flexible solution for enhancing user-specific multimedia experiences. To illustrate the effectiveness of GFlowNets, we focus on short video feeds, a multimedia application characterized by high personalization demands and significant resource constraints, as a case study. Our proposed GFlowNet-based personalized feeds algorithm demonstrates superior performance compared to traditional rule-based and reinforcement learning methods across critical metrics, including video quality, resource utilization efficiency, and delivery cost. Moreover, we propose a unified GFlowNet-based framework generalizable to other multimedia systems, highlighting its adaptability and wide-ranging applicability. These findings underscore the potential of GFlowNets to advance personalized multimedia systems by addressing complex optimization challenges and supporting sophisticated multimedia application scenarios.
Adversarial Feature Alignment: Avoid Catastrophic Forgetting in Incremental Task Lifelong Learning
Oct 24, 2019Human beings are able to master a variety of knowledge and skills with ongoing learning. By contrast, dramatic performance degradation is observed when new tasks are added to an existing neural network model. This phenomenon, termed as \emph{Catastrophic Forgetting}, is one of the major roadblocks that prevent deep neural networks from achieving human-level artificial intelligence. Several research efforts, e.g. \emph{Lifelong} or \emph{Continual} learning algorithms, have been proposed to tackle this problem. However, they either suffer from an accumulating drop in performance as the task sequence grows longer, or require to store an excessive amount of model parameters for historical memory, or cannot obtain competitive performance on the new tasks. In this paper, we focus on the incremental multi-task image classification scenario. Inspired by the learning process of human students, where they usually decompose complex tasks into easier goals, we propose an adversarial feature alignment method to avoid catastrophic forgetting. In our design, both the low-level visual features and high-level semantic features serve as soft targets and guide the training process in multiple stages, which provide sufficient supervised information of the old tasks and help to reduce forgetting. Due to the knowledge distillation and regularization phenomenons, the proposed method gains even better performance than finetuning on the new tasks, which makes it stand out from other methods. Extensive experiments in several typical lifelong learning scenarios demonstrate that our method outperforms the state-of-the-art methods in both accuracies on new tasks and performance preservation on old tasks.
Federated Learning with Unbiased Gradient Aggregation and Controllable Meta Updating
Oct 22, 2019



Federated Averaging (FedAvg) serves as the fundamental framework in Federated Learning (FL) settings. However, we argue that 1) the multiple steps of local updating will result in gradient biases and 2) there is an inconsistency between the target distribution and the optimization objectives following the training paradigm in FedAvg. To tackle these problems, we first propose an unbiased gradient aggregation algorithm with the keep-trace gradient descent and gradient evaluation strategy. Then we introduce a meta updating procedure with a controllable meta training set to provide a clear and consistent optimization objective. Experimental results demonstrate that the proposed methods outperform compared ones with various network architectures in both the IID and non-IID FL settings.
Federated Learning with Additional Mechanisms on Clients to Reduce Communication Costs
Sep 01, 2019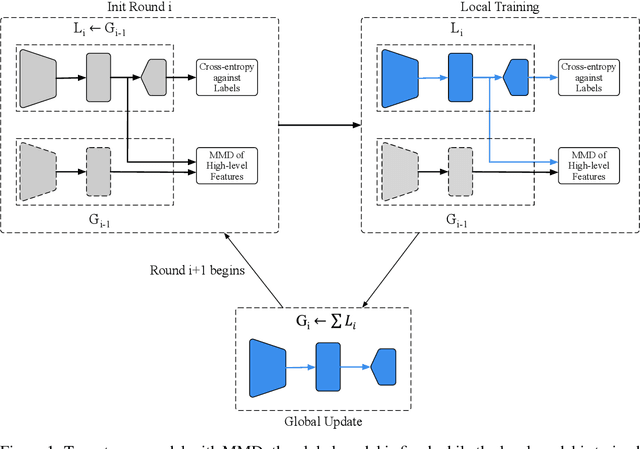
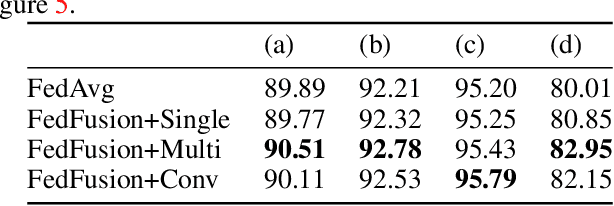
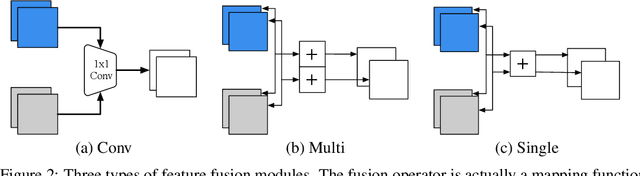
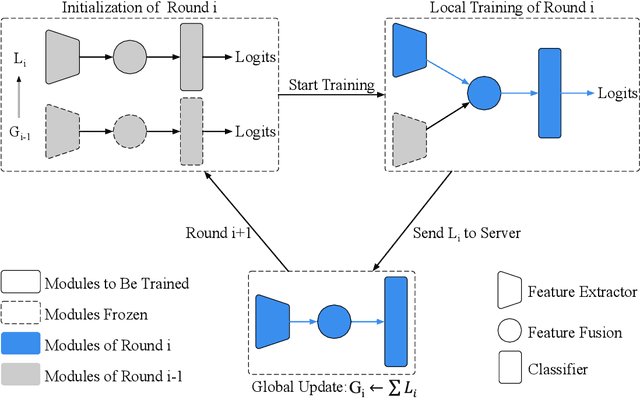
Federated learning (FL) enables on-device training over distributed networks consisting of a massive amount of modern smart devices, such as smartphones and IoT (Internet of Things) devices. However, the leading optimization algorithm in such settings, i.e., federated averaging (FedAvg), suffers from heavy communication costs and the inevitable performance drop, especially when the local data is distributed in a non-IID way. To alleviate this problem, we propose two potential solutions by introducing additional mechanisms to the on-device training. The first (FedMMD) is adopting a two-stream model with the MMD (Maximum Mean Discrepancy) constraint instead of a single model in vanilla FedAvg to be trained on devices. Experiments show that the proposed method outperforms baselines, especially in non-IID FL settings, with a reduction of more than 20% in required communication rounds. The second is FL with feature fusion (FedFusion). By aggregating the features from both the local and global models, we achieve higher accuracy at fewer communication costs. Furthermore, the feature fusion modules offer better initialization for newly incoming clients and thus speed up the process of convergence. Experiments in popular FL scenarios show that our FedFusion outperforms baselines in both accuracy and generalization ability while reducing the number of required communication rounds by more than 60%.
Comyco: Quality-Aware Adaptive Video Streaming via Imitation Learning
Aug 06, 2019



Learning-based Adaptive Bit Rate~(ABR) method, aiming to learn outstanding strategies without any presumptions, has become one of the research hotspots for adaptive streaming. However, it is still suffering from several issues, i.e., low sample efficiency and lack of awareness of the video quality information. In this paper, we propose Comyco, a video quality-aware ABR approach that enormously improves the learning-based methods by tackling the above issues. Comyco trains the policy via imitating expert trajectories given by the instant solver, which can not only avoid redundant exploration but also make better use of the collected samples. Meanwhile, Comyco attempts to pick the chunk with higher perceptual video qualities rather than video bitrates. To achieve this, we construct Comyco's neural network architecture, video datasets and QoE metrics with video quality features. Using trace-driven and real-world experiments, we demonstrate significant improvements of Comyco's sample efficiency in comparison to prior work, with 1700x improvements in terms of the number of samples required and 16x improvements on training time required. Moreover, results illustrate that Comyco outperforms previously proposed methods, with the improvements on average QoE of 7.5% - 16.79%. Especially, Comyco also surpasses state-of-the-art approach Pensieve by 7.37% on average video quality under the same rebuffering time.