 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Additional Mechanisms on Clients to Reduce Communication Costs
Paper and Code
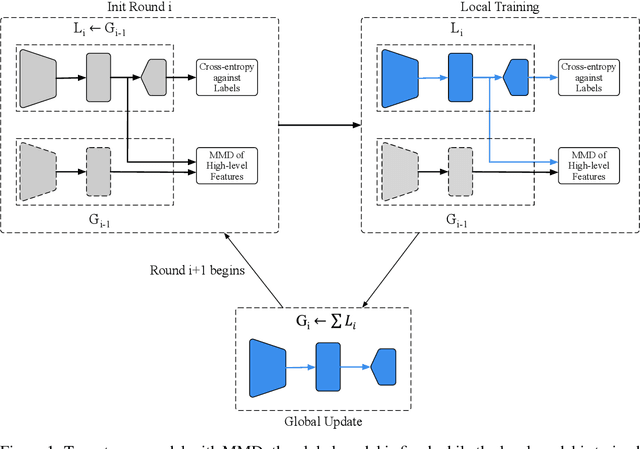
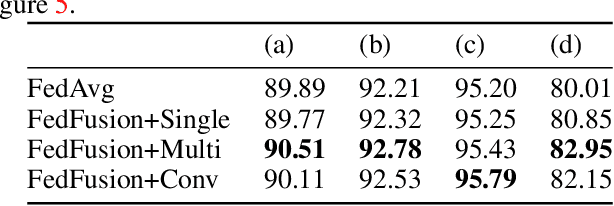
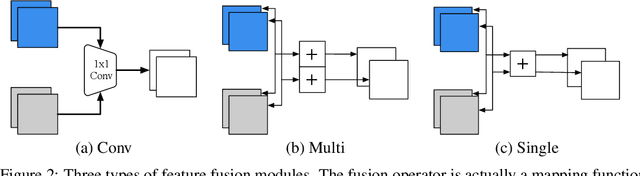
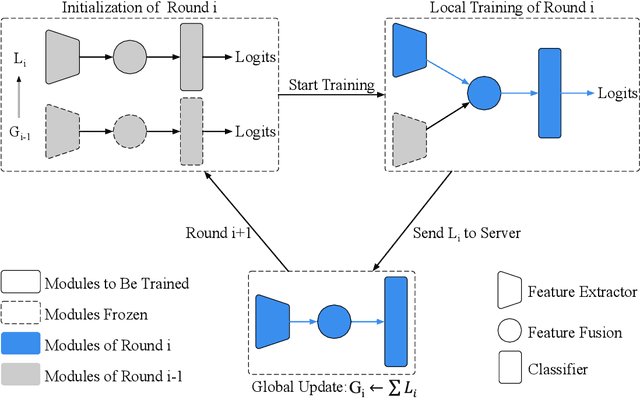
Federated learning (FL) enables on-device training over distributed networks consisting of a massive amount of modern smart devices, such as smartphones and IoT (Internet of Things) devices. However, the leading optimization algorithm in such settings, i.e., federated averaging (FedAvg), suffers from heavy communication costs and the inevitable performance drop, especially when the local data is distributed in a non-IID way. To alleviate this problem, we propose two potential solutions by introducing additional mechanisms to the on-device training. The first (FedMMD) is adopting a two-stream model with the MMD (Maximum Mean Discrepancy) constraint instead of a single model in vanilla FedAvg to be trained on devices. Experiments show that the proposed method outperforms baselines, especially in non-IID FL settings, with a reduction of more than 20% in required communication rounds. The second is FL with feature fusion (FedFusion). By aggregating the features from both the local and global models, we achieve higher accuracy at fewer communication costs. Furthermore, the feature fusion modules offer better initialization for newly incoming clients and thus speed up the process of convergence. Experiments in popular FL scenarios show that our FedFusion outperforms baselines in both accuracy and generalization ability while reducing the number of required communication rounds by more than 60%.