 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Consensus Prompting for Co-Salient Object Detection
Apr 19, 2025Existing co-salient object detection (CoSOD) methods generally employ a three-stage architecture (i.e., encoding, consensus extraction & dispersion, and prediction) along with a typical full fine-tuning paradigm. Although they yield certain benefits, they exhibit two notable limitations: 1) This architecture relies on encoded features to facilitate consensus extraction, but the meticulously extracted consensus does not provide timely guidance to the encoding stage. 2) This paradigm involves globally updating all parameters of the model, which is parameter-inefficient and hinders the effective representation of knowledge within the foundation model for this task. Therefore, in this paper, we propose an interaction-effective and parameter-efficient concise architecture for the CoSOD task, addressing two key limitations. It introduces, for the first time, a parameter-efficient prompt tuning paradigm and seamlessly embeds consensus into the prompts to formulate task-specific Visual Consensus Prompts (VCP). Our VCP aims to induce the frozen foundation model to perform better on CoSOD tasks by formulating task-specific visual consensus prompts with minimized tunable parameters. Concretely, the primary insight of the purposeful Consensus Prompt Generator (CPG) is to enforce limited tunable parameters to focus on co-salient representations and generate consensus prompts. The formulated Consensus Prompt Disperser (CPD) leverages consensus prompts to form task-specific visual consensus prompts, thereby arousing the powerful potential of pre-trained models in addressing CoSOD tasks. Extensive experiments demonstrate that our concise VCP outperforms 13 cutting-edge full fine-tuning models, achieving the new state of the art (with 6.8% improvement in F_m metrics on the most challenging CoCA dataset). Source code has been available at https://github.com/WJ-CV/VCP.
Joint Correcting and Refinement for Balanced Low-Light Image Enhancement
Sep 28, 2023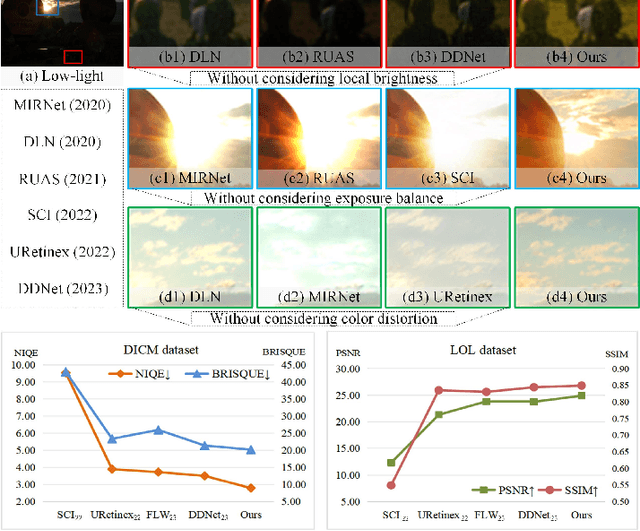

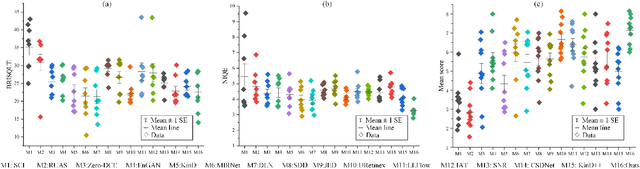

Low-light image enhancement tasks demand an appropriate balance among brightness, color, and illumination. While existing methods often focus on one aspect of the image without considering how to pay attention to this balance, which will cause problems of color distortion and overexposure etc. This seriously affects both human visual perception and the performance of high-level visual models. In this work, a novel synergistic structure is proposed which can balance brightness, color, and illumination more effectively. Specifically, the proposed method, so-called Joint Correcting and Refinement Network (JCRNet), which mainly consists of three stages to balance brightness, color, and illumination of enhancement. Stage 1: we utilize a basic encoder-decoder and local supervision mechanism to extract local information and more comprehensive details for enhancement. Stage 2: cross-stage feature transmission and spatial feature transformation further facilitate color correction and feature refinement. Stage 3: we employ a dynamic illumination adjustment approach to embed residuals between predicted and ground truth images into the model, adaptively adjusting illumination balance. Extensive experiments demonstrate that the proposed method exhibits comprehensive performance advantages over 21 state-of-the-art methods on 9 benchmark datasets. Furthermore, a more persuasive experiment has been conducted to validate our approach the effectiveness in downstream visual tasks (e.g., saliency detection). Compared to several enhancement models, the proposed method effectively improves the segmentation results and quantitative metrics of saliency detection. The source code will be available at https://github.com/woshiyll/JCRNet.