 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Correcting and Refinement for Balanced Low-Light Image Enhancement
Sep 28, 2023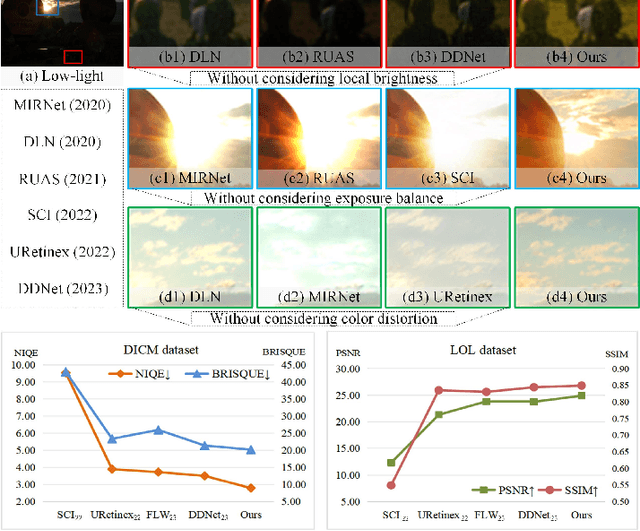

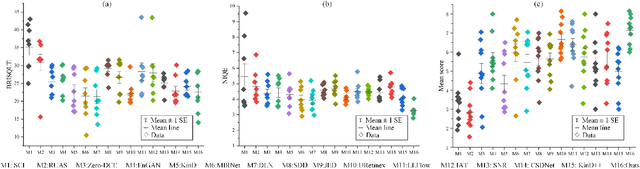

Low-light image enhancement tasks demand an appropriate balance among brightness, color, and illumination. While existing methods often focus on one aspect of the image without considering how to pay attention to this balance, which will cause problems of color distortion and overexposure etc. This seriously affects both human visual perception and the performance of high-level visual models. In this work, a novel synergistic structure is proposed which can balance brightness, color, and illumination more effectively. Specifically, the proposed method, so-called Joint Correcting and Refinement Network (JCRNet), which mainly consists of three stages to balance brightness, color, and illumination of enhancement. Stage 1: we utilize a basic encoder-decoder and local supervision mechanism to extract local information and more comprehensive details for enhancement. Stage 2: cross-stage feature transmission and spatial feature transformation further facilitate color correction and feature refinement. Stage 3: we employ a dynamic illumination adjustment approach to embed residuals between predicted and ground truth images into the model, adaptively adjusting illumination balance. Extensive experiments demonstrate that the proposed method exhibits comprehensive performance advantages over 21 state-of-the-art methods on 9 benchmark datasets. Furthermore, a more persuasive experiment has been conducted to validate our approach the effectiveness in downstream visual tasks (e.g., saliency detection). Compared to several enhancement models, the proposed method effectively improves the segmentation results and quantitative metrics of saliency detection. The source code will be available at https://github.com/woshiyll/JCRNet.
Natural Language Processing using Hadoop and KOSHIK
Aug 15, 2016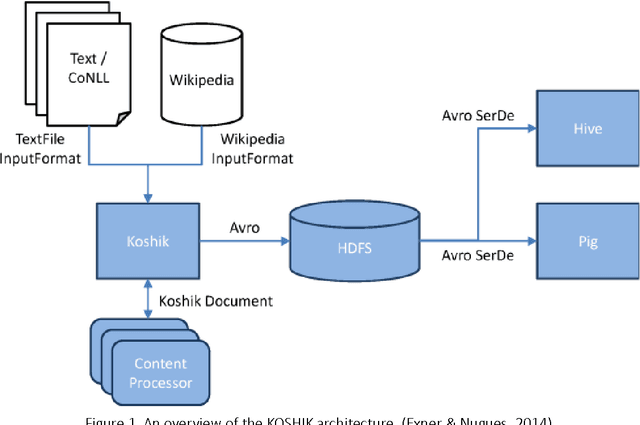
Natural language processing, as a data analytics related technology, is used widely in many research areas such as artificial intelligence, human language processing, and translation. At present, due to explosive growth of data, there are many challenges for natural language processing. Hadoop is one of the platforms that can process the large amount of data required for natural language processing. KOSHIK is one of the natural language processing architectures, and utilizes Hadoop and contains language processing components such as Stanford CoreNLP and OpenNLP. This study describes how to build a KOSHIK platform with the relevant tools, and provides the steps to analyze wiki data. Finally, it evaluates and discusses the advantages and disadvantages of the KOSHIK architecture, and gives recommendations on improving the processing performance.