 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAC-Net: A Region-based Deep Enhancing and Cropping Approach for Facial Action Unit Detection
Paper and Code
Feb 09, 2017
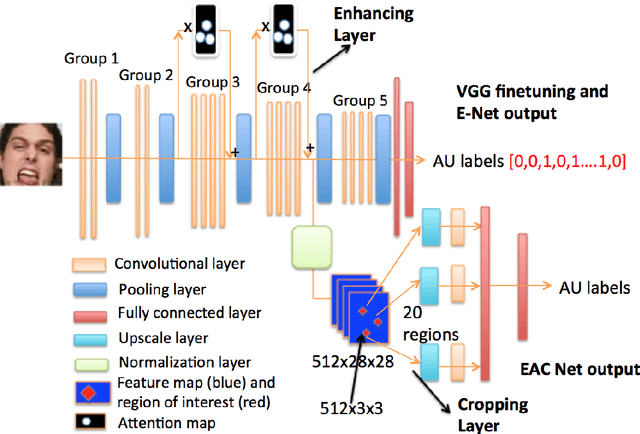
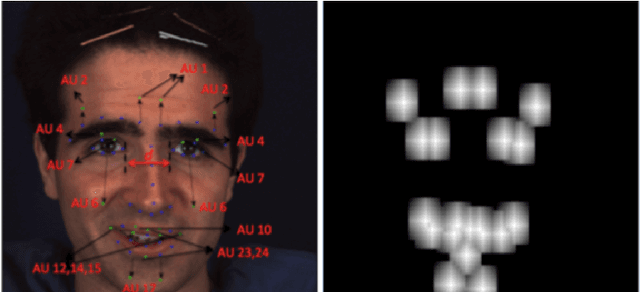
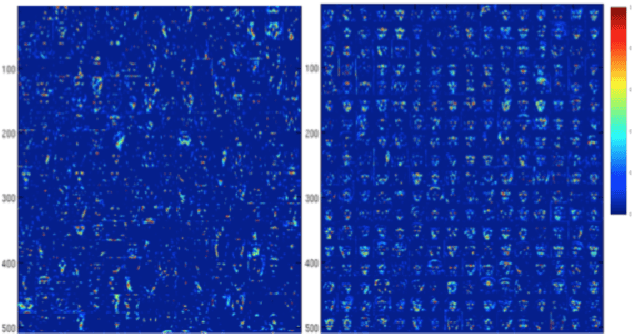
In this paper, we propose a deep learning based approach for facial action unit detection by enhancing and cropping the regions of interest. The approach is implemented by adding two novel nets (layers): the enhancing layers and the cropping layers, to a pretrained CNN model. For the enhancing layers, we designed an attention map based on facial landmark features and applied it to a pretrained neural network to conduct enhanced learning (The E-Net). For the cropping layers, we crop facial regions around the detected landmarks and design convolutional layers to learn deeper features for each facial region (C-Net). We then fuse the E-Net and the C-Net to obtain our Enhancing and Cropping (EAC) Net, which can learn both feature enhancing and region cropping functions. Our approach shows significant improvement in performance compared to the state-of-the-art methods applied to BP4D and DISFA AU datasets.