 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Fake News: A Survey on Identification and Mitigation Techniques
Jan 18, 2019



The proliferation of fake news on social media has opened up new directions of research for timely identification and containment of fake news, and mitigation of its widespread impact on public opinion. While much of the earlier research was focused on identification of fake news based on its contents or by exploiting users' engagements with the news on social media, there has been a rising interest in proactive intervention strategies to counter the spread of misinformation and its impact on society. In this survey, we describe the modern-day problem of fake news and, in particular, highlight the technical challenges associated with it. We discuss existing methods and techniques applicable to both identification and mitigation, with a focus on the significant advances in each method and their advantages and limitations. In addition, research has often been limited by the quality of existing datasets and their specific application contexts. To alleviate this problem, we comprehensively compile and summarize characteristic features of available datasets. Furthermore, we outline new directions of research to facilitate future development of effective and interdisciplinary solutions.
CSI: A Hybrid Deep Model for Fake News Detection
Sep 03, 2017



The topic of fake news has drawn attention both from the public and the academic communities. Such misinformation has the potential of affecting public opinion, providing an opportunity for malicious parties to manipulate the outcomes of public events such as elections. Because such high stakes are at play, automatically detecting fake news is an important, yet challenging problem that is not yet well understood. Nevertheless, there are three generally agreed upon characteristics of fake news: the text of an article, the user response it receives, and the source users promoting it. Existing work has largely focused on tailoring solutions to one particular characteristic which has limited their success and generality. In this work, we propose a model that combines all three characteristics for a more accurate and automated prediction. Specifically, we incorporate the behavior of both parties, users and articles, and the group behavior of users who propagate fake news. Motivated by the three characteristics, we propose a model called CSI which is composed of three modules: Capture, Score, and Integrate. The first module is based on the response and text; it uses a Recurrent Neural Network to capture the temporal pattern of user activity on a given article. The second module learns the source characteristic based on the behavior of users, and the two are integrated with the third module to classify an article as fake or not. Experimental analysis on real-world data demonstrates that CSI achieves higher accuracy than existing models, and extracts meaningful latent representations of both users and articles.
Matrix completion with queries
May 01, 2017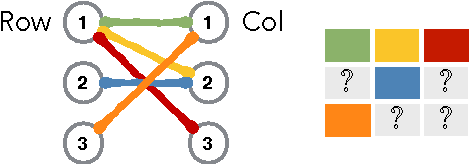

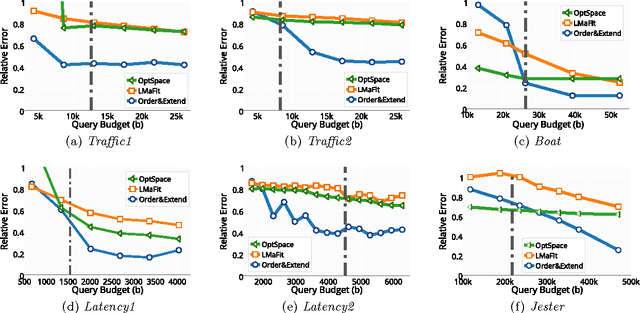
In many applications, e.g., recommender systems and traffic monitoring, the data comes in the form of a matrix that is only partially observed and low rank. A fundamental data-analysis task for these datasets is matrix completion, where the goal is to accurately infer the entries missing from the matrix. Even when the data satisfies the low-rank assumption, classical matrix-completion methods may output completions with significant error -- in that the reconstructed matrix differs significantly from the true underlying matrix. Often, this is due to the fact that the information contained in the observed entries is insufficient. In this work, we address this problem by proposing an active version of matrix completion, where queries can be made to the true underlying matrix. Subsequently, we design Order&Extend, which is the first algorithm to unify a matrix-completion approach and a querying strategy into a single algorithm. Order&Extend is able identify and alleviate insufficient information by judiciously querying a small number of additional entries. In an extensive experimental evaluation on real-world datasets, we demonstrate that our algorithm is efficient and is able to accurately reconstruct the true matrix while asking only a small number of queries.
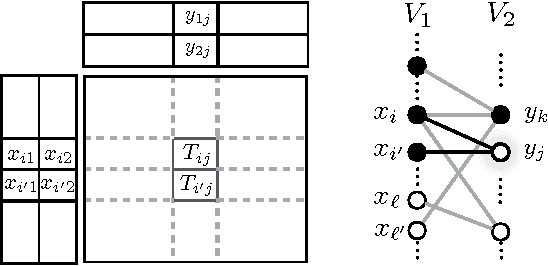
Targeted matrix completion
Apr 30, 2017
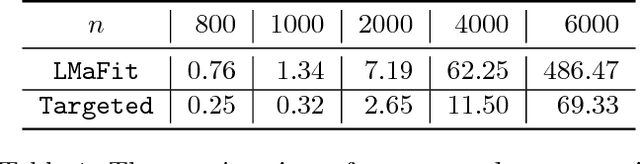
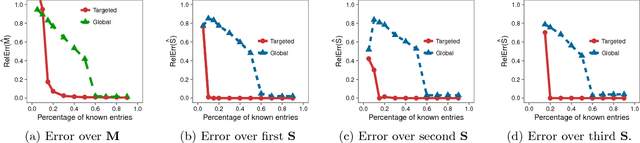
Matrix completion is a problem that arises in many data-analysis settings where the input consists of a partially-observed matrix (e.g., recommender systems, traffic matrix analysis etc.). Classical approaches to matrix completion assume that the input partially-observed matrix is low rank. The success of these methods depends on the number of observed entries and the rank of the matrix; the larger the rank, the more entries need to be observed in order to accurately complete the matrix. In this paper, we deal with matrices that are not necessarily low rank themselves, but rather they contain low-rank submatrices. We propose Targeted, which is a general framework for completing such matrices. In this framework, we first extract the low-rank submatrices and then apply a matrix-completion algorithm to these low-rank submatrices as well as the remainder matrix separately. Although for the completion itself we use state-of-the-art completion methods, our results demonstrate that Targeted achieves significantly smaller reconstruction errors than other classical matrix-completion methods. One of the key technical contributions of the paper lies in the identification of the low-rank submatrices from the input partially-observed matrices.