 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect to Know: An Internal-External Knowledge Self-Selection Framework for Domain-Specific Question Answering
Aug 21, 2025

Large Language Models (LLMs) perform well in general QA but often struggle in domain-specific scenarios. Retrieval-Augmented Generation (RAG) introduces external knowledge but suffers from hallucinations and latency due to noisy retrievals. Continued pretraining internalizes domain knowledge but is costly and lacks cross-domain flexibility. We attribute this challenge to the long-tail distribution of domain knowledge, which leaves partial yet useful internal knowledge underutilized. We further argue that knowledge acquisition should be progressive, mirroring human learning: first understanding concepts, then applying them to complex reasoning. To address this, we propose Selct2Know (S2K), a cost-effective framework that internalizes domain knowledge through an internal-external knowledge self-selection strategy and selective supervised fine-tuning. We also introduce a structured reasoning data generation pipeline and integrate GRPO to enhance reasoning ability. Experiments on medical, legal, and financial QA benchmarks show that S2K consistently outperforms existing methods and matches domain-pretrained LLMs with significantly lower cost.
RISE: Reasoning Enhancement via Iterative Self-Exploration in Multi-hop Question Answering
May 28, 2025Large Language Models (LLMs) excel in many areas but continue to face challenges with complex reasoning tasks, such as Multi-Hop Question Answering (MHQA). MHQA requires integrating evidence from diverse sources while managing intricate logical dependencies, often leads to errors in reasoning. Retrieval-Augmented Generation (RAG), widely employed in MHQA tasks, faces challenges in effectively filtering noisy data and retrieving all necessary evidence, thereby limiting its effectiveness in addressing MHQA challenges. To address these challenges, we propose RISE:Reasoning Enhancement via Iterative Self-Exploration, a novel framework designed to enhance models' reasoning capability through iterative self-exploration. Specifically, RISE involves three key steps in addressing MHQA tasks: question decomposition, retrieve-then-read, and self-critique. By leveraging continuous self-exploration, RISE identifies accurate reasoning paths, iteratively self-improving the model's capability to integrate evidence, maintain logical consistency, and enhance performance in MHQA tasks. Extensive experiments on multiple MHQA benchmarks demonstrate that RISE significantly improves reasoning accuracy and task performance.
Retrieving, Rethinking and Revising: The Chain-of-Verification Can Improve Retrieval Augmented Generation
Oct 08, 2024



Recent Retrieval Augmented Generation (RAG) aims to enhance Large Language Models (LLMs) by incorporating extensive knowledge retrieved from external sources. However, such approach encounters some challenges: Firstly, the original queries may not be suitable for precise retrieval, resulting in erroneous contextual knowledge; Secondly, the language model can easily generate inconsistent answer with external references due to their knowledge boundary limitation. To address these issues, we propose the chain-of-verification (CoV-RAG) to enhance the external retrieval correctness and internal generation consistency. Specifically, we integrate the verification module into the RAG, engaging in scoring, judgment, and rewriting. To correct external retrieval errors, CoV-RAG retrieves new knowledge using a revised query. To correct internal generation errors, we unify QA and verification tasks with a Chain-of-Thought (CoT) reasoning during training. Our comprehensive experiments across various LLMs demonstrate the effectiveness and adaptability compared with other strong baselines. Especially, our CoV-RAG can significantly surpass the state-of-the-art baselines using different LLM backbones.
Which Side Are You On? A Multi-task Dataset for End-to-End Argument Summarisation and Evaluation
Jun 06, 2024
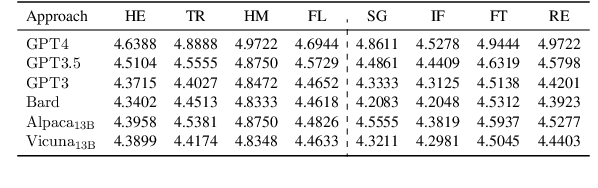
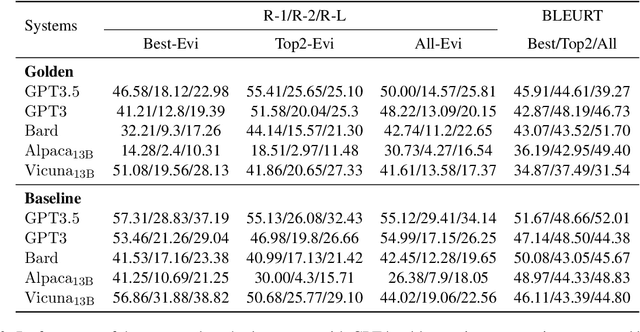
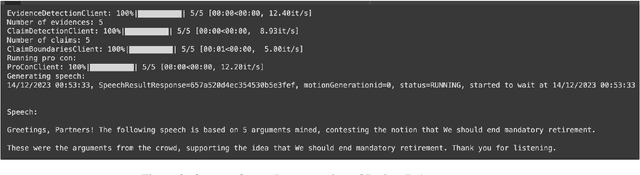
With the recent advances of large language models (LLMs), it is no longer infeasible to build an automated debate system that helps people to synthesise persuasive arguments. Previous work attempted this task by integrating multiple components. In our work, we introduce an argument mining dataset that captures the end-to-end process of preparing an argumentative essay for a debate, which covers the tasks of claim and evidence identification (Task 1 ED), evidence convincingness ranking (Task 2 ECR), argumentative essay summarisation and human preference ranking (Task 3 ASR) and metric learning for automated evaluation of resulting essays, based on human feedback along argument quality dimensions (Task 4 SQE). Our dataset contains 14k examples of claims that are fully annotated with the various properties supporting the aforementioned tasks. We evaluate multiple generative baselines for each of these tasks, including representative LLMs. We find, that while they show promising results on individual tasks in our benchmark, their end-to-end performance on all four tasks in succession deteriorates significantly, both in automated measures as well as in human-centred evaluation. This challenge presented by our proposed dataset motivates future research on end-to-end argument mining and summarisation. The repository of this project is available at https://github.com/HarrywillDr/ArgSum-Datatset
Network Inference from a Mixture of Diffusion Models for Fake News Mitigation
Aug 08, 2020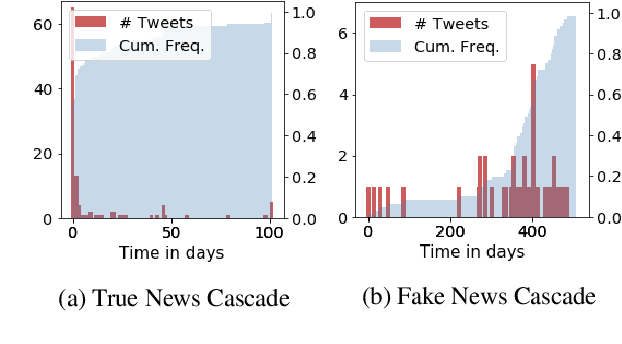
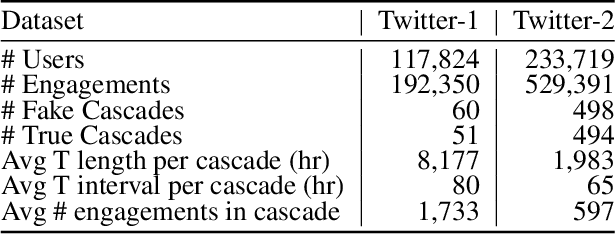
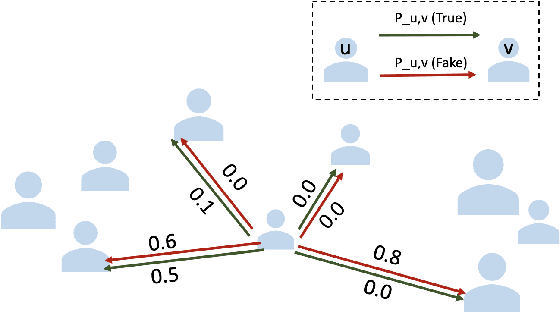
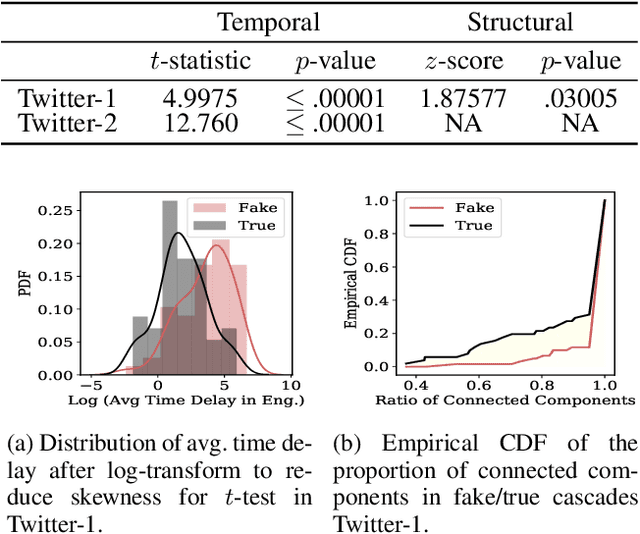
The dissemination of fake news intended to deceive people, influence public opinion and manipulate social outcomes, has become a pressing problem on social media. Moreover, information sharing on social media facilitates diffusion of viral information cascades. In this work, we focus on understanding and leveraging diffusion dynamics of false and legitimate contents in order to facilitate network interventions for fake news mitigation. We analyze real-world Twitter datasets comprising fake and true news cascades, to understand differences in diffusion dynamics and user behaviours with regards to fake and true contents. Based on the analysis, we model the diffusion as a mixture of Independent Cascade models (MIC) with parameters $\theta_T, \theta_F$ over the social network graph; and derive unsupervised inference techniques for parameter estimation of the diffusion mixture model from observed, unlabeled cascades. Users influential in the propagation of true and fake contents are identified using the inferred diffusion dynamics. Characteristics of the identified influential users reveal positive correlation between influential users identified for fake news and their relative appearance in fake news cascades. Identified influential users tend to be related to topics of more viral information cascades than less viral ones; and identified fake news influential users have relatively fewer counts of direct followers, compared to the true news influential users. Intervention analysis on nodes and edges demonstrates capacity of the inferred diffusion dynamics in supporting network interventions for mitigation.
mvn2vec: Preservation and Collaboration in Multi-View Network Embedding
Oct 30, 2018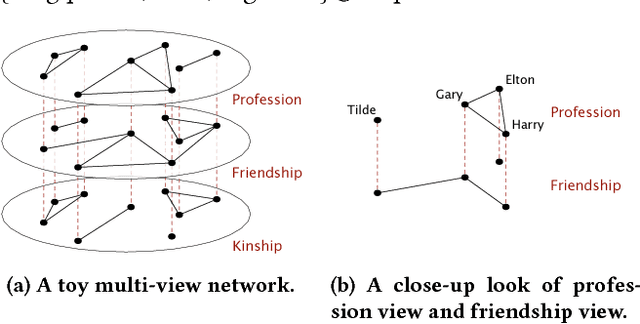

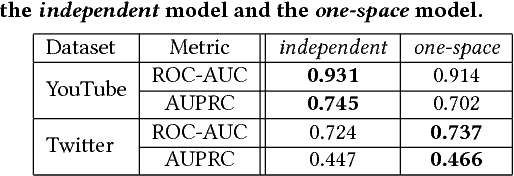
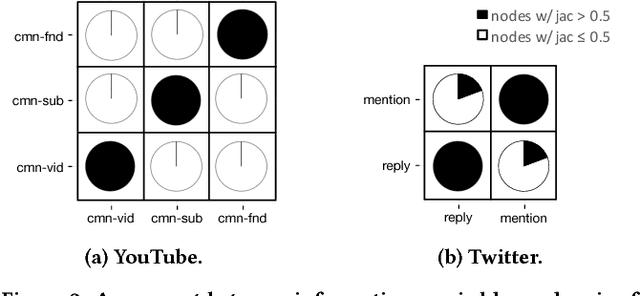
Multi-view networks are ubiquitous in real-world applications. In order to extract knowledge or business value, it is of interest to transform such networks into representations that are easily machine-actionable. Meanwhile, network embedding has emerged as an effective approach to generate distributed network representations. Therefore, we are motivated to study the problem of multi-view network embedding, with a focus on the characteristics that are specific and important in embedding this type of networks. In our practice of embedding real-world multi-view networks, we identify two such characteristics, which we refer to as preservation and collaboration. We then explore the feasibility of achieving better embedding quality by simultaneously modeling preservation and collaboration, and propose the mvn2vec algorithms. With experiments on a series of synthetic datasets, an internal Snapchat dataset, and two public datasets, we further confirm the presence and importance of preservation and collaboration. These experiments also demonstrate that better embedding can be obtained by simultaneously modeling the two characteristics, while not over-complicating the model or requiring additional supervision.
Learning Influence Functions from Incomplete Observations
Nov 07, 2016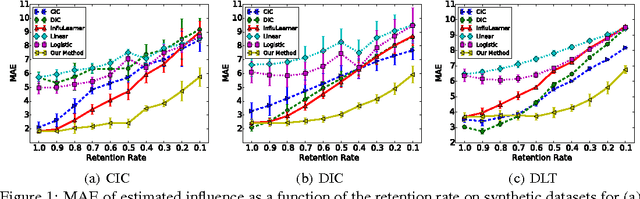
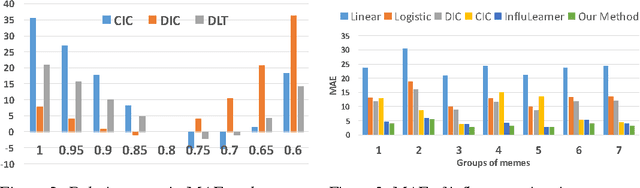
We study the problem of learning influence functions under incomplete observations of node activations. Incomplete observations are a major concern as most (online and real-world) social networks are not fully observable. We establish both proper and improper PAC learnability of influence functions under randomly missing observations. Proper PAC learnability under the Discrete-Time Linear Threshold (DLT) and Discrete-Time Independent Cascade (DIC) models is established by reducing incomplete observations to complete observations in a modified graph. Our improper PAC learnability result applies for the DLT and DIC models as well as the Continuous-Time Independent Cascade (CIC) model. It is based on a parametrization in terms of reachability features, and also gives rise to an efficient and practical heuristic. Experiments on synthetic and real-world datasets demonstrate the ability of our method to compensate even for a fairly large fraction of missing observations.
Learning and Optimization with Submodular Functions
May 07, 2015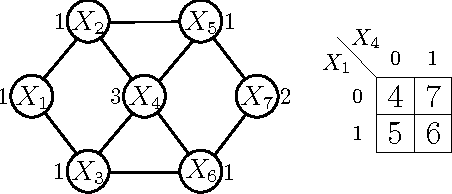
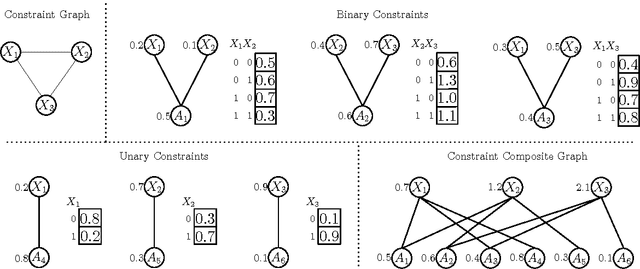
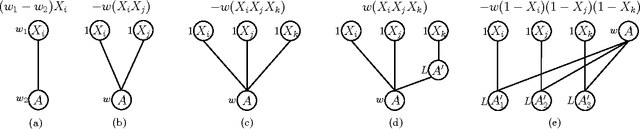
In many naturally occurring optimization problems one needs to ensure that the definition of the optimization problem lends itself to solutions that are tractable to compute. In cases where exact solutions cannot be computed tractably, it is beneficial to have strong guarantees on the tractable approximate solutions. In order operate under these criterion most optimization problems are cast under the umbrella of convexity or submodularity. In this report we will study design and optimization over a common class of functions called submodular functions. Set functions, and specifically submodular set functions, characterize a wide variety of naturally occurring optimization problems, and the property of submodularity of set functions has deep theoretical consequences with wide ranging applications. Informally, the property of submodularity of set functions concerns the intuitive "principle of diminishing returns. This property states that adding an element to a smaller set has more value than adding it to a larger set. Common examples of submodular monotone functions are entropies, concave functions of cardinality, and matroid rank functions; non-monotone examples include graph cuts, network flows, and mutual information. In this paper we will review the formal definition of submodularity; the optimization of submodular functions, both maximization and minimization; and finally discuss some applications in relation to learning and reasoning using submodular functions.
Model Selection for Topic Models via Spectral Decomposition
Feb 17, 2015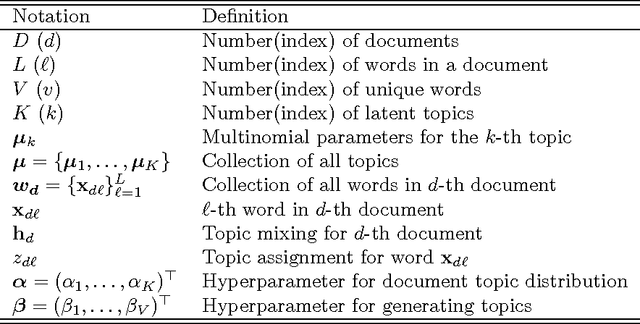
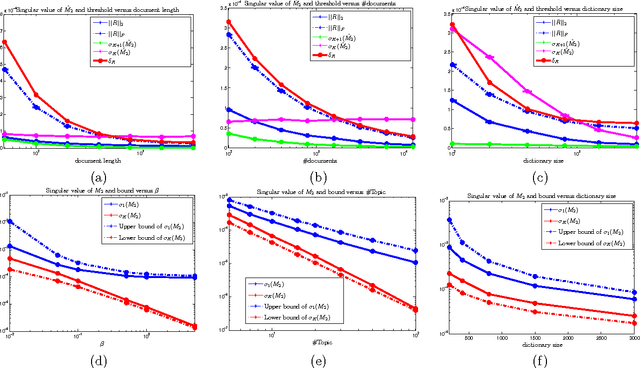
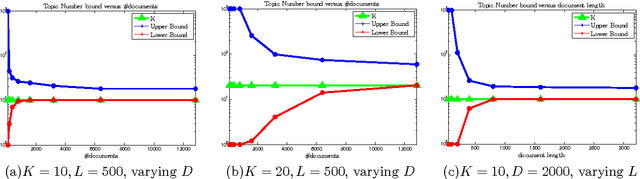
Topic models have achieved significant successes in analyzing large-scale text corpus. In practical applications, we are always confronted with the challenge of model selection, i.e., how to appropriately set the number of topics. Following recent advances in topic model inference via tensor decomposition, we make a first attempt to provide theoretical analysis on model selection in latent Dirichlet allocation. Under mild conditions, we derive the upper bound and lower bound on the number of topics given a text collection of finite size. Experimental results demonstrate that our bounds are accurate and tight. Furthermore, using Gaussian mixture model as an example, we show that our methodology can be easily generalized to model selection analysis for other latent models.
GLAD: Group Anomaly Detection in Social Media Analysis- Extended Abstract
Oct 07, 2014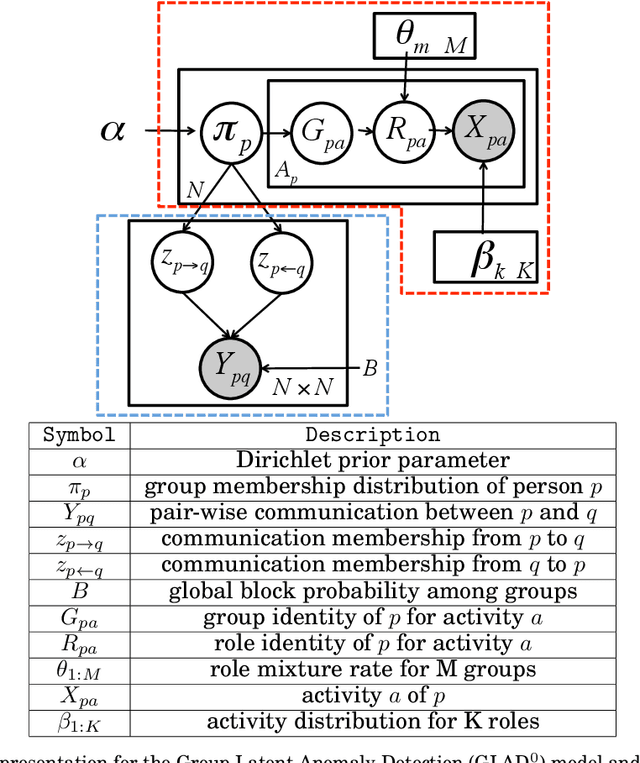
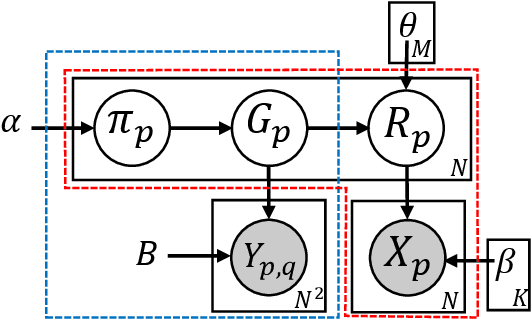
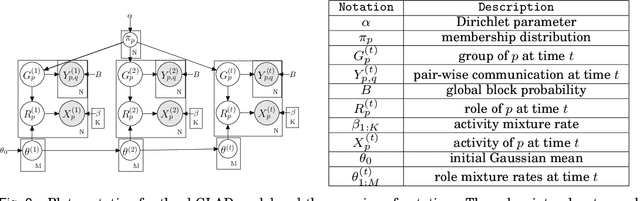
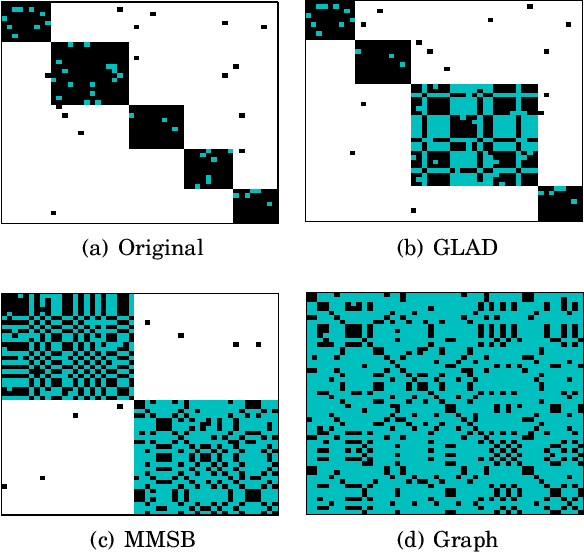
Traditional anomaly detection on social media mostly focuses on individual point anomalies while anomalous phenomena usually occur in groups. Therefore it is valuable to study the collective behavior of individuals and detect group anomalies. Existing group anomaly detection approaches rely on the assumption that the groups are known, which can hardly be true in real world social media applications. In this paper, we take a generative approach by proposing a hierarchical Bayes model: Group Latent Anomaly Detection (GLAD) model. GLAD takes both pair-wise and point-wise data as input, automatically infers the groups and detects group anomalies simultaneously. To account for the dynamic properties of the social media data, we further generalize GLAD to its dynamic extension d-GLAD. We conduct extensive experiments to evaluate our models on both synthetic and real world datasets. The empirical results demonstrate that our approach is effective and robust in discovering latent groups and detecting group anomalies.