 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Robust: Task Sampling with Posterior and Diversity Synergies for Adaptive Decision-Makers in Randomized Environments
Apr 27, 2025Task robust adaptation is a long-standing pursuit in sequential decision-making. Some risk-averse strategies, e.g., the conditional value-at-risk principle, are incorporated in domain randomization or meta reinforcement learning to prioritize difficult tasks in optimization, which demand costly intensive evaluations. The efficiency issue prompts the development of robust active task sampling to train adaptive policies, where risk-predictive models are used to surrogate policy evaluation. This work characterizes the optimization pipeline of robust active task sampling as a Markov decision process, posits theoretical and practical insights, and constitutes robustness concepts in risk-averse scenarios. Importantly, we propose an easy-to-implement method, referred to as Posterior and Diversity Synergized Task Sampling (PDTS), to accommodate fast and robust sequential decision-making. Extensive experiments show that PDTS unlocks the potential of robust active task sampling, significantly improves the zero-shot and few-shot adaptation robustness in challenging tasks, and even accelerates the learning process under certain scenarios. Our project website is at https://thu-rllab.github.io/PDTS_project_page.
VLPG-Nav: Object Navigation Using Visual Language Pose Graph and Object Localization Probability Maps
Aug 15, 2024



We present VLPG-Nav, a visual language navigation method for guiding robots to specified objects within household scenes. Unlike existing methods primarily focused on navigating the robot toward objects, our approach considers the additional challenge of centering the object within the robot's camera view. Our method builds a visual language pose graph (VLPG) that functions as a spatial map of VL embeddings. Given an open vocabulary object query, we plan a viewpoint for object navigation using the VLPG. Despite navigating to the viewpoint, real-world challenges like object occlusion, displacement, and the robot's localization error can prevent visibility. We build an object localization probability map that leverages the robot's current observations and prior VLPG. When the object isn't visible, the probability map is updated and an alternate viewpoint is computed. In addition, we propose an object-centering formulation that locally adjusts the robot's pose to center the object in the camera view. We evaluate the effectiveness of our approach through simulations and real-world experiments, evaluating its ability to successfully view and center the object within the camera field of view. VLPG-Nav demonstrates improved performance in locating the object, navigating around occlusions, and centering the object within the robot's camera view, outperforming the selected baselines in the evaluation metrics.
Episodic Multi-Task Learning with Heterogeneous Neural Processes
Oct 28, 2023This paper focuses on the data-insufficiency problem in multi-task learning within an episodic training setup. Specifically, we explore the potential of heterogeneous information across tasks and meta-knowledge among episodes to effectively tackle each task with limited data. Existing meta-learning methods often fail to take advantage of crucial heterogeneous information in a single episode, while multi-task learning models neglect reusing experience from earlier episodes. To address the problem of insufficient data, we develop Heterogeneous Neural Processes (HNPs) for the episodic multi-task setup. Within the framework of hierarchical Bayes, HNPs effectively capitalize on prior experiences as meta-knowledge and capture task-relatedness among heterogeneous tasks, mitigating data-insufficiency. Meanwhile, transformer-structured inference modules are designed to enable efficient inferences toward meta-knowledge and task-relatedness. In this way, HNPs can learn more powerful functional priors for adapting to novel heterogeneous tasks in each meta-test episode. Experimental results show the superior performance of the proposed HNPs over typical baselines, and ablation studies verify the effectiveness of the designed inference modules.
Incentive-Aware Recommender Systems in Two-Sided Markets
Nov 23, 2022Online platforms in the Internet Economy commonly incorporate recommender systems that recommend arms (e.g., products) to agents (e.g., users). In such platforms, a myopic agent has a natural incentive to exploit, by choosing the best product given the current information rather than to explore various alternatives to collect information that will be used for other agents. We propose a novel recommender system that respects agents' incentives and enjoys asymptotically optimal performances expressed by the regret in repeated games. We model such an incentive-aware recommender system as a multi-agent bandit problem in a two-sided market which is equipped with an incentive constraint induced by agents' opportunity costs. If the opportunity costs are known to the principal, we show that there exists an incentive-compatible recommendation policy, which pools recommendations across a genuinely good arm and an unknown arm via a randomized and adaptive approach. On the other hand, if the opportunity costs are unknown to the principal, we propose a policy that randomly pools recommendations across all arms and uses each arm's cumulative loss as feedback for exploration. We show that both policies also satisfy an ex-post fairness criterion, which protects agents from over-exploitation.
GLAD: Group Anomaly Detection in Social Media Analysis- Extended Abstract
Oct 07, 2014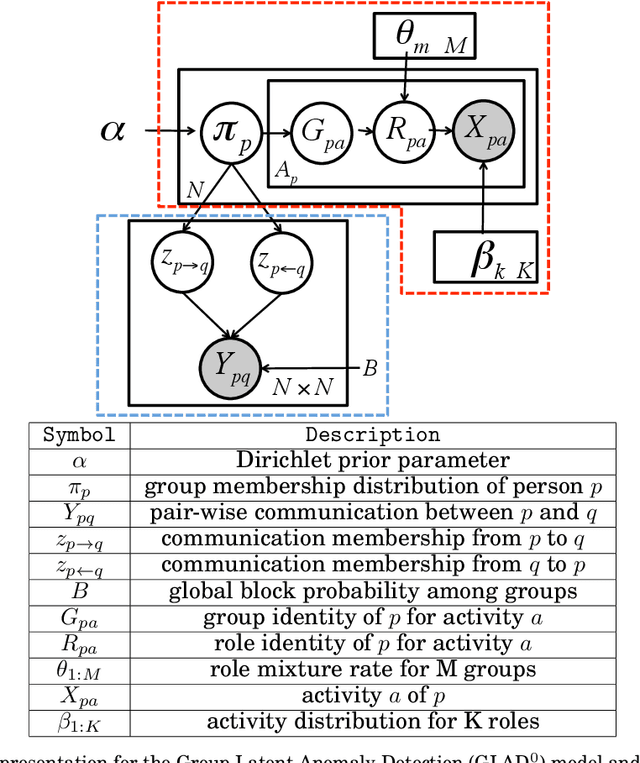
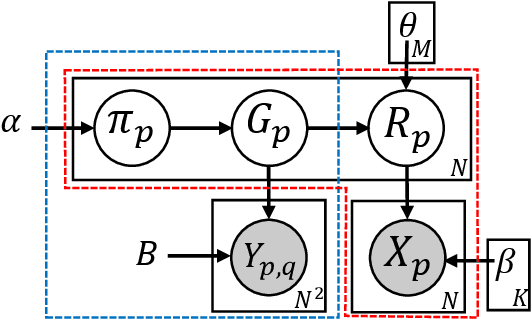
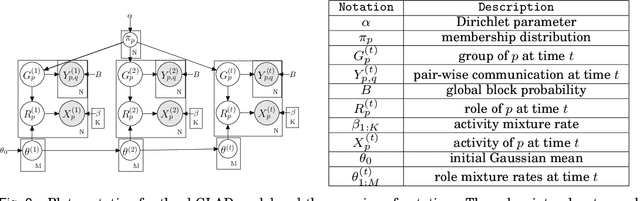
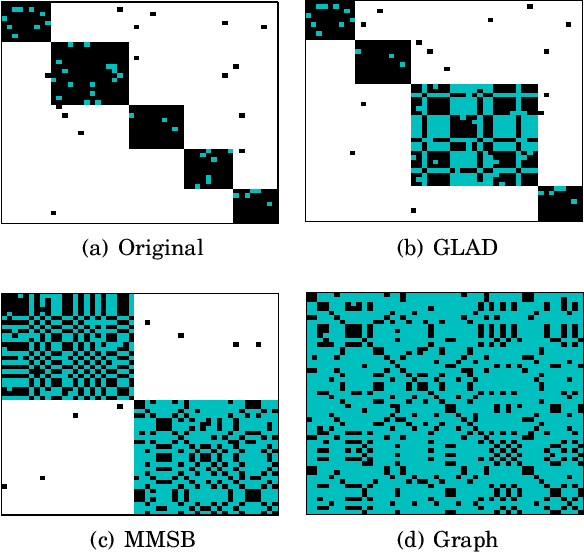
Traditional anomaly detection on social media mostly focuses on individual point anomalies while anomalous phenomena usually occur in groups. Therefore it is valuable to study the collective behavior of individuals and detect group anomalies. Existing group anomaly detection approaches rely on the assumption that the groups are known, which can hardly be true in real world social media applications. In this paper, we take a generative approach by proposing a hierarchical Bayes model: Group Latent Anomaly Detection (GLAD) model. GLAD takes both pair-wise and point-wise data as input, automatically infers the groups and detects group anomalies simultaneously. To account for the dynamic properties of the social media data, we further generalize GLAD to its dynamic extension d-GLAD. We conduct extensive experiments to evaluate our models on both synthetic and real world datasets. The empirical results demonstrate that our approach is effective and robust in discovering latent groups and detecting group anomalies.
Virtual Vector Machine for Bayesian Online Classification
May 09, 2012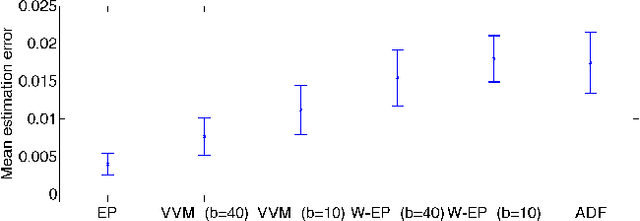
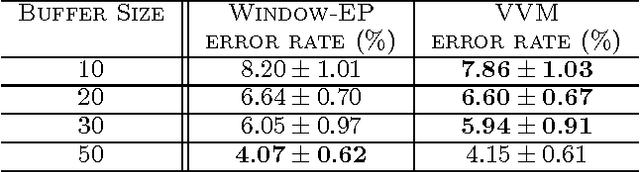
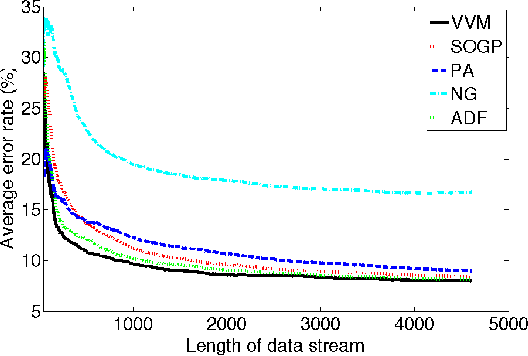

In a typical online learning scenario, a learner is required to process a large data stream using a small memory buffer. Such a requirement is usually in conflict with a learner's primary pursuit of prediction accuracy. To address this dilemma, we introduce a novel Bayesian online classi cation algorithm, called the Virtual Vector Machine. The virtual vector machine allows you to smoothly trade-off prediction accuracy with memory size. The virtual vector machine summarizes the information contained in the preceding data stream by a Gaussian distribution over the classi cation weights plus a constant number of virtual data points. The virtual data points are designed to add extra non-Gaussian information about the classi cation weights. To maintain the constant number of virtual points, the virtual vector machine adds the current real data point into the virtual point set, merges two most similar virtual points into a new virtual point or deletes a virtual point that is far from the decision boundary. The information lost in this process is absorbed into the Gaussian distribution. The extra information provided by the virtual points leads to improved predictive accuracy over previous online classification algorithms.
Sparse-posterior Gaussian Processes for general likelihoods
Mar 15, 2012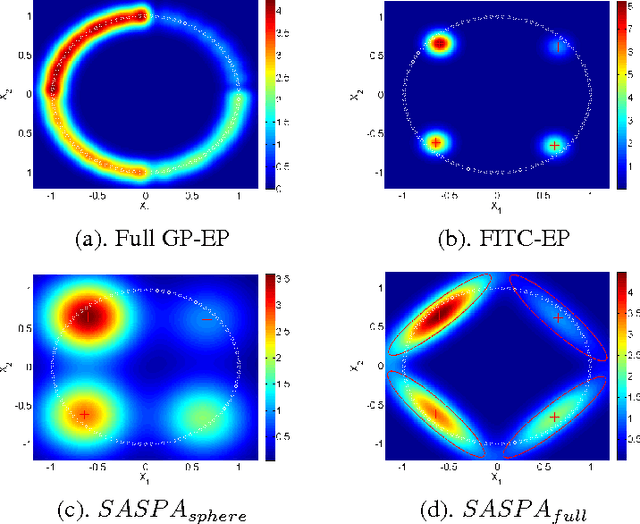
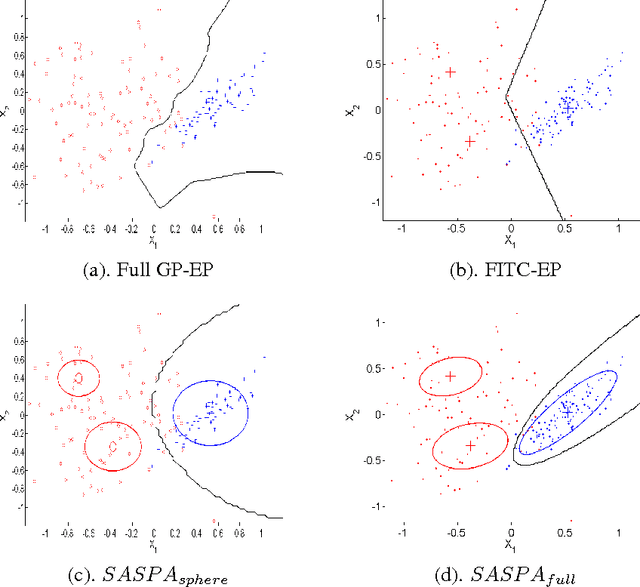
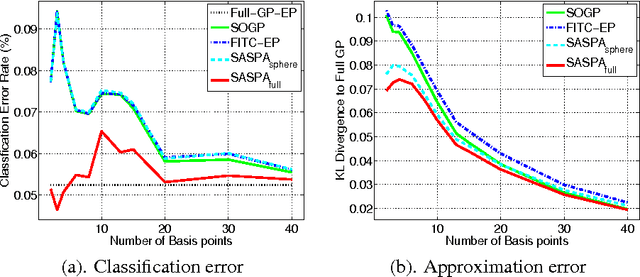
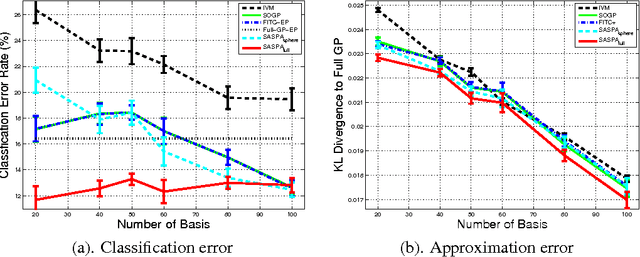
Gaussian processes (GPs) provide a probabilistic nonparametric representation of functions in regression, classification, and other problems. Unfortunately, exact learning with GPs is intractable for large datasets. A variety of approximate GP methods have been proposed that essentially map the large dataset into a small set of basis points. Among them, two state-of-the-art methods are sparse pseudo-input Gaussian process (SPGP) (Snelson and Ghahramani, 2006) and variablesigma GP (VSGP) Walder et al. (2008), which generalizes SPGP and allows each basis point to have its own length scale. However, VSGP was only derived for regression. In this paper, we propose a new sparse GP framework that uses expectation propagation to directly approximate general GP likelihoods using a sparse and smooth basis. It includes both SPGP and VSGP for regression as special cases. Plus as an EP algorithm, it inherits the ability to process data online. As a particular choice of approximating family, we blur each basis point with a Gaussian distribution that has a full covariance matrix representing the data distribution around that basis point; as a result, we can summarize local data manifold information with a small set of basis points. Our experiments demonstrate that this framework outperforms previous GP classification methods on benchmark datasets in terms of minimizing divergence to the non-sparse GP solution as well as lower misclassification rate.
Sparse matrix-variate Gaussian process blockmodels for network modeling
Feb 14, 2012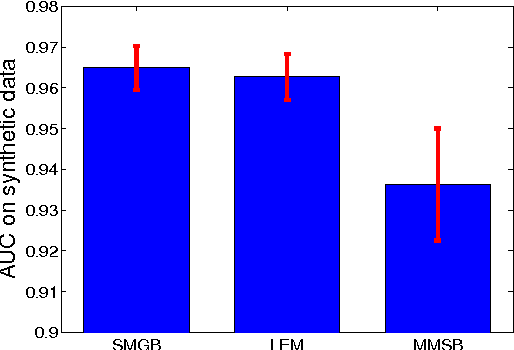
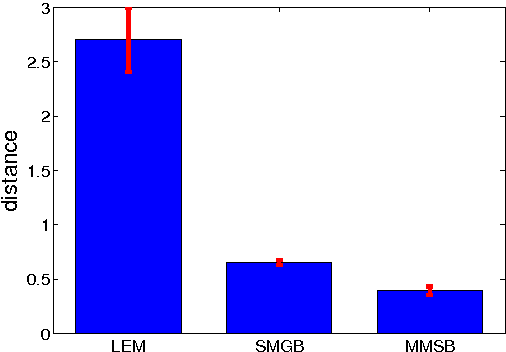


We face network data from various sources, such as protein interactions and online social networks. A critical problem is to model network interactions and identify latent groups of network nodes. This problem is challenging due to many reasons. For example, the network nodes are interdependent instead of independent of each other, and the data are known to be very noisy (e.g., missing edges). To address these challenges, we propose a new relational model for network data, Sparse Matrix-variate Gaussian process Blockmodel (SMGB). Our model generalizes popular bilinear generative models and captures nonlinear network interactions using a matrix-variate Gaussian process with latent membership variables. We also assign sparse prior distributions on the latent membership variables to learn sparse group assignments for individual network nodes. To estimate the latent variables efficiently from data, we develop an efficient variational expectation maximization method. We compared our approaches with several state-of-the-art network models on both synthetic and real-world network datasets. Experimental results demonstrate SMGBs outperform the alternative approaches in terms of discovering latent classes or predicting unknown interactions.
Infinite Tucker Decomposition: Nonparametric Bayesian Models for Multiway Data Analysis
Jan 14, 2012

Tensor decomposition is a powerful computational tool for multiway data analysis. Many popular tensor decomposition approaches---such as the Tucker decomposition and CANDECOMP/PARAFAC (CP)---amount to multi-linear factorization. They are insufficient to model (i) complex interactions between data entities, (ii) various data types (e.g. missing data and binary data), and (iii) noisy observations and outliers. To address these issues, we propose tensor-variate latent nonparametric Bayesian models, coupled with efficient inference methods, for multiway data analysis. We name these models InfTucker. Using these InfTucker, we conduct Tucker decomposition in an infinite feature space. Unlike classical tensor decomposition models, our new approaches handle both continuous and binary data in a probabilistic framework. Unlike previous Bayesian models on matrices and tensors, our models are based on latent Gaussian or $t$ processes with nonlinear covariance functions. To efficiently learn the InfTucker from data, we develop a variational inference technique on tensors. Compared with classical implementation, the new technique reduces both time and space complexities by several orders of magnitude. Our experimental results on chemometrics and social network datasets demonstrate that our new models achieved significantly higher prediction accuracy than the most state-of-art tensor decomposition