 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Monte Carlo Based Algorithm for the Gaussian Process Classification Problem
Oct 17, 2013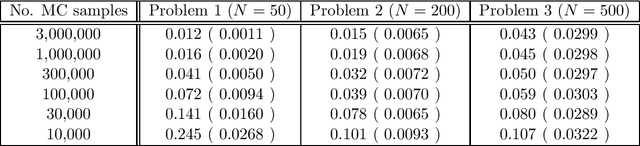
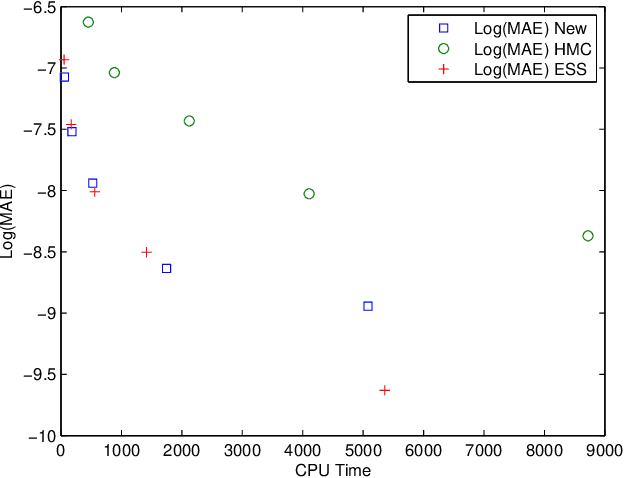
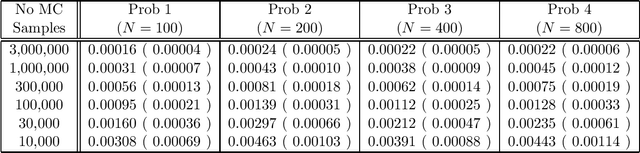
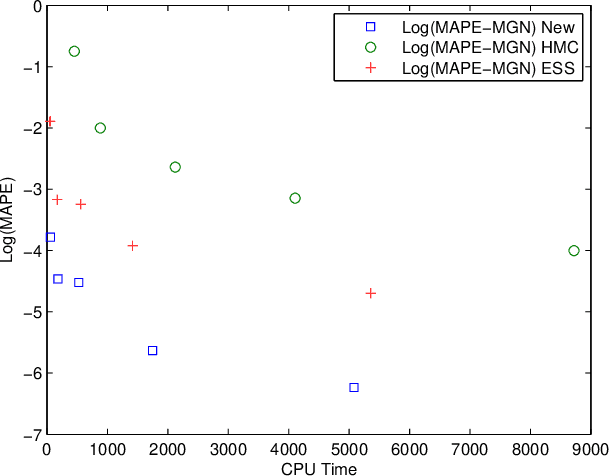
Gaussian process is a very promising novel technology that has been applied to both the regression problem and the classification problem. While for the regression problem it yields simple exact solutions, this is not the case for the classification problem, because we encounter intractable integrals. In this paper we develop a new derivation that transforms the problem into that of evaluating the ratio of multivariate Gaussian orthant integrals. Moreover, we develop a new Monte Carlo procedure that evaluates these integrals. It is based on some aspects of bootstrap sampling and acceptancerejection. The proposed approach has beneficial properties compared to the existing Markov Chain Monte Carlo approach, such as simplicity, reliability, and speed.
Sparse-posterior Gaussian Processes for general likelihoods
Mar 15, 2012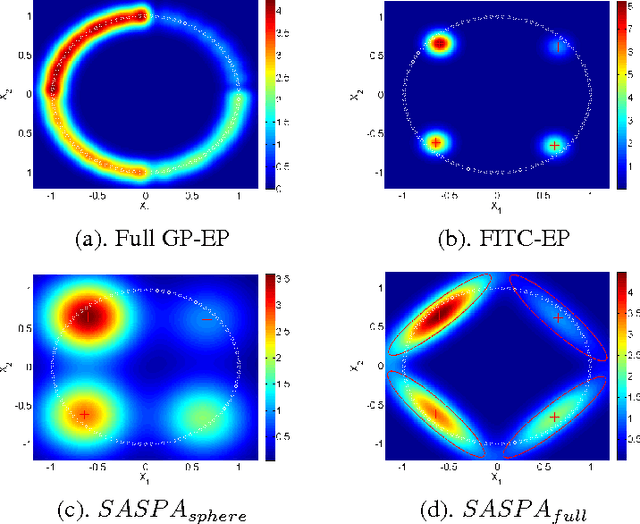
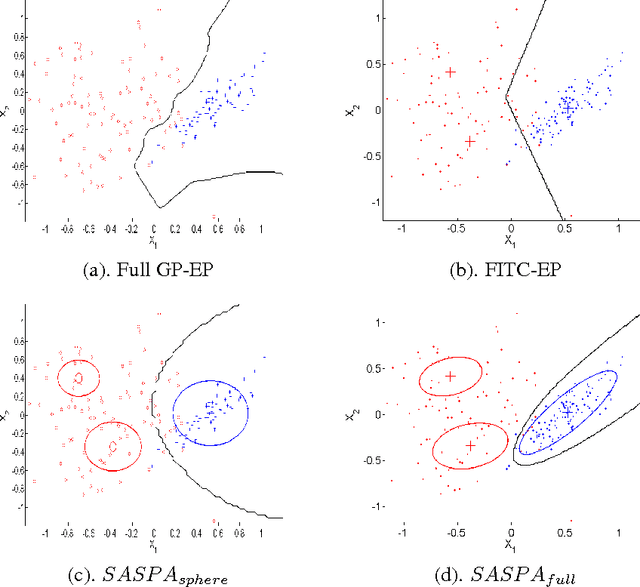
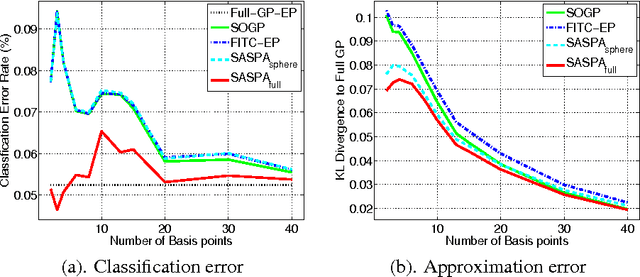
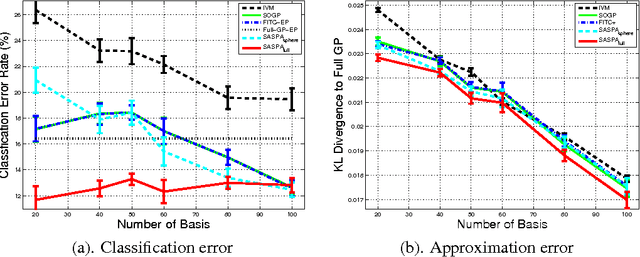
Gaussian processes (GPs) provide a probabilistic nonparametric representation of functions in regression, classification, and other problems. Unfortunately, exact learning with GPs is intractable for large datasets. A variety of approximate GP methods have been proposed that essentially map the large dataset into a small set of basis points. Among them, two state-of-the-art methods are sparse pseudo-input Gaussian process (SPGP) (Snelson and Ghahramani, 2006) and variablesigma GP (VSGP) Walder et al. (2008), which generalizes SPGP and allows each basis point to have its own length scale. However, VSGP was only derived for regression. In this paper, we propose a new sparse GP framework that uses expectation propagation to directly approximate general GP likelihoods using a sparse and smooth basis. It includes both SPGP and VSGP for regression as special cases. Plus as an EP algorithm, it inherits the ability to process data online. As a particular choice of approximating family, we blur each basis point with a Gaussian distribution that has a full covariance matrix representing the data distribution around that basis point; as a result, we can summarize local data manifold information with a small set of basis points. Our experiments demonstrate that this framework outperforms previous GP classification methods on benchmark datasets in terms of minimizing divergence to the non-sparse GP solution as well as lower misclassification rate.
Variable sigma Gaussian processes: An expectation propagation perspective
Oct 07, 2009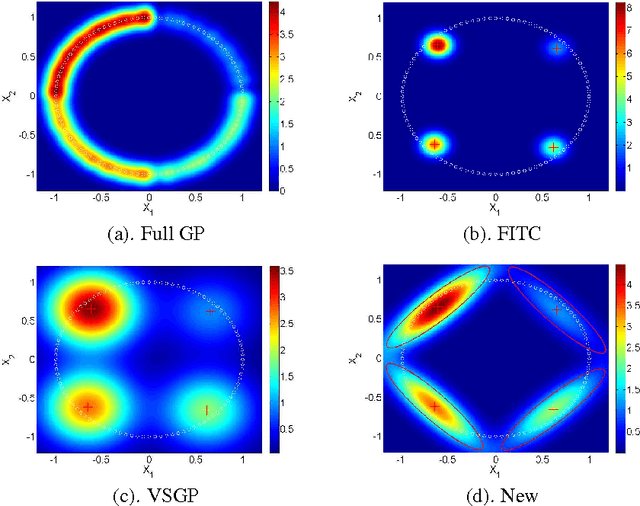
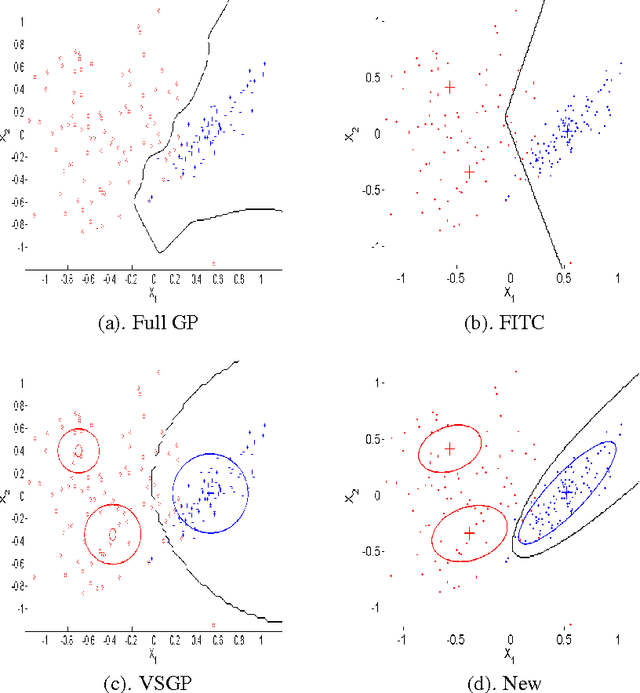
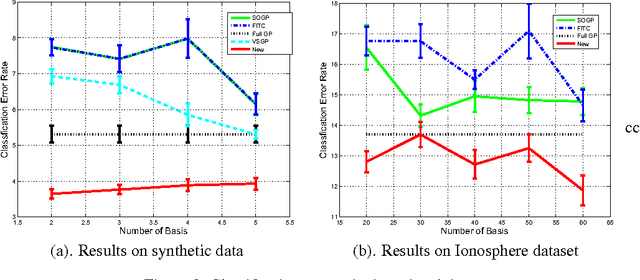
Gaussian processes (GPs) provide a probabilistic nonparametric representation of functions in regression, classification, and other problems. Unfortunately, exact learning with GPs is intractable for large datasets. A variety of approximate GP methods have been proposed that essentially map the large dataset into a small set of basis points. The most advanced of these, the variable-sigma GP (VSGP) (Walder et al., 2008), allows each basis point to have its own length scale. However, VSGP was only derived for regression. We describe how VSGP can be applied to classification and other problems, by deriving it as an expectation propagation algorithm. In this view, sparse GP approximations correspond to a KL-projection of the true posterior onto a compact exponential family of GPs. VSGP constitutes one such family, and we show how to enlarge this family to get additional accuracy. In particular, we show that endowing each basis point with its own full covariance matrix provides a significant increase in approximation power.