 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARCOQ: Arabic Closest Opposite Questions Dataset
Oct 22, 2023This paper presents a dataset for closest opposite questions in Arabic language. The dataset is the first of its kind for the Arabic language. It is beneficial for the assessment of systems on the aspect of antonymy detection. The structure is similar to that of the Graduate Record Examination (GRE) closest opposite questions dataset for the English language. The introduced dataset consists of 500 questions, each contains a query word for which the closest opposite needs to be determined from among a set of candidate words. Each question is also associated with the correct answer. We publish the dataset publicly in addition to providing standard splits of the dataset into development and test sets. Moreover, the paper provides a benchmark for the performance of different Arabic word embedding models on the introduced dataset.
Partial Resampling of Imbalanced Data
Jul 11, 2022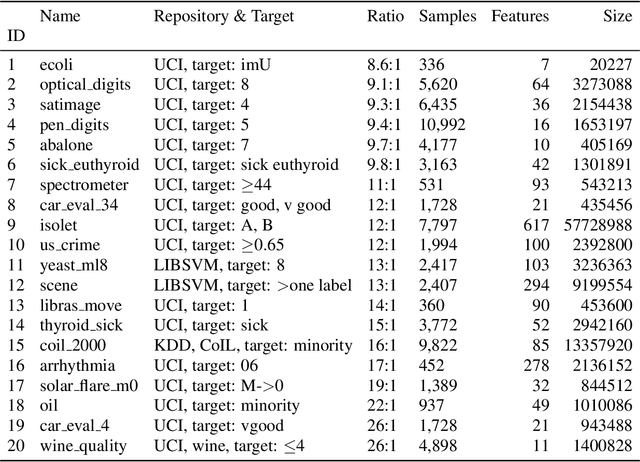
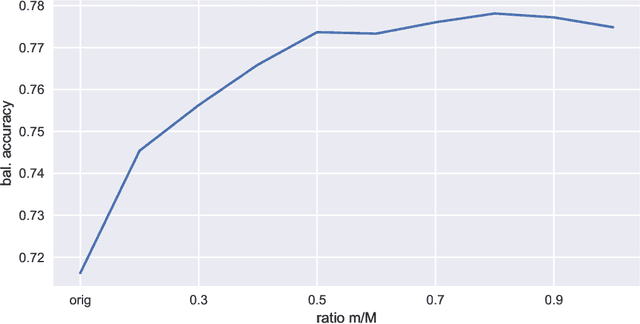
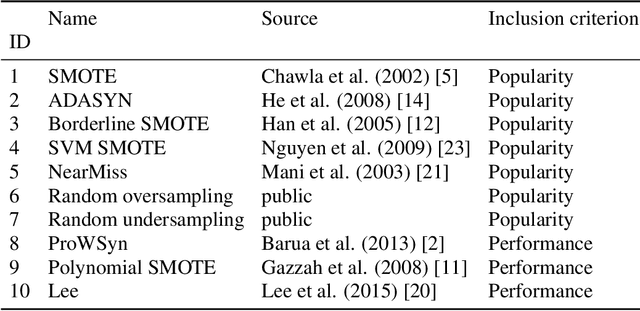
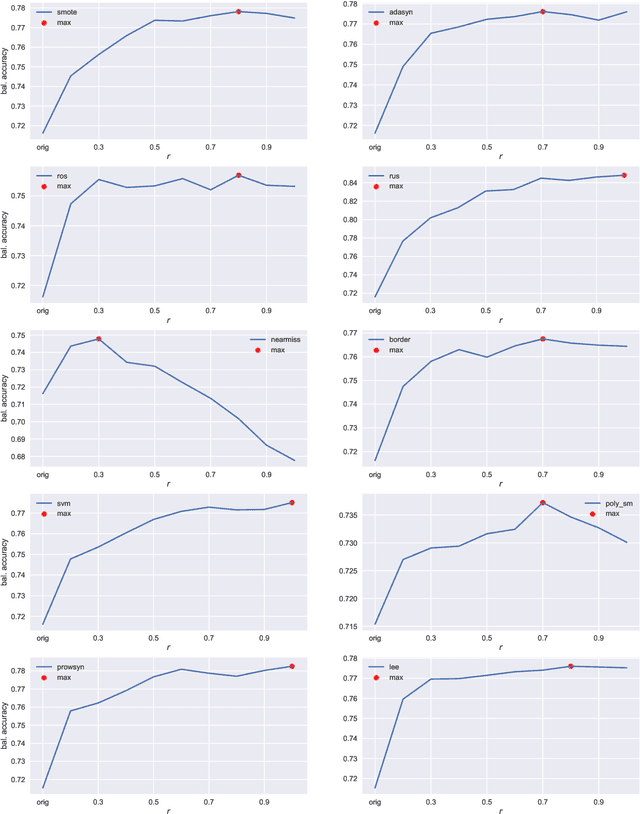
Imbalanced data is a frequently encountered problem in machine learning. Despite a vast amount of literature on sampling techniques for imbalanced data, there is a limited number of studies that address the issue of the optimal sampling ratio. In this paper, we attempt to fill the gap in the literature by conducting a large scale study of the effects of sampling ratio on classification accuracy. We consider 10 popular sampling methods and evaluate their performance over a range of ratios based on 20 datasets. The results of the numerical experiments suggest that the optimal sampling ratio is between 0.7 and 0.8 albeit the exact ratio varies depending on the dataset. Furthermore, we find that while factors such the original imbalance ratio or the number of features do not play a discernible role in determining the optimal ratio, the number of samples in the dataset may have a tangible effect.
Handling of uncertainty in medical data using machine learning and probability theory techniques: A review of 30 years
Aug 23, 2020
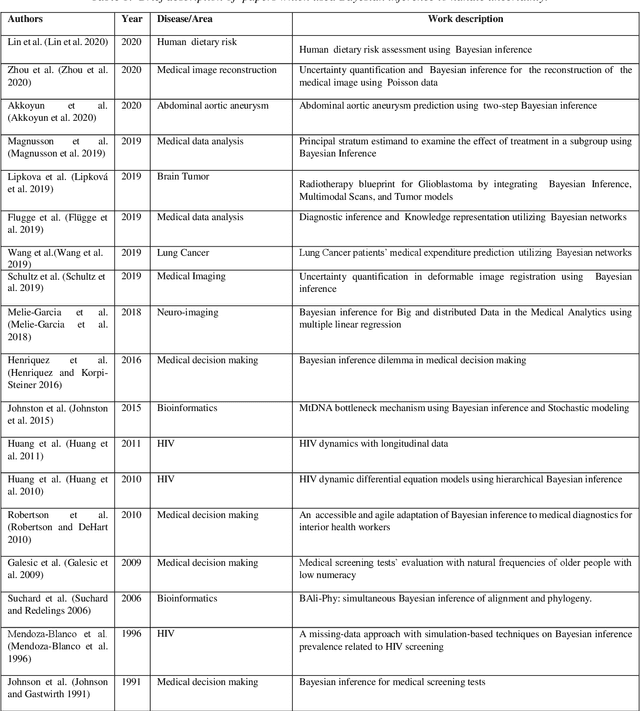
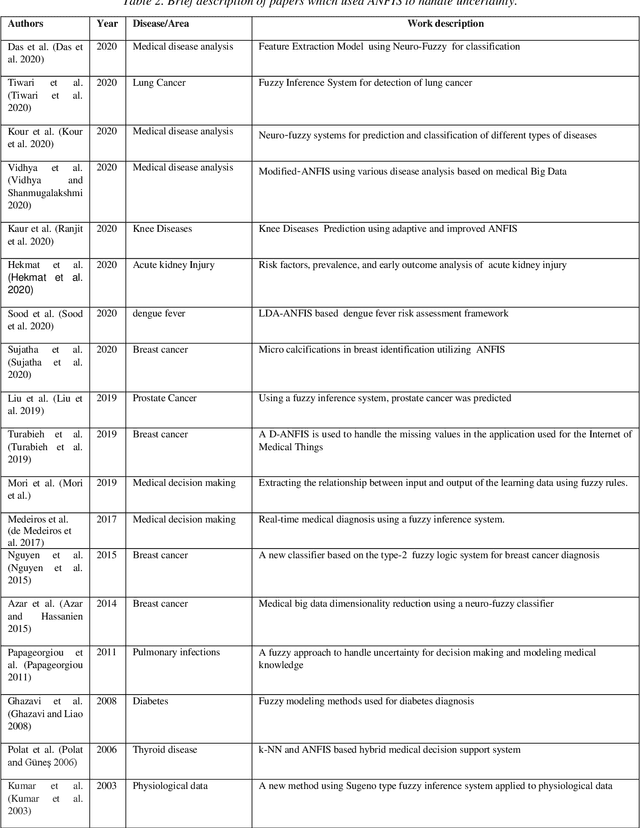
Understanding data and reaching valid conclusions are of paramount importance in the present era of big data. Machine learning and probability theory methods have widespread application for this purpose in different fields. One critically important yet less explored aspect is how data and model uncertainties are captured and analyzed. Proper quantification of uncertainty provides valuable information for optimal decision making. This paper reviewed related studies conducted in the last 30 years (from 1991 to 2020) in handling uncertainties in medical data using probability theory and machine learning techniques. Medical data is more prone to uncertainty due to the presence of noise in the data. So, it is very important to have clean medical data without any noise to get accurate diagnosis. The sources of noise in the medical data need to be known to address this issue. Based on the medical data obtained by the physician, diagnosis of disease, and treatment plan are prescribed. Hence, the uncertainty is growing in healthcare and there is limited knowledge to address these problems. We have little knowledge about the optimal treatment methods as there are many sources of uncertainty in medical science. Our findings indicate that there are few challenges to be addressed in handling the uncertainty in medical raw data and new models. In this work, we have summarized various methods employed to overcome this problem. Nowadays, application of novel deep learning techniques to deal such uncertainties have significantly increased.
Epileptic seizure detection using deep learning techniques: A Review
Jul 02, 2020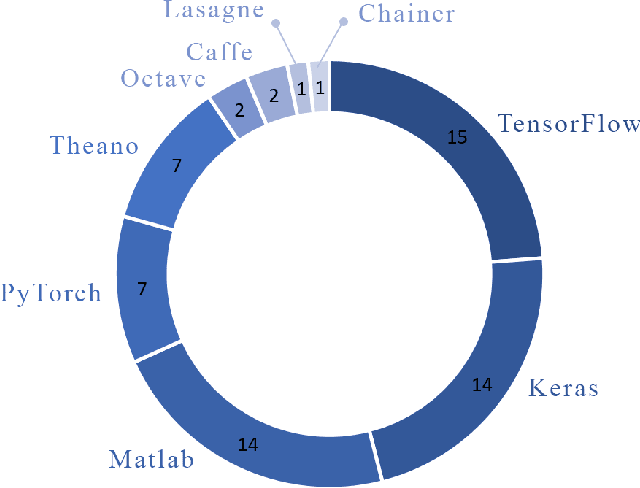
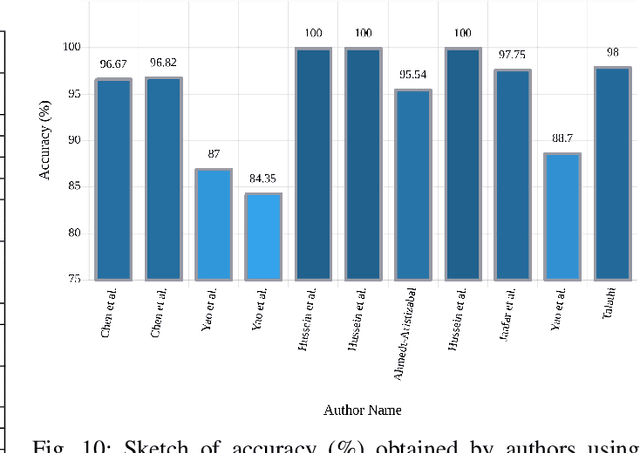
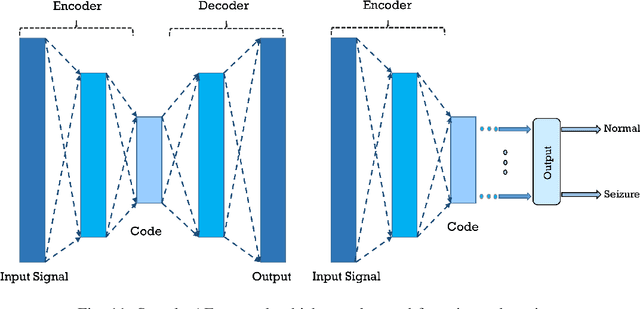
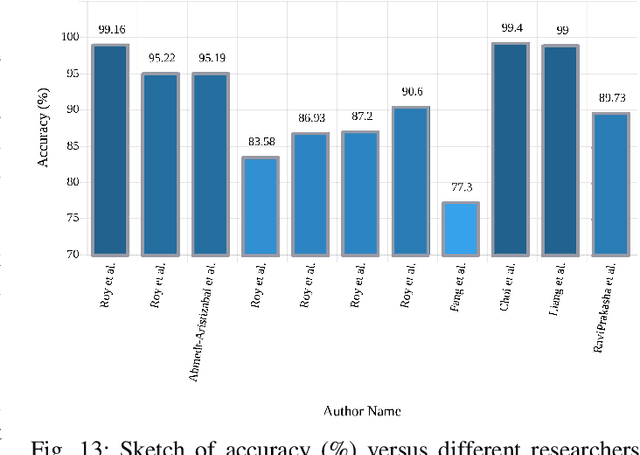
A variety of screening approaches have been proposed to diagnose epileptic seizures, using Electroencephalography (EEG) and Magnetic Resonance Imaging (MRI) modalities. Artificial intelligence encompasses a variety of areas, and one of its branches is deep learning. Before the rise of deep learning, conventional machine learning algorithms involving feature extraction were performed. This limited their performance to the ability of those handcrafting the features. However, in deep learning, the extraction of features and classification is entirely automated. The advent of these techniques in many areas of medicine such as diagnosis of epileptic seizures, has made significant advances. In this study, a comprehensive overview of the types of deep learning methods exploited to diagnose epileptic seizures from various modalities has been studied. Additionally, hardware implementation and cloud-based works are discussed as they are most suited for applied medicine.
A New Monte Carlo Based Algorithm for the Gaussian Process Classification Problem
Oct 17, 2013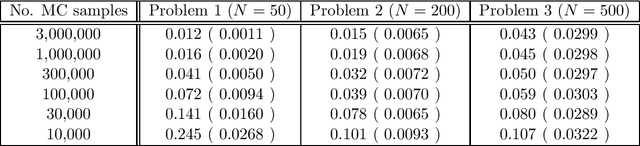
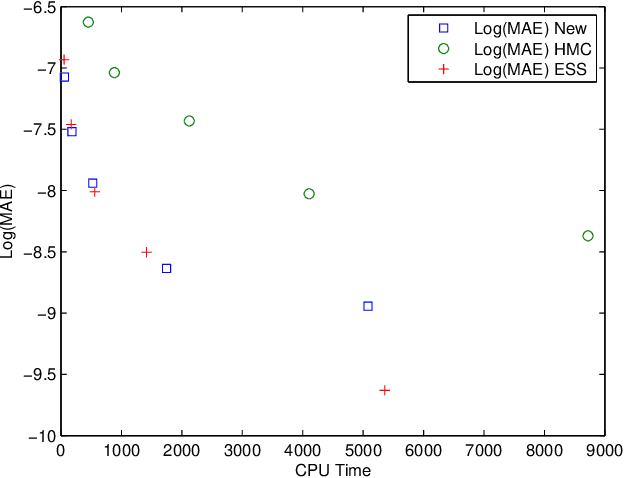
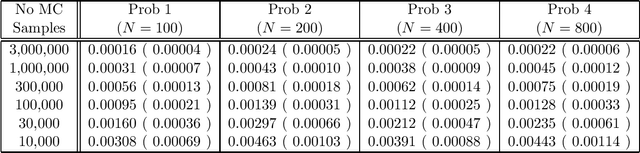
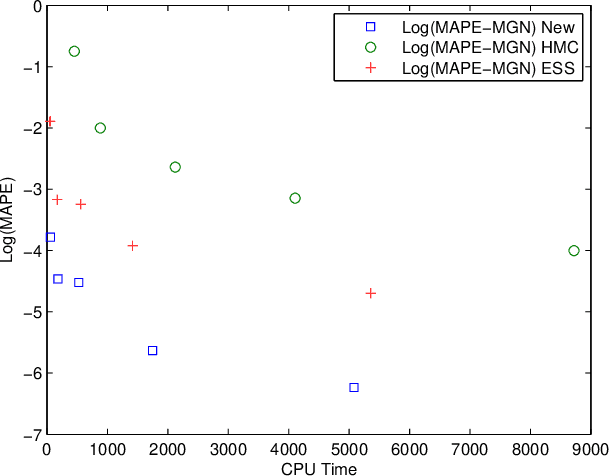
Gaussian process is a very promising novel technology that has been applied to both the regression problem and the classification problem. While for the regression problem it yields simple exact solutions, this is not the case for the classification problem, because we encounter intractable integrals. In this paper we develop a new derivation that transforms the problem into that of evaluating the ratio of multivariate Gaussian orthant integrals. Moreover, we develop a new Monte Carlo procedure that evaluates these integrals. It is based on some aspects of bootstrap sampling and acceptancerejection. The proposed approach has beneficial properties compared to the existing Markov Chain Monte Carlo approach, such as simplicity, reliability, and speed.
A Novel Symbolic Type Neural Network Model- Application to River Flow Forecasting
Aug 09, 2008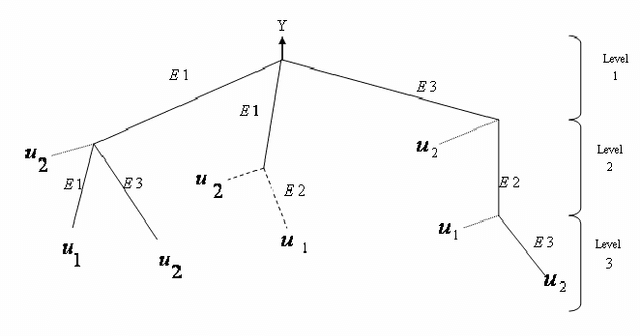
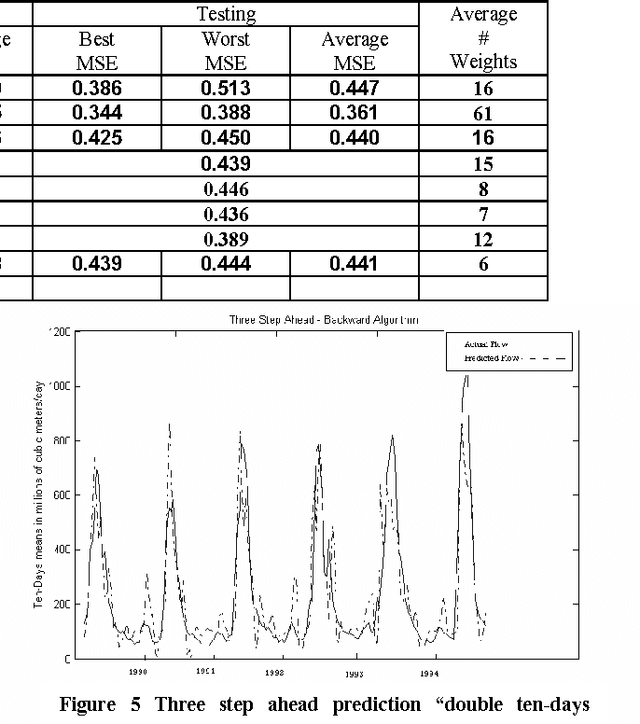
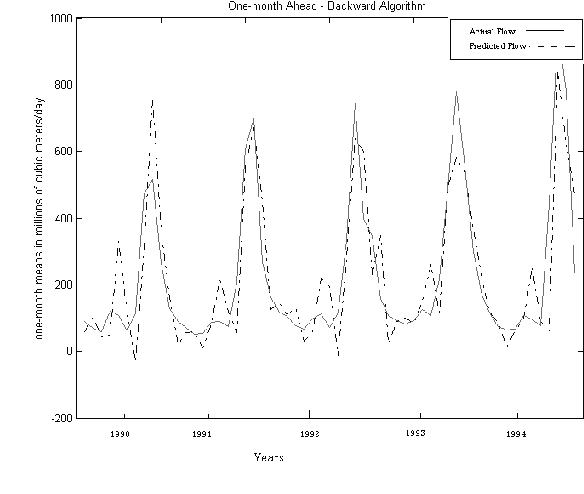
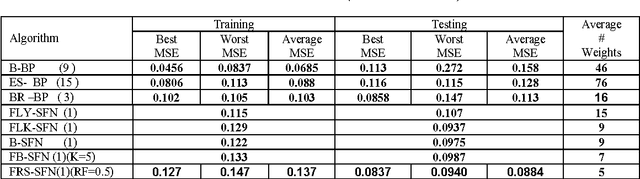
In this paper we introduce a new symbolic type neural tree network called symbolic function network (SFN) that is based on using elementary functions to model systems in a symbolic form. The proposed formulation permits feature selection, functional selection, and flexible structure. We applied this model on the River Flow forecasting problem. The results found to be superior in both fitness and sparsity.