 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Resampling of Imbalanced Data
Paper and Code
Jul 11, 2022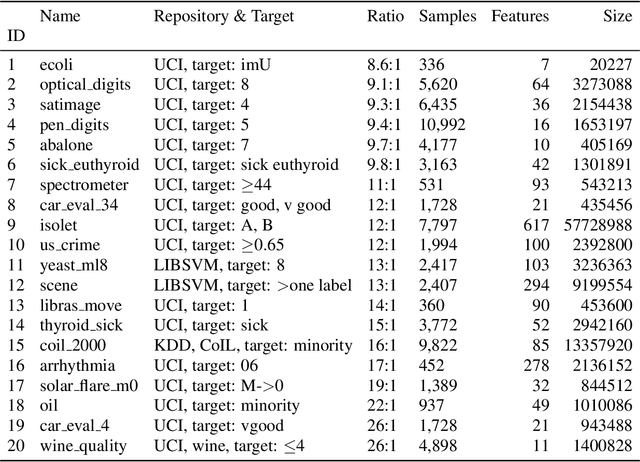
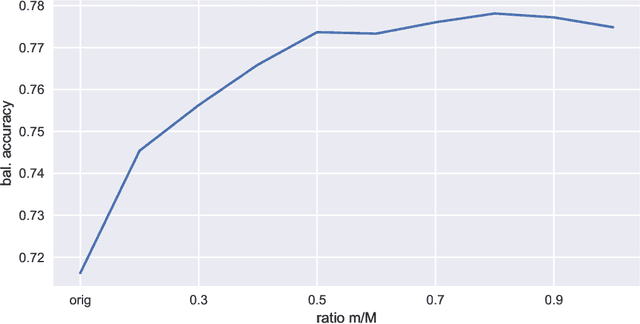
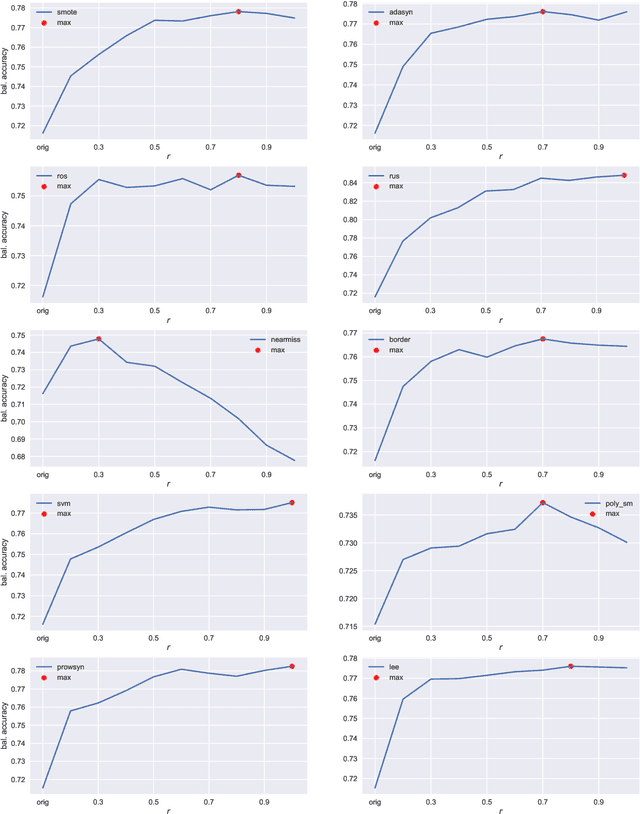
Imbalanced data is a frequently encountered problem in machine learning. Despite a vast amount of literature on sampling techniques for imbalanced data, there is a limited number of studies that address the issue of the optimal sampling ratio. In this paper, we attempt to fill the gap in the literature by conducting a large scale study of the effects of sampling ratio on classification accuracy. We consider 10 popular sampling methods and evaluate their performance over a range of ratios based on 20 datasets. The results of the numerical experiments suggest that the optimal sampling ratio is between 0.7 and 0.8 albeit the exact ratio varies depending on the dataset. Furthermore, we find that while factors such the original imbalance ratio or the number of features do not play a discernible role in determining the optimal ratio, the number of samples in the dataset may have a tangible effect.