 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Convergence of SMOTE-Generated Samples
Jan 05, 2026Imbalanced data affects a wide range of machine learning applications, from healthcare to network security. As SMOTE is one of the most popular approaches to addressing this issue, it is imperative to validate it not only empirically but also theoretically. In this paper, we provide a rigorous theoretical analysis of SMOTE's convergence properties. Concretely, we prove that the synthetic random variable Z converges in probability to the underlying random variable X. We further prove a stronger convergence in mean when X is compact. Finally, we show that lower values of the nearest neighbor rank lead to faster convergence offering actionable guidance to practitioners. The theoretical results are supported by numerical experiments using both real-life and synthetic data. Our work provides a foundational understanding that enhances data augmentation techniques beyond imbalanced data scenarios.
Evolution of AI in Education: Agentic Workflows
Apr 25, 2025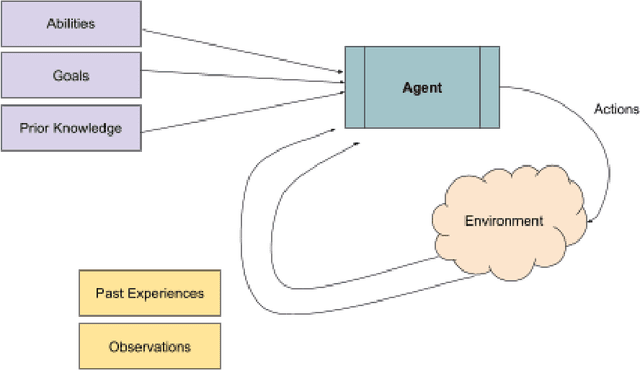
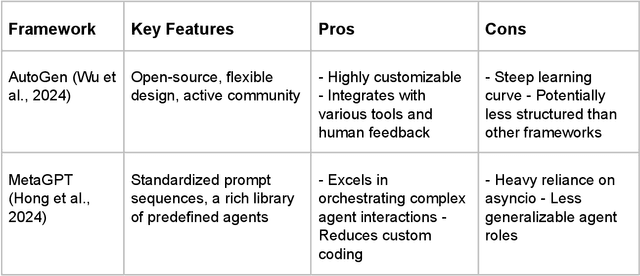
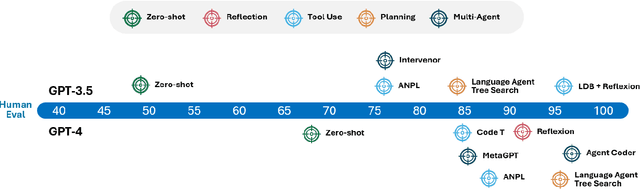
Artificial intelligence (AI) has transformed various aspects of education, with large language models (LLMs) driving advancements in automated tutoring, assessment, and content generation. However, conventional LLMs are constrained by their reliance on static training data, limited adaptability, and lack of reasoning. To address these limitations and foster more sustainable technological practices, AI agents have emerged as a promising new avenue for educational innovation. In this review, we examine agentic workflows in education according to four major paradigms: reflection, planning, tool use, and multi-agent collaboration. We critically analyze the role of AI agents in education through these key design paradigms, exploring their advantages, applications, and challenges. To illustrate the practical potential of agentic systems, we present a proof-of-concept application: a multi-agent framework for automated essay scoring. Preliminary results suggest this agentic approach may offer improved consistency compared to stand-alone LLMs. Our findings highlight the transformative potential of AI agents in educational settings while underscoring the need for further research into their interpretability, trustworthiness, and sustainable impact on pedagogical impact.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Lightweight Fish Classification Model for Sustainable Marine Management: Indonesian Case
Jan 04, 2024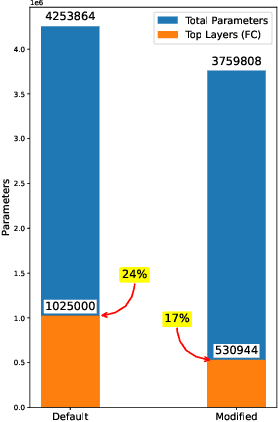
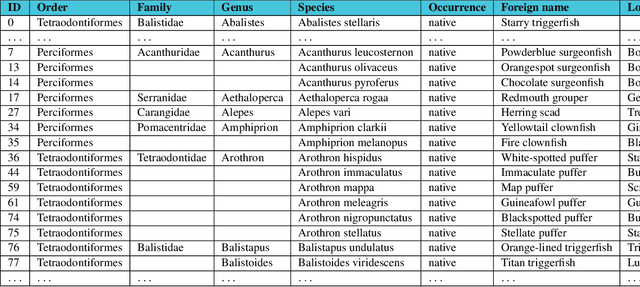
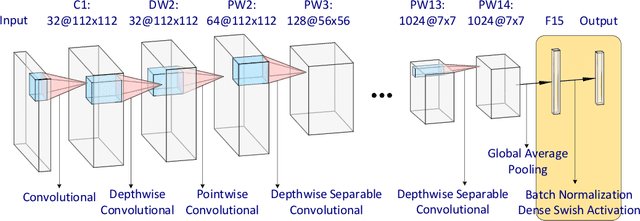
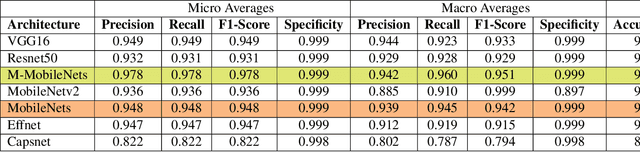
The enormous demand for seafood products has led to exploitation of marine resources and near-extinction of some species. In particular, overfishing is one the main issues in sustainable marine development. In alignment with the protection of marine resources and sustainable fishing, this study proposes to advance fish classification techniques that support identifying protected fish species using state-of-the-art machine learning. We use a custom modification of the MobileNet model to design a lightweight classifier called M-MobileNet that is capable of running on limited hardware. As part of the study, we compiled a labeled dataset of 37,462 images of fish found in the waters of the Indonesian archipelago. The proposed model is trained on the dataset to classify images of the captured fish into their species and give recommendations on whether they are consumable or not. Our modified MobileNet model uses only 50\% of the top layer parameters with about 42% GTX 860M utility and achieves up to 97% accuracy in fish classification and determining its consumability. Given the limited computing capacity available on many fishing vessels, the proposed model provides a practical solution to on-site fish classification. In addition, synchronized implementation of the proposed model on multiple vessels can supply valuable information about the movement and location of different species of fish.
e-Inu: Simulating A Quadruped Robot With Emotional Sentience
Jan 03, 2023



Quadruped robots are currently used in industrial robotics as mechanical aid to automate several routine tasks. However, presently, the usage of such a robot in a domestic setting is still very much a part of the research. This paper discusses the understanding and virtual simulation of such a robot capable of detecting and understanding human emotions, generating its gait, and responding via sounds and expression on a screen. To this end, we use a combination of reinforcement learning and software engineering concepts to simulate a quadruped robot that can understand emotions, navigate through various terrains and detect sound sources, and respond to emotions using audio-visual feedback. This paper aims to establish the framework of simulating a quadruped robot that is emotionally intelligent and can primarily respond to audio-visual stimuli using motor or audio response. The emotion detection from the speech was not as performant as ERANNs or Zeta Policy learning, still managing an accuracy of 63.5%. The video emotion detection system produced results that are almost at par with the state of the art, with an accuracy of 99.66%. Due to its "on-policy" learning process, the PPO algorithm was extremely rapid to learn, allowing the simulated dog to demonstrate a remarkably seamless gait across the different cadences and variations. This enabled the quadruped robot to respond to generated stimuli, allowing us to conclude that it functions as predicted and satisfies the aim of this work.
Synthetic Data for Feature Selection
Nov 06, 2022

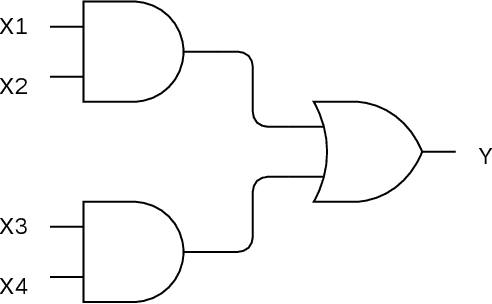

Feature selection is an important and active field of research in machine learning and data science. Our goal in this paper is to propose a collection of synthetic datasets that can be used as a common reference point for feature selection algorithms. Synthetic datasets allow for precise evaluation of selected features and control of the data parameters for comprehensive assessment. The proposed datasets are based on applications from electronics in order to mimic real life scenarios. To illustrate the utility of the proposed data we employ one of the datasets to test several popular feature selection algorithms. The datasets are made publicly available on GitHub and can be used by researchers to evaluate feature selection algorithms.
Partial Resampling of Imbalanced Data
Jul 11, 2022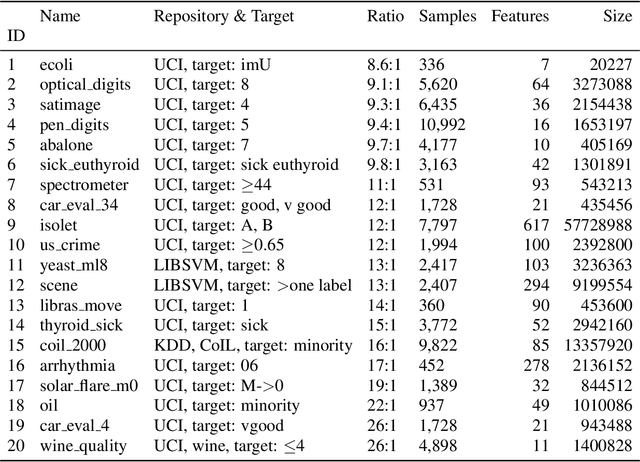
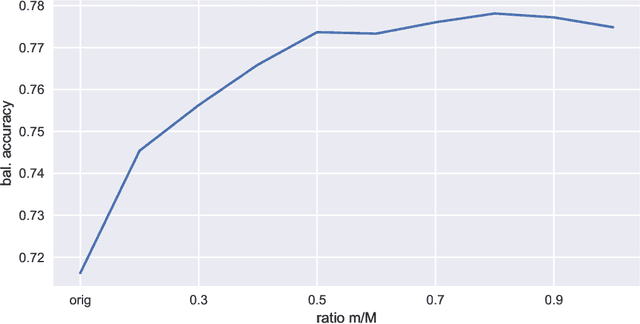
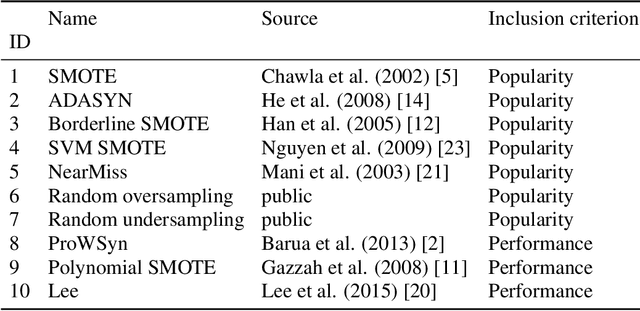
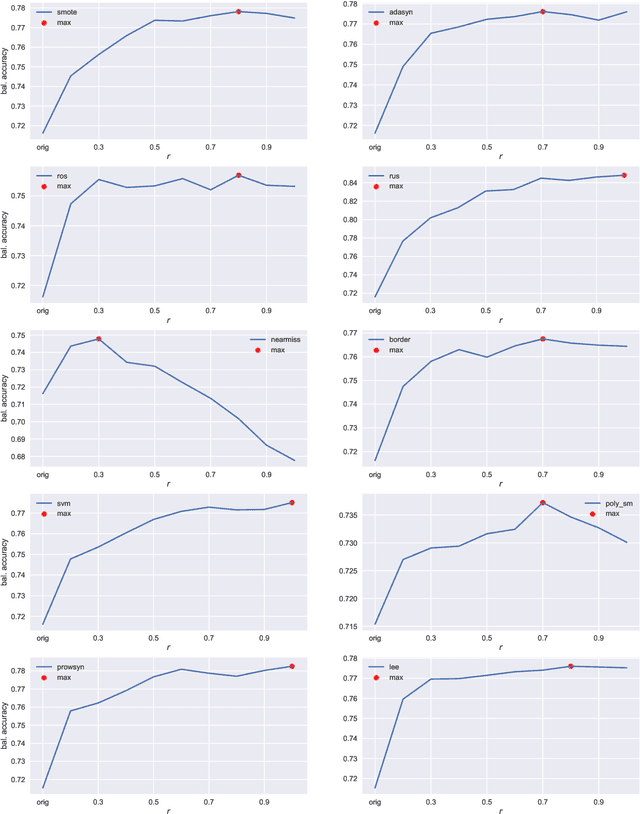
Imbalanced data is a frequently encountered problem in machine learning. Despite a vast amount of literature on sampling techniques for imbalanced data, there is a limited number of studies that address the issue of the optimal sampling ratio. In this paper, we attempt to fill the gap in the literature by conducting a large scale study of the effects of sampling ratio on classification accuracy. We consider 10 popular sampling methods and evaluate their performance over a range of ratios based on 20 datasets. The results of the numerical experiments suggest that the optimal sampling ratio is between 0.7 and 0.8 albeit the exact ratio varies depending on the dataset. Furthermore, we find that while factors such the original imbalance ratio or the number of features do not play a discernible role in determining the optimal ratio, the number of samples in the dataset may have a tangible effect.
Kernel density estimation-based sampling for neural network classification
Oct 25, 2021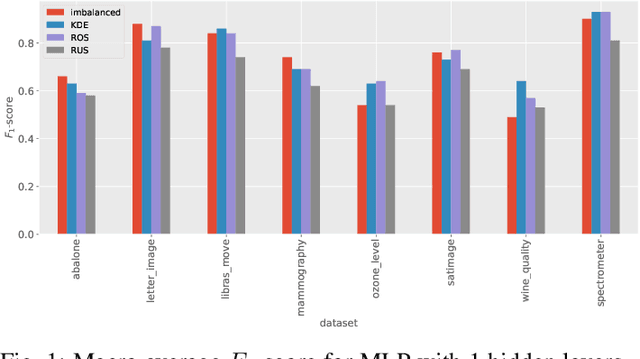

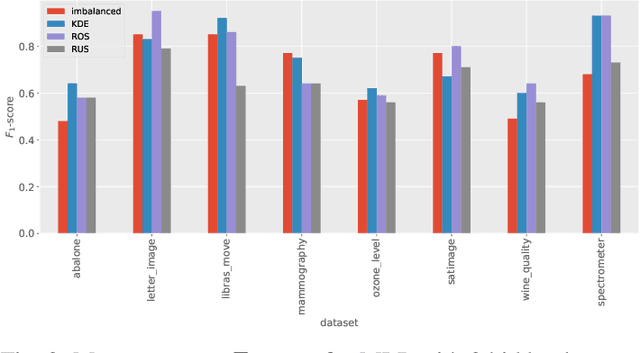
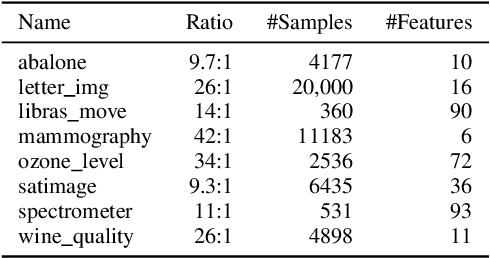
Imbalanced data occurs in a wide range of scenarios. The skewed distribution of the target variable elicits bias in machine learning algorithms. One of the popular methods to combat imbalanced data is to artificially balance the data through resampling. In this paper, we compare the efficacy of a recently proposed kernel density estimation (KDE) sampling technique in the context of artificial neural networks. We benchmark the KDE sampling method against two base sampling techniques and perform comparative experiments using 8 datasets and 3 neural networks architectures. The results show that KDE sampling produces the best performance on 6 out of 8 datasets. However, it must be used with caution on image datasets. We conclude that KDE sampling is capable of significantly improving the performance of neural networks.
Orthogonal variance-based feature selection for intrusion detection systems
Oct 25, 2021
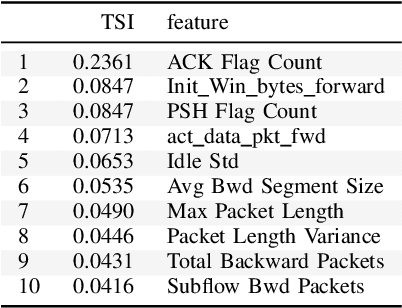

In this paper, we apply a fusion machine learning method to construct an automatic intrusion detection system. Concretely, we employ the orthogonal variance decomposition technique to identify the relevant features in network traffic data. The selected features are used to build a deep neural network for intrusion detection. The proposed algorithm achieves 100% detection accuracy in identifying DDoS attacks. The test results indicate a great potential of the proposed method.
Feature selection for intrusion detection systems
Jun 28, 2021

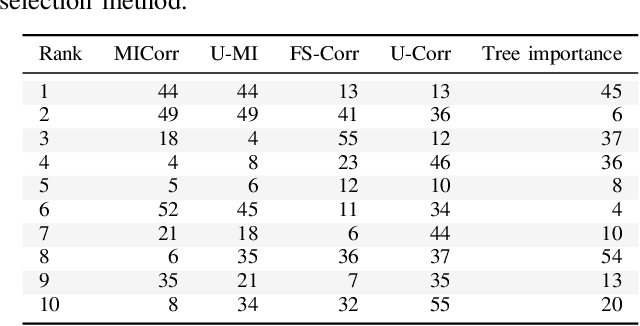
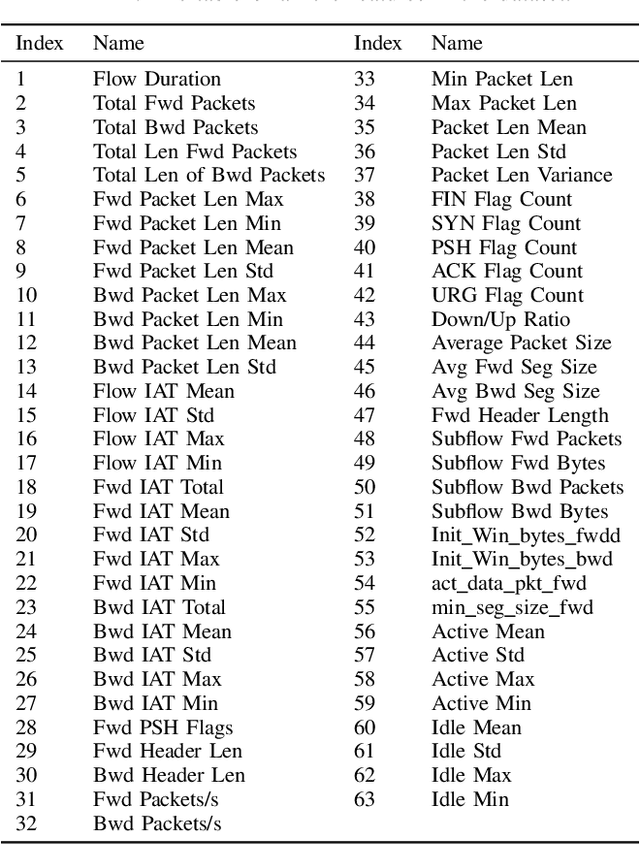
In this paper, we analyze existing feature selection methods to identify the key elements of network traffic data that allow intrusion detection. In addition, we propose a new feature selection method that addresses the challenge of considering continuous input features and discrete target values. We show that the proposed method performs well against the benchmark selection methods. We use our findings to develop a highly effective machine learning-based detection systems that achieves 99.9% accuracy in distinguishing between DDoS and benign signals. We believe that our results can be useful to experts who are interested in designing and building automated intrusion detection systems.