 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Explainable Text Detoxification with Parallel Corpora
Dec 16, 2024Even with various regulations in place across countries and social media platforms (Government of India, 2021; European Parliament and Council of the European Union, 2022, digital abusive speech remains a significant issue. One potential approach to address this challenge is automatic text detoxification, a text style transfer (TST) approach that transforms toxic language into a more neutral or non-toxic form. To date, the availability of parallel corpora for the text detoxification task (Logachevavet al., 2022; Atwell et al., 2022; Dementievavet al., 2024a) has proven to be crucial for state-of-the-art approaches. With this work, we extend parallel text detoxification corpus to new languages -- German, Chinese, Arabic, Hindi, and Amharic -- testing in the extensive multilingual setup TST baselines. Next, we conduct the first of its kind an automated, explainable analysis of the descriptive features of both toxic and non-toxic sentences, diving deeply into the nuances, similarities, and differences of toxicity and detoxification across 9 languages. Finally, based on the obtained insights, we experiment with a novel text detoxification method inspired by the Chain-of-Thoughts reasoning approach, enhancing the prompting process through clustering on relevant descriptive attributes.
Augmenting Character Designers Creativity Using Generative Adversarial Networks
May 28, 2023



Recent advances in Generative Adversarial Networks (GANs) continue to attract the attention of researchers in different fields due to the wide range of applications devised to take advantage of their key features. Most recent GANs are focused on realism, however, generating hyper-realistic output is not a priority for some domains, as in the case of this work. The generated outcomes are used here as cognitive components to augment character designers creativity while conceptualizing new characters for different multimedia projects. To select the best-suited GANs for such a creative context, we first present a comparison between different GAN architectures and their performance when trained from scratch on a new visual characters dataset using a single Graphics Processing Unit. We also explore alternative techniques, such as transfer learning and data augmentation, to overcome computational resource limitations, a challenge faced by many researchers in the domain. Additionally, mixed methods are used to evaluate the cognitive value of the generated visuals on character designers agency conceptualizing new characters. The results discussed proved highly effective for this context, as demonstrated by early adaptations to the characters design process. As an extension for this work, the presented approach will be further evaluated as a novel co-design process between humans and machines to investigate where and how the generated concepts are interacting with and influencing the design process outcome.
* 18 pages
RGB Arabic Alphabets Sign Language Dataset
Jan 30, 2023


This paper introduces the RGB Arabic Alphabet Sign Language (AASL) dataset. AASL comprises 7,856 raw and fully labelled RGB images of the Arabic sign language alphabets, which to our best knowledge is the first publicly available RGB dataset. The dataset is aimed to help those interested in developing real-life Arabic sign language classification models. AASL was collected from more than 200 participants and with different settings such as lighting, background, image orientation, image size, and image resolution. Experts in the field supervised, validated and filtered the collected images to ensure a high-quality dataset. AASL is made available to the public on Kaggle.
Arabic Fake News Detection Based on Deep Contextualized Embedding Models
May 06, 2022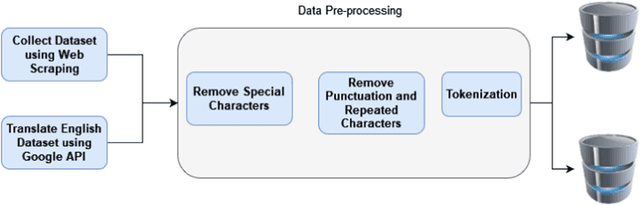
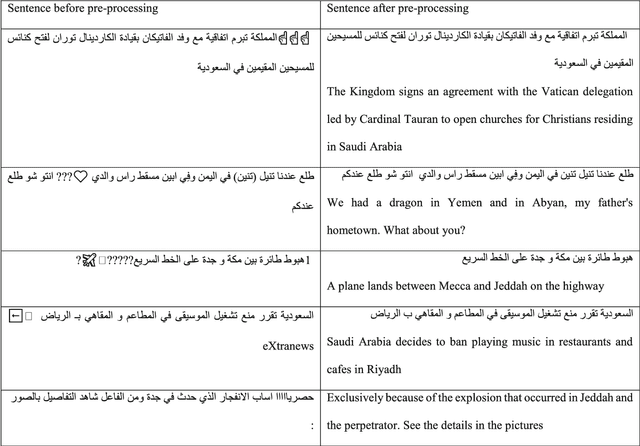
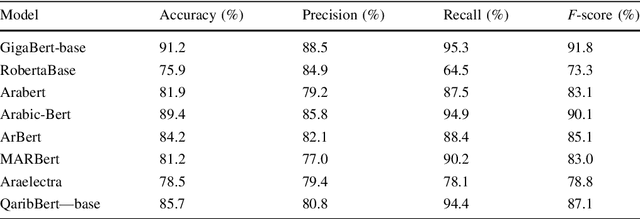
Social media is becoming a source of news for many people due to its ease and freedom of use. As a result, fake news has been spreading quickly and easily regardless of its credibility, especially in the last decade. Fake news publishers take advantage of critical situations such as the Covid-19 pandemic and the American presidential elections to affect societies negatively. Fake news can seriously impact society in many fields including politics, finance, sports, etc. Many studies have been conducted to help detect fake news in English, but research conducted on fake news detection in the Arabic language is scarce. Our contribution is twofold: first, we have constructed a large and diverse Arabic fake news dataset. Second, we have developed and evaluated transformer-based classifiers to identify fake news while utilizing eight state-of-the-art Arabic contextualized embedding models. The majority of these models had not been previously used for Arabic fake news detection. We conduct a thorough analysis of the state-of-the-art Arabic contextualized embedding models as well as comparison with similar fake news detection systems. Experimental results confirm that these state-of-the-art models are robust, with accuracy exceeding 98%.
Emotional Speaker Identification using a Novel Capsule Nets Model
Jan 09, 2022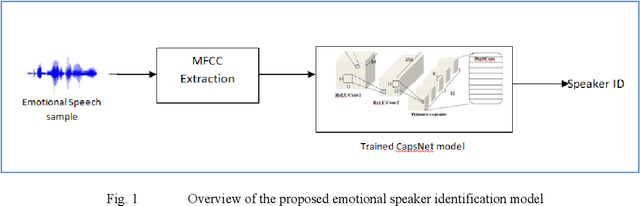

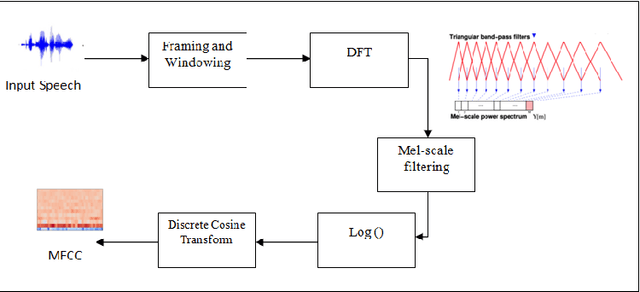
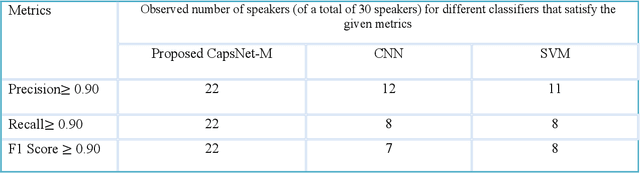
Speaker recognition systems are widely used in various applications to identify a person by their voice; however, the high degree of variability in speech signals makes this a challenging task. Dealing with emotional variations is very difficult because emotions alter the voice characteristics of a person; thus, the acoustic features differ from those used to train models in a neutral environment. Therefore, speaker recognition models trained on neutral speech fail to correctly identify speakers under emotional stress. Although considerable advancements in speaker identification have been made using convolutional neural networks (CNN), CNNs cannot exploit the spatial association between low-level features. Inspired by the recent introduction of capsule networks (CapsNets), which are based on deep learning to overcome the inadequacy of CNNs in preserving the pose relationship between low-level features with their pooling technique, this study investigates the performance of using CapsNets in identifying speakers from emotional speech recordings. A CapsNet-based speaker identification model is proposed and evaluated using three distinct speech databases, i.e., the Emirati Speech Database, SUSAS Dataset, and RAVDESS (open-access). The proposed model is also compared to baseline systems. Experimental results demonstrate that the novel proposed CapsNet model trains faster and provides better results over current state-of-the-art schemes. The effect of the routing algorithm on speaker identification performance was also studied by varying the number of iterations, both with and without a decoder network.
Novel Hybrid DNN Approaches for Speaker Verification in Emotional and Stressful Talking Environments
Dec 26, 2021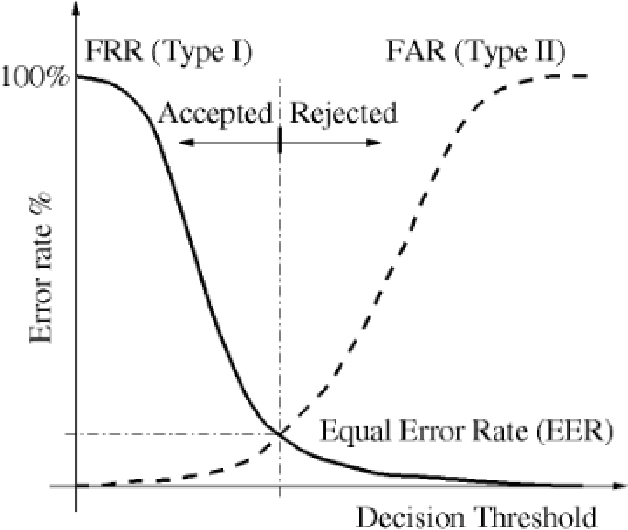
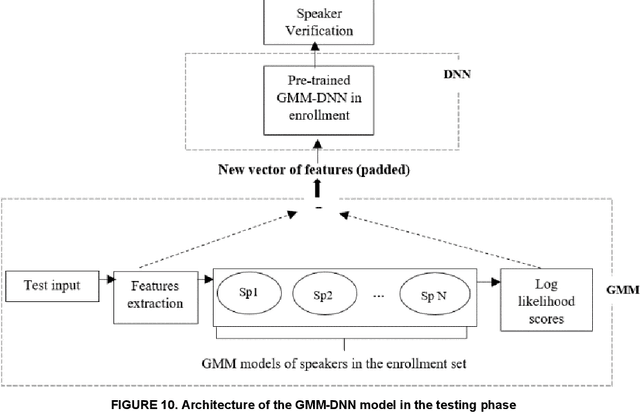
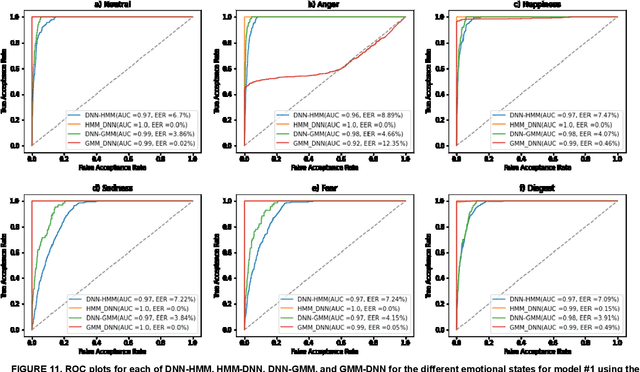
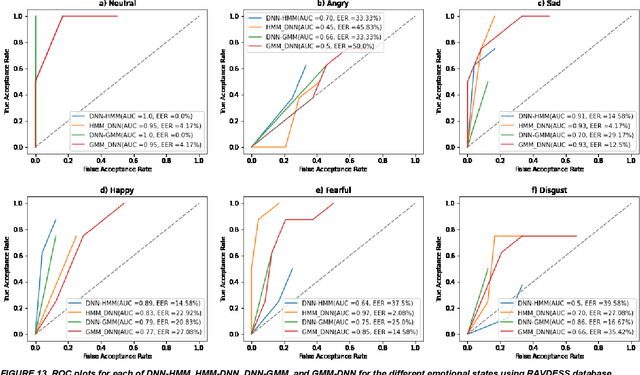
In this work, we conducted an empirical comparative study of the performance of text-independent speaker verification in emotional and stressful environments. This work combined deep models with shallow architecture, which resulted in novel hybrid classifiers. Four distinct hybrid models were utilized: deep neural network-hidden Markov model (DNN-HMM), deep neural network-Gaussian mixture model (DNN-GMM), Gaussian mixture model-deep neural network (GMM-DNN), and hidden Markov model-deep neural network (HMM-DNN). All models were based on novel implemented architecture. The comparative study used three distinct speech datasets: a private Arabic dataset and two public English databases, namely, Speech Under Simulated and Actual Stress (SUSAS) and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). The test results of the aforementioned hybrid models demonstrated that the proposed HMM-DNN leveraged the verification performance in emotional and stressful environments. Results also showed that HMM-DNN outperformed all other hybrid models in terms of equal error rate (EER) and area under the curve (AUC) evaluation metrics. The average resulting verification system based on the three datasets yielded EERs of 7.19%, 16.85%, 11.51%, and 11.90% based on HMM-DNN, DNN-HMM, DNN-GMM, and GMM-DNN, respectively. Furthermore, we found that the DNN-GMM model demonstrated the least computational complexity compared to all other hybrid models in both talking environments. Conversely, the HMM-DNN model required the greatest amount of training time. Findings also demonstrated that EER and AUC values depended on the database when comparing average emotional and stressful performances.
* 23 pages, 13 figures
Empirical evaluation of shallow and deep learning classifiers for Arabic sentiment analysis
Dec 01, 2021
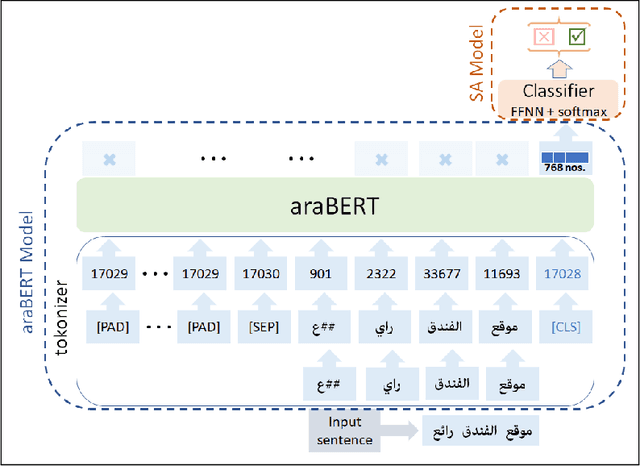


This work presents a detailed comparison of the performance of deep learning models such as convolutional neural networks (CNN), long short-term memory (LSTM), gated recurrent units (GRU), their hybrids, and a selection of shallow learning classifiers for sentiment analysis of Arabic reviews. Additionally, the comparison includes state-of-the-art models such as the transformer architecture and the araBERT pre-trained model. The datasets used in this study are multi-dialect Arabic hotel and book review datasets, which are some of the largest publicly available datasets for Arabic reviews. Results showed deep learning outperforming shallow learning for binary and multi-label classification, in contrast with the results of similar work reported in the literature. This discrepancy in outcome was caused by dataset size as we found it to be proportional to the performance of deep learning models. The performance of deep and shallow learning techniques was analyzed in terms of accuracy and F1 score. The best performing shallow learning technique was Random Forest followed by Decision Tree, and AdaBoost. The deep learning models performed similarly using a default embedding layer, while the transformer model performed best when augmented with araBERT.
Kernel density estimation-based sampling for neural network classification
Oct 25, 2021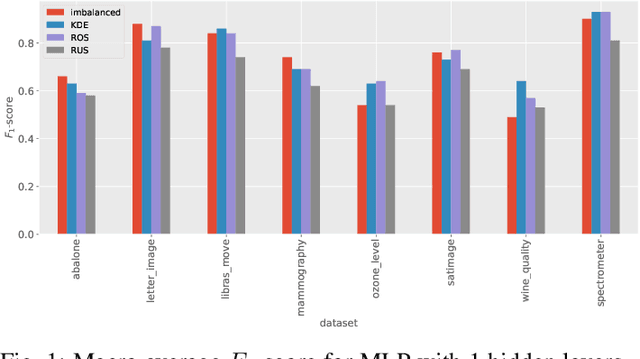

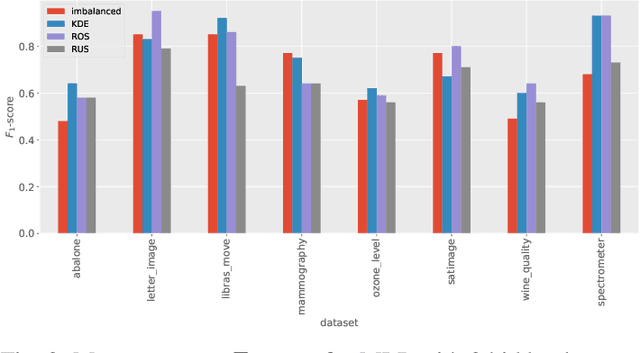
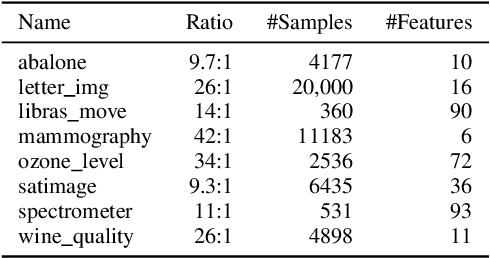
Imbalanced data occurs in a wide range of scenarios. The skewed distribution of the target variable elicits bias in machine learning algorithms. One of the popular methods to combat imbalanced data is to artificially balance the data through resampling. In this paper, we compare the efficacy of a recently proposed kernel density estimation (KDE) sampling technique in the context of artificial neural networks. We benchmark the KDE sampling method against two base sampling techniques and perform comparative experiments using 8 datasets and 3 neural networks architectures. The results show that KDE sampling produces the best performance on 6 out of 8 datasets. However, it must be used with caution on image datasets. We conclude that KDE sampling is capable of significantly improving the performance of neural networks.