 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization Algorithms in Smart Grids: A Systematic Literature Review
Jan 16, 2023Electrical smart grids are units that supply electricity from power plants to the users to yield reduced costs, power failures/loss, and maximized energy management. Smart grids (SGs) are well-known devices due to their exceptional benefits such as bi-directional communication, stability, detection of power failures, and inter-connectivity with appliances for monitoring purposes. SGs are the outcome of different modern applications that are used for managing data and security, i.e., modeling, monitoring, optimization, and/or Artificial Intelligence. Hence, the importance of SGs as a research field is increasing with every passing year. This paper focuses on novel features and applications of smart grids in domestic and industrial sectors. Specifically, we focused on Genetic algorithm, Particle Swarm Optimization, and Grey Wolf Optimization to study the efforts made up till date for maximized energy management and cost minimization in SGs. Therefore, we collected 145 research works (2011 to 2022) in this systematic literature review. This research work aims to figure out different features and applications of SGs proposed in the last decade and investigate the trends in popularity of SGs for different regions of world. Our finding is that the most popular optimization algorithm being used by researchers to bring forward new solutions for energy management and cost effectiveness in SGs is Particle Swarm Optimization. We also provide a brief overview of objective functions and parameters used in the solutions for energy and cost effectiveness as well as discuss different open research challenges for future research works.
Arabic Fake News Detection Based on Deep Contextualized Embedding Models
May 06, 2022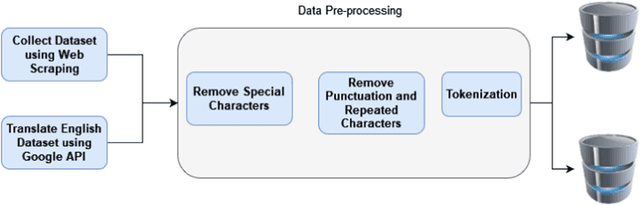
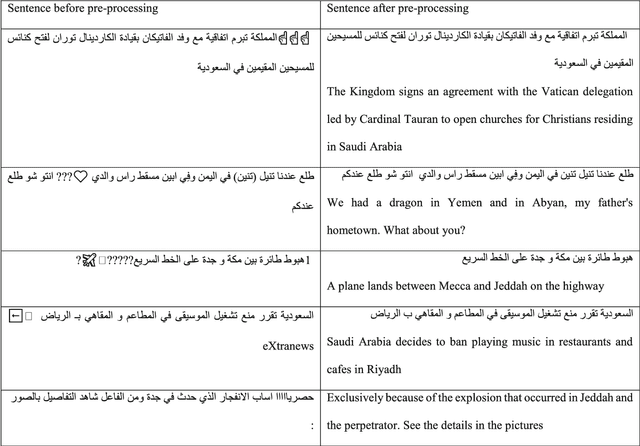
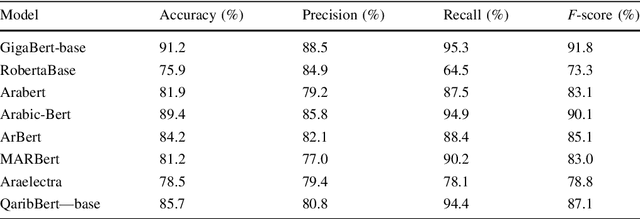
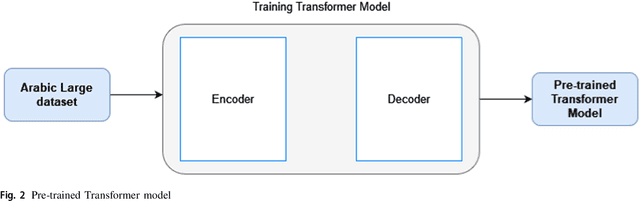
Social media is becoming a source of news for many people due to its ease and freedom of use. As a result, fake news has been spreading quickly and easily regardless of its credibility, especially in the last decade. Fake news publishers take advantage of critical situations such as the Covid-19 pandemic and the American presidential elections to affect societies negatively. Fake news can seriously impact society in many fields including politics, finance, sports, etc. Many studies have been conducted to help detect fake news in English, but research conducted on fake news detection in the Arabic language is scarce. Our contribution is twofold: first, we have constructed a large and diverse Arabic fake news dataset. Second, we have developed and evaluated transformer-based classifiers to identify fake news while utilizing eight state-of-the-art Arabic contextualized embedding models. The majority of these models had not been previously used for Arabic fake news detection. We conduct a thorough analysis of the state-of-the-art Arabic contextualized embedding models as well as comparison with similar fake news detection systems. Experimental results confirm that these state-of-the-art models are robust, with accuracy exceeding 98%.
Transformation Invariant Cancerous Tissue Classification Using Spatially Transformed DenseNet
Apr 23, 2022


In this work, we introduce a spatially transformed DenseNet architecture for transformation invariant classification of cancer tissue. Our architecture increases the accuracy of the base DenseNet architecture while adding the ability to operate in a transformation invariant way while simultaneously being simpler than other models that try to provide some form of invariance.
Breast cancer detection using artificial intelligence techniques: A systematic literature review
Mar 08, 2022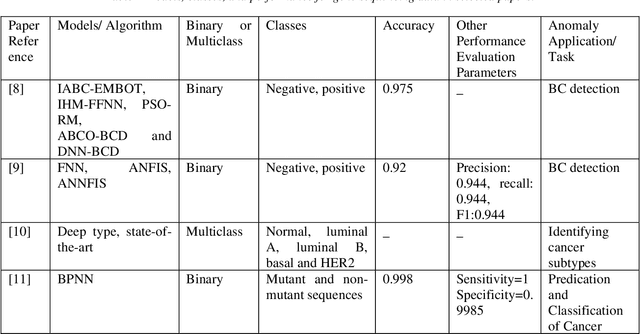
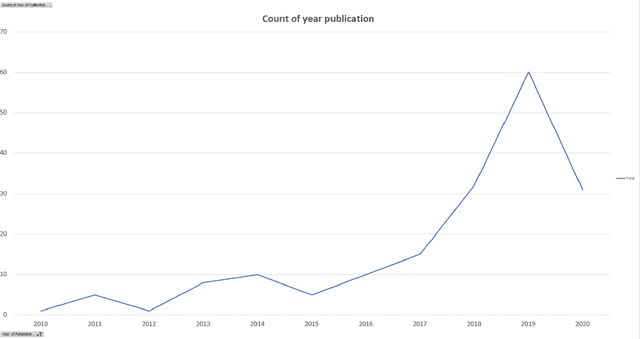
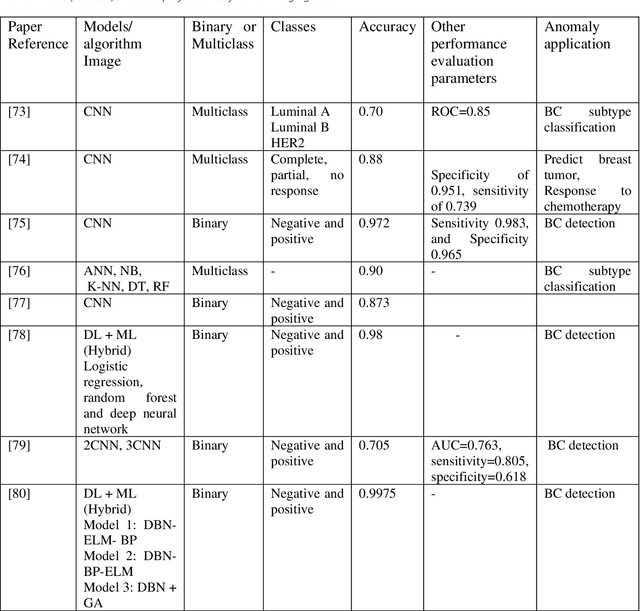
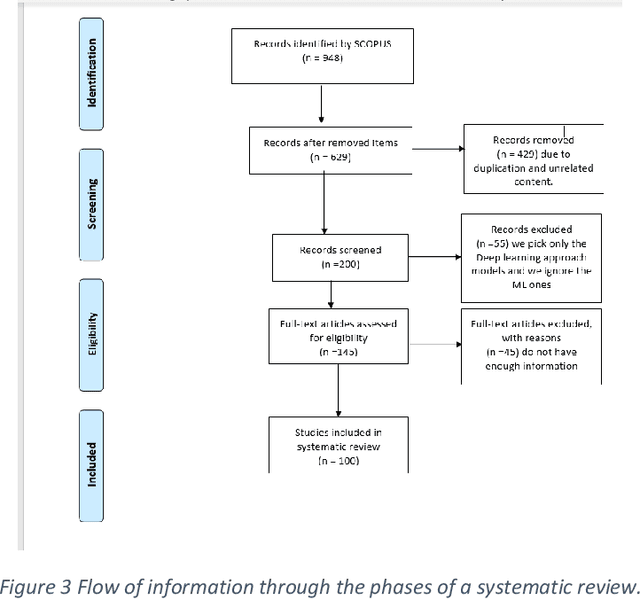
Cancer is one of the most dangerous diseases to humans, and yet no permanent cure has been developed for it. Breast cancer is one of the most common cancer types. According to the National Breast Cancer foundation, in 2020 alone, more than 276,000 new cases of invasive breast cancer and more than 48,000 non-invasive cases were diagnosed in the US. To put these figures in perspective, 64% of these cases are diagnosed early in the disease's cycle, giving patients a 99% chance of survival. Artificial intelligence and machine learning have been used effectively in detection and treatment of several dangerous diseases, helping in early diagnosis and treatment, and thus increasing the patient's chance of survival. Deep learning has been designed to analyze the most important features affecting detection and treatment of serious diseases. For example, breast cancer can be detected using genes or histopathological imaging. Analysis at the genetic level is very expensive, so histopathological imaging is the most common approach used to detect breast cancer. In this research work, we systematically reviewed previous work done on detection and treatment of breast cancer using genetic sequencing or histopathological imaging with the help of deep learning and machine learning. We also provide recommendations to researchers who will work in this field
Emotional Speaker Identification using a Novel Capsule Nets Model
Jan 09, 2022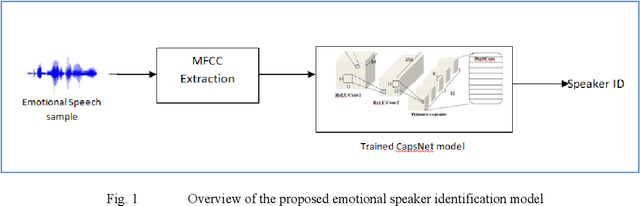

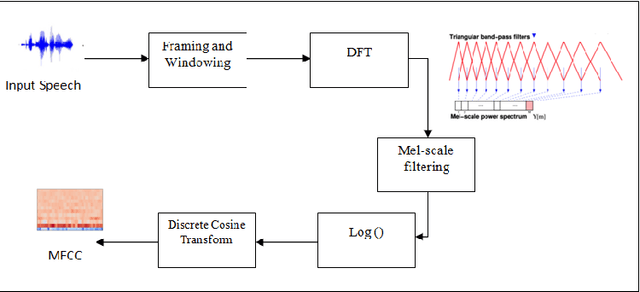
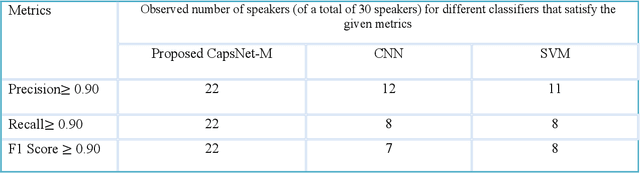
Speaker recognition systems are widely used in various applications to identify a person by their voice; however, the high degree of variability in speech signals makes this a challenging task. Dealing with emotional variations is very difficult because emotions alter the voice characteristics of a person; thus, the acoustic features differ from those used to train models in a neutral environment. Therefore, speaker recognition models trained on neutral speech fail to correctly identify speakers under emotional stress. Although considerable advancements in speaker identification have been made using convolutional neural networks (CNN), CNNs cannot exploit the spatial association between low-level features. Inspired by the recent introduction of capsule networks (CapsNets), which are based on deep learning to overcome the inadequacy of CNNs in preserving the pose relationship between low-level features with their pooling technique, this study investigates the performance of using CapsNets in identifying speakers from emotional speech recordings. A CapsNet-based speaker identification model is proposed and evaluated using three distinct speech databases, i.e., the Emirati Speech Database, SUSAS Dataset, and RAVDESS (open-access). The proposed model is also compared to baseline systems. Experimental results demonstrate that the novel proposed CapsNet model trains faster and provides better results over current state-of-the-art schemes. The effect of the routing algorithm on speaker identification performance was also studied by varying the number of iterations, both with and without a decoder network.
Artificial Intelligence and Statistical Techniques in Short-Term Load Forecasting: A Review
Dec 29, 2021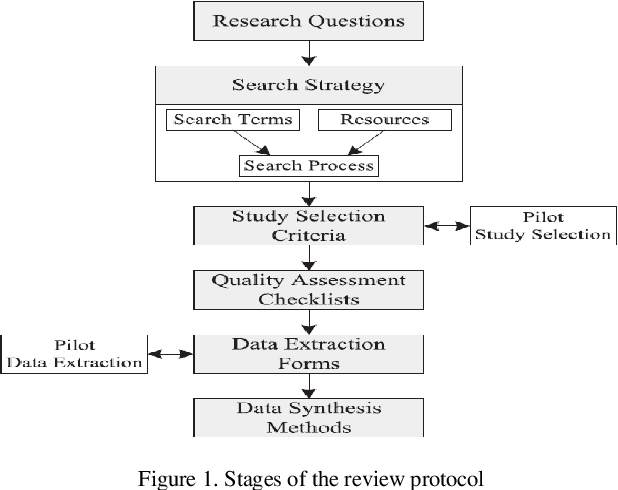
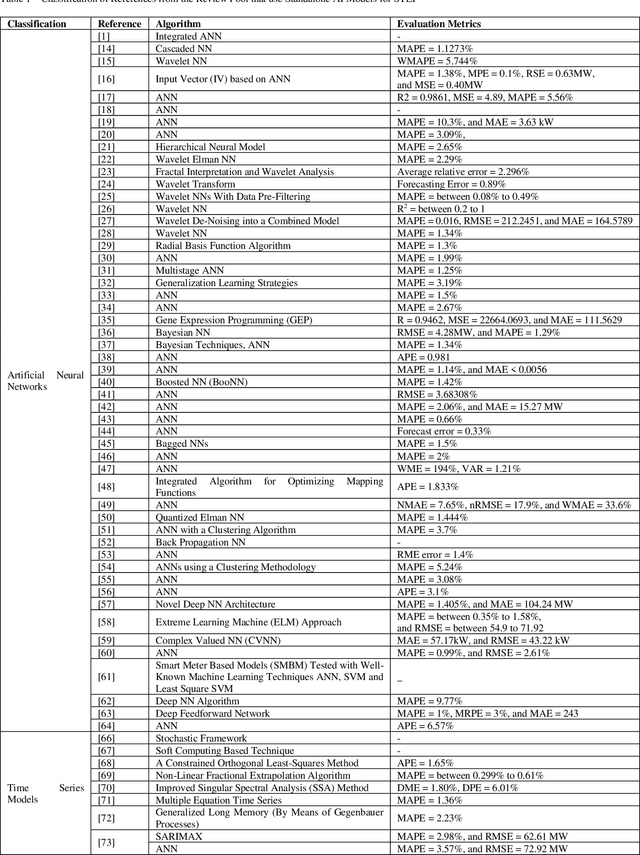
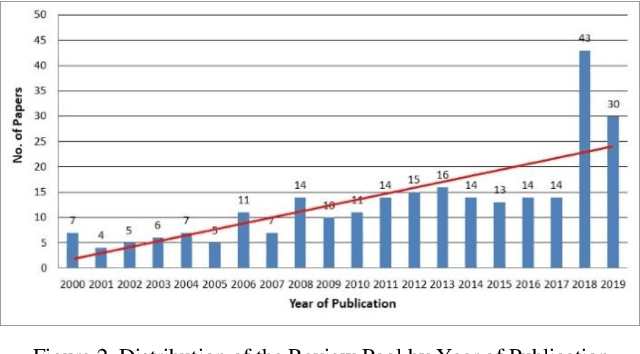
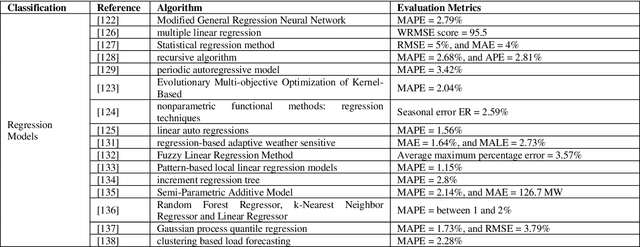
Electrical utilities depend on short-term demand forecasting to proactively adjust production and distribution in anticipation of major variations. This systematic review analyzes 240 works published in scholarly journals between 2000 and 2019 that focus on applying Artificial Intelligence (AI), statistical, and hybrid models to short-term load forecasting (STLF). This work represents the most comprehensive review of works on this subject to date. A complete analysis of the literature is conducted to identify the most popular and accurate techniques as well as existing gaps. The findings show that although Artificial Neural Networks (ANN) continue to be the most commonly used standalone technique, researchers have been exceedingly opting for hybrid combinations of different techniques to leverage the combined advantages of individual methods. The review demonstrates that it is commonly possible with these hybrid combinations to achieve prediction accuracy exceeding 99%. The most successful duration for short-term forecasting has been identified as prediction for a duration of one day at an hourly interval. The review has identified a deficiency in access to datasets needed for training of the models. A significant gap has been identified in researching regions other than Asia, Europe, North America, and Australia.
Novel Hybrid DNN Approaches for Speaker Verification in Emotional and Stressful Talking Environments
Dec 26, 2021
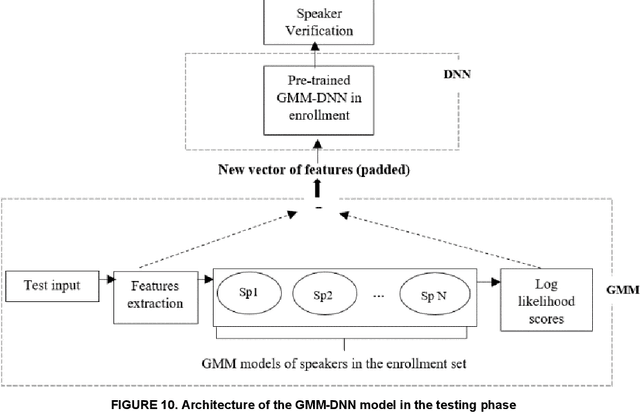
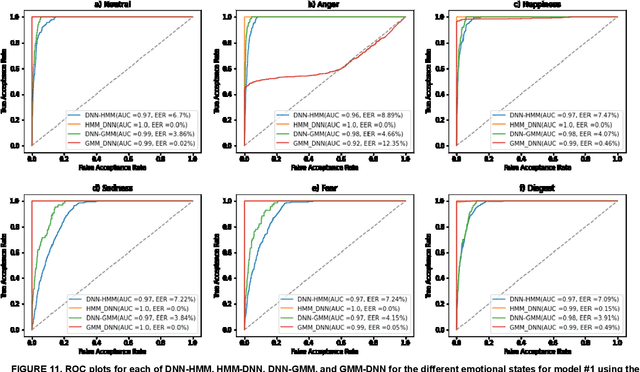
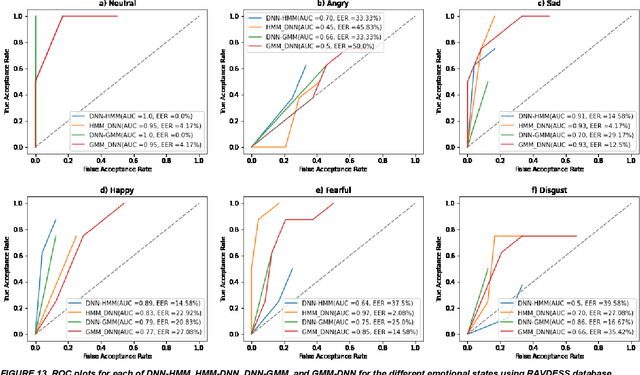
In this work, we conducted an empirical comparative study of the performance of text-independent speaker verification in emotional and stressful environments. This work combined deep models with shallow architecture, which resulted in novel hybrid classifiers. Four distinct hybrid models were utilized: deep neural network-hidden Markov model (DNN-HMM), deep neural network-Gaussian mixture model (DNN-GMM), Gaussian mixture model-deep neural network (GMM-DNN), and hidden Markov model-deep neural network (HMM-DNN). All models were based on novel implemented architecture. The comparative study used three distinct speech datasets: a private Arabic dataset and two public English databases, namely, Speech Under Simulated and Actual Stress (SUSAS) and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). The test results of the aforementioned hybrid models demonstrated that the proposed HMM-DNN leveraged the verification performance in emotional and stressful environments. Results also showed that HMM-DNN outperformed all other hybrid models in terms of equal error rate (EER) and area under the curve (AUC) evaluation metrics. The average resulting verification system based on the three datasets yielded EERs of 7.19%, 16.85%, 11.51%, and 11.90% based on HMM-DNN, DNN-HMM, DNN-GMM, and GMM-DNN, respectively. Furthermore, we found that the DNN-GMM model demonstrated the least computational complexity compared to all other hybrid models in both talking environments. Conversely, the HMM-DNN model required the greatest amount of training time. Findings also demonstrated that EER and AUC values depended on the database when comparing average emotional and stressful performances.
* 23 pages, 13 figures
Novel Dual-Channel Long Short-Term Memory Compressed Capsule Networks for Emotion Recognition
Dec 26, 2021
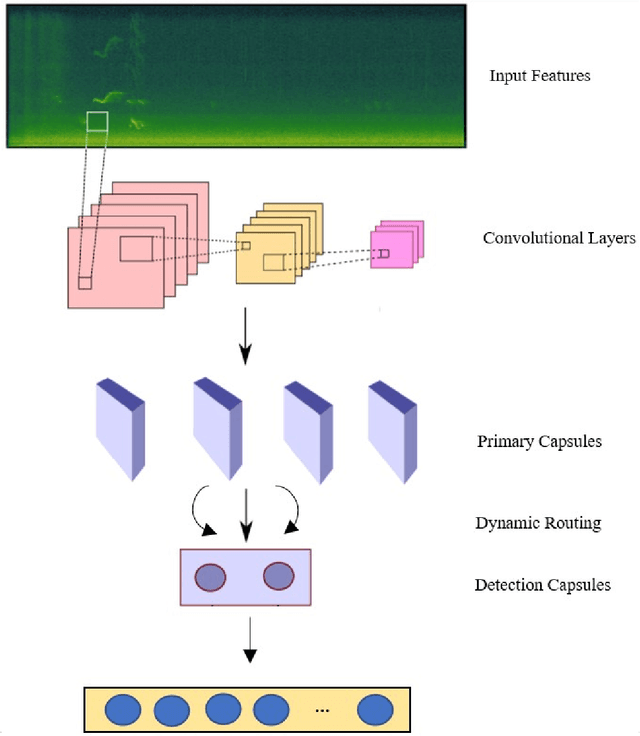
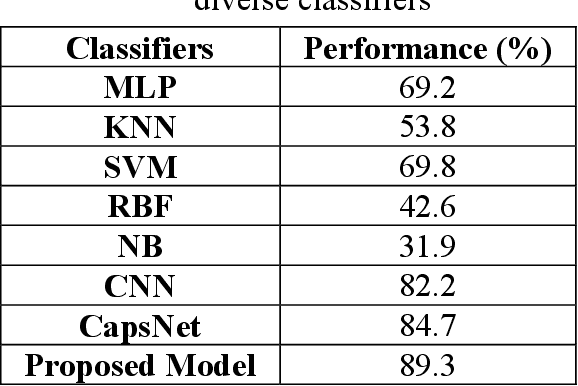
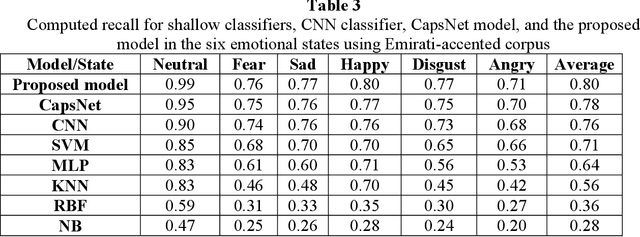
Recent analysis on speech emotion recognition has made considerable advances with the use of MFCCs spectrogram features and the implementation of neural network approaches such as convolutional neural networks (CNNs). Capsule networks (CapsNet) have gained gratitude as alternatives to CNNs with their larger capacities for hierarchical representation. To address these issues, this research introduces a text-independent and speaker-independent SER novel architecture, where a dual-channel long short-term memory compressed-CapsNet (DC-LSTM COMP-CapsNet) algorithm is proposed based on the structural features of CapsNet. Our proposed novel classifier can ensure the energy efficiency of the model and adequate compression method in speech emotion recognition, which is not delivered through the original structure of a CapsNet. Moreover, the grid search approach is used to attain optimal solutions. Results witnessed an improved performance and reduction in the training and testing running time. The speech datasets used to evaluate our algorithm are: Arabic Emirati-accented corpus, English speech under simulated and actual stress corpus, English Ryerson audio-visual database of emotional speech and song corpus, and crowd-sourced emotional multimodal actors dataset. This work reveals that the optimum feature extraction method compared to other known methods is MFCCs delta-delta. Using the four datasets and the MFCCs delta-delta, DC-LSTM COMP-CapsNet surpasses all the state-of-the-art systems, classical classifiers, CNN, and the original CapsNet. Using the Arabic Emirati-accented corpus, our results demonstrate that the proposed work yields average emotion recognition accuracy of 89.3% compared to 84.7%, 82.2%, 69.8%, 69.2%, 53.8%, 42.6%, and 31.9% based on CapsNet, CNN, support vector machine, multi-layer perceptron, k-nearest neighbor, radial basis function, and naive Bayes, respectively.
* 19 pages, 11 figures
COVID-19 Electrocardiograms Classification using CNN Models
Dec 15, 2021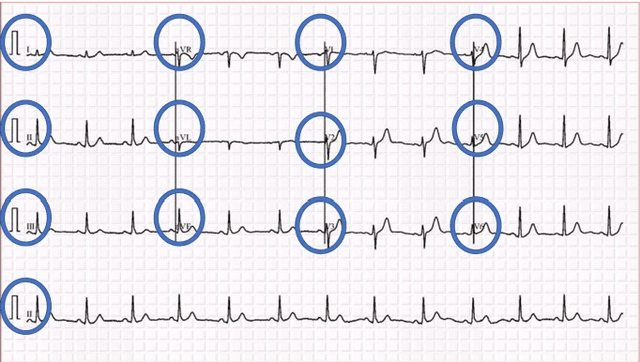
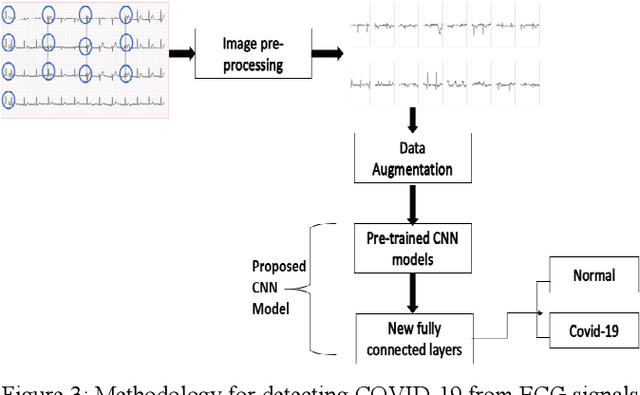
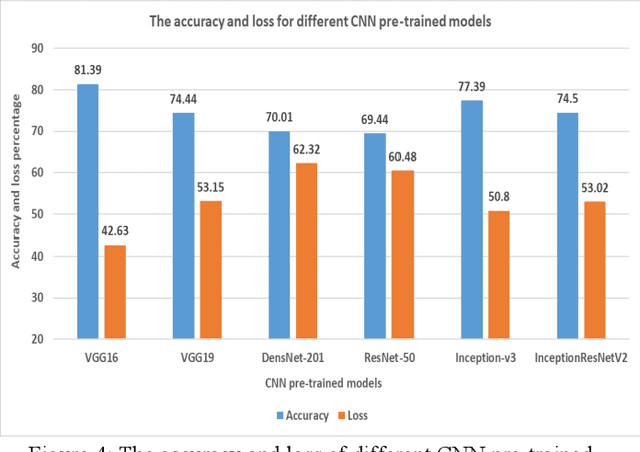
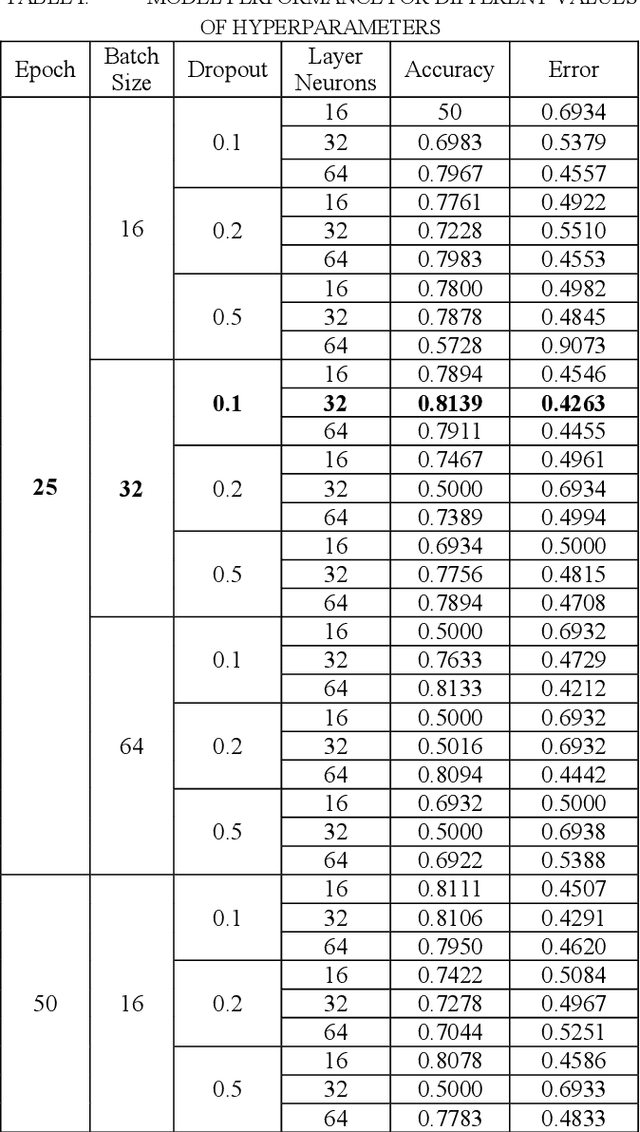
With the periodic rise and fall of COVID-19 and numerous countries being affected by its ramifications, there has been a tremendous amount of work that has been done by scientists, researchers, and doctors all over the world. Prompt intervention is keenly needed to tackle the unconscionable dissemination of the disease. The implementation of Artificial Intelligence (AI) has made a significant contribution to the digital health district by applying the fundamentals of deep learning algorithms. In this study, a novel approach is proposed to automatically diagnose the COVID-19 by the utilization of Electrocardiogram (ECG) data with the integration of deep learning algorithms, specifically the Convolutional Neural Network (CNN) models. Several CNN models have been utilized in this proposed framework, including VGG16, VGG19, InceptionResnetv2, InceptionV3, Resnet50, and Densenet201. The VGG16 model has outperformed the rest of the models, with an accuracy of 85.92%. Our results show a relatively low accuracy in the rest of the models compared to the VGG16 model, which is due to the small size of the utilized dataset, in addition to the exclusive utilization of the Grid search hyperparameters optimization approach for the VGG16 model only. Moreover, our results are preparatory, and there is a possibility to enhance the accuracy of all models by further expanding the dataset and adapting a suitable hyperparameters optimization technique.
The exploitation of Multiple Feature Extraction Techniques for Speaker Identification in Emotional States under Disguised Voices
Dec 15, 2021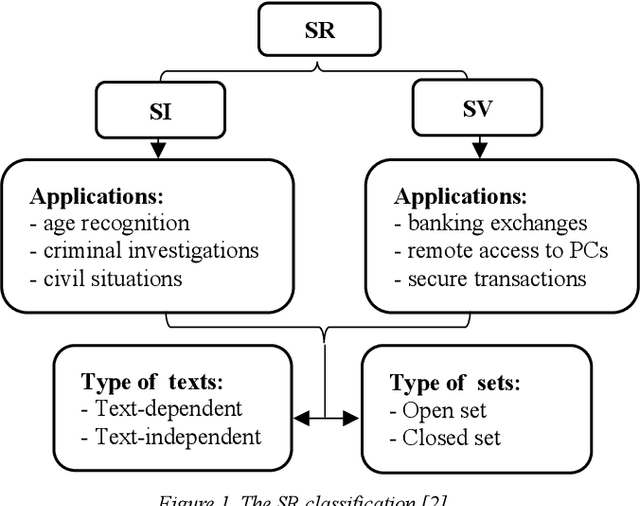

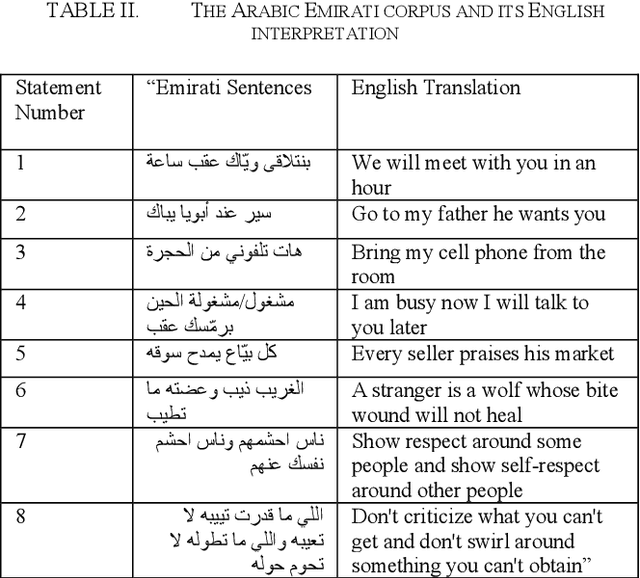
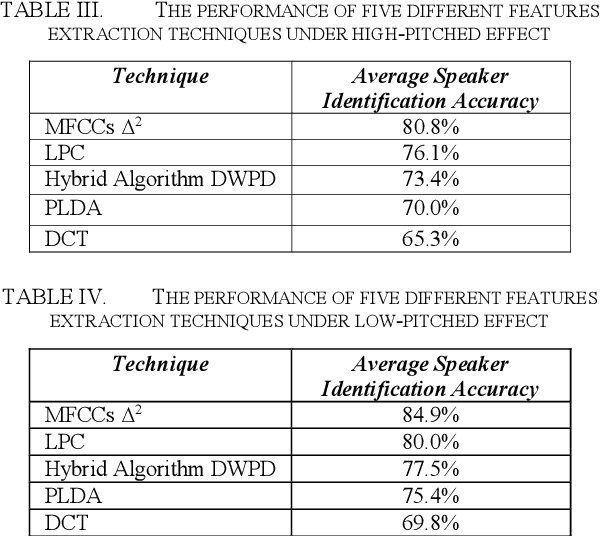
Due to improvements in artificial intelligence, speaker identification (SI) technologies have brought a great direction and are now widely used in a variety of sectors. One of the most important components of SI is feature extraction, which has a substantial impact on the SI process and performance. As a result, numerous feature extraction strategies are thoroughly investigated, contrasted, and analyzed. This article exploits five distinct feature extraction methods for speaker identification in disguised voices under emotional environments. To evaluate this work significantly, three effects are used: high-pitched, low-pitched, and Electronic Voice Conversion (EVC). Experimental results reported that the concatenated Mel-Frequency Cepstral Coefficients (MFCCs), MFCCs-delta, and MFCCs-delta-delta is the best feature extraction method.