 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Dual-Channel Long Short-Term Memory Compressed Capsule Networks for Emotion Recognition
Dec 26, 2021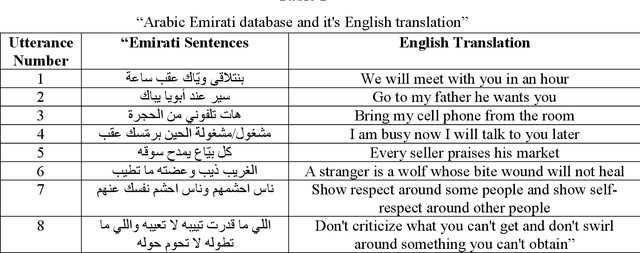
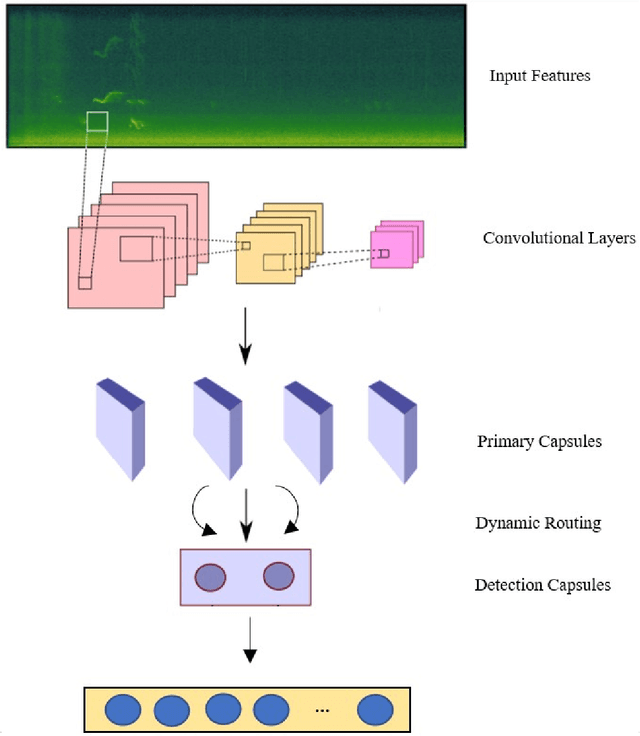
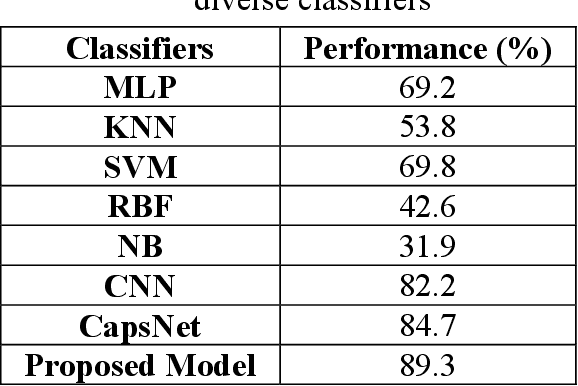
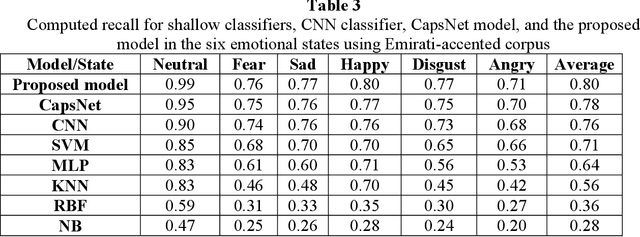
Recent analysis on speech emotion recognition has made considerable advances with the use of MFCCs spectrogram features and the implementation of neural network approaches such as convolutional neural networks (CNNs). Capsule networks (CapsNet) have gained gratitude as alternatives to CNNs with their larger capacities for hierarchical representation. To address these issues, this research introduces a text-independent and speaker-independent SER novel architecture, where a dual-channel long short-term memory compressed-CapsNet (DC-LSTM COMP-CapsNet) algorithm is proposed based on the structural features of CapsNet. Our proposed novel classifier can ensure the energy efficiency of the model and adequate compression method in speech emotion recognition, which is not delivered through the original structure of a CapsNet. Moreover, the grid search approach is used to attain optimal solutions. Results witnessed an improved performance and reduction in the training and testing running time. The speech datasets used to evaluate our algorithm are: Arabic Emirati-accented corpus, English speech under simulated and actual stress corpus, English Ryerson audio-visual database of emotional speech and song corpus, and crowd-sourced emotional multimodal actors dataset. This work reveals that the optimum feature extraction method compared to other known methods is MFCCs delta-delta. Using the four datasets and the MFCCs delta-delta, DC-LSTM COMP-CapsNet surpasses all the state-of-the-art systems, classical classifiers, CNN, and the original CapsNet. Using the Arabic Emirati-accented corpus, our results demonstrate that the proposed work yields average emotion recognition accuracy of 89.3% compared to 84.7%, 82.2%, 69.8%, 69.2%, 53.8%, 42.6%, and 31.9% based on CapsNet, CNN, support vector machine, multi-layer perceptron, k-nearest neighbor, radial basis function, and naive Bayes, respectively.
* 19 pages, 11 figures