 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Hybrid DNN Approaches for Speaker Verification in Emotional and Stressful Talking Environments
Dec 26, 2021
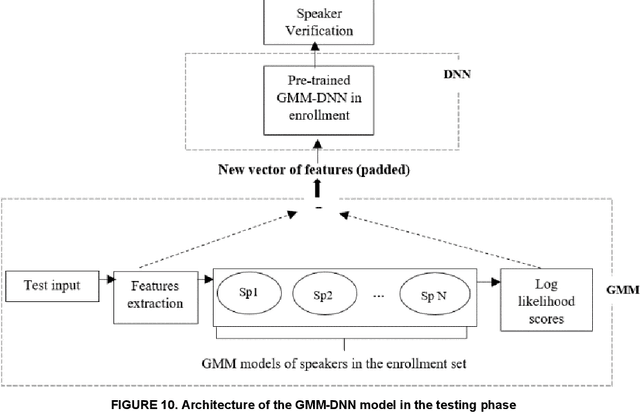
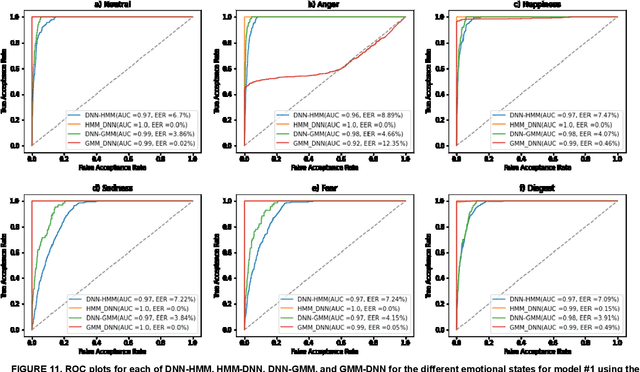
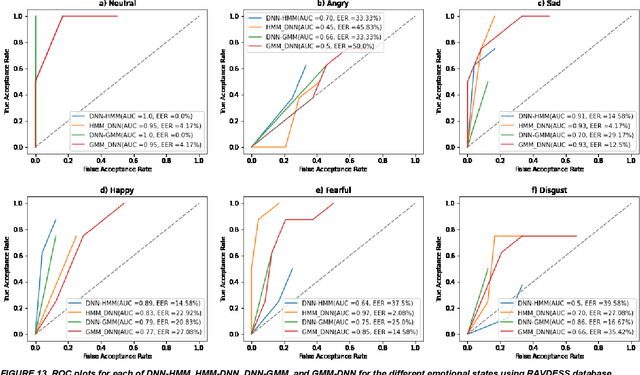
In this work, we conducted an empirical comparative study of the performance of text-independent speaker verification in emotional and stressful environments. This work combined deep models with shallow architecture, which resulted in novel hybrid classifiers. Four distinct hybrid models were utilized: deep neural network-hidden Markov model (DNN-HMM), deep neural network-Gaussian mixture model (DNN-GMM), Gaussian mixture model-deep neural network (GMM-DNN), and hidden Markov model-deep neural network (HMM-DNN). All models were based on novel implemented architecture. The comparative study used three distinct speech datasets: a private Arabic dataset and two public English databases, namely, Speech Under Simulated and Actual Stress (SUSAS) and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). The test results of the aforementioned hybrid models demonstrated that the proposed HMM-DNN leveraged the verification performance in emotional and stressful environments. Results also showed that HMM-DNN outperformed all other hybrid models in terms of equal error rate (EER) and area under the curve (AUC) evaluation metrics. The average resulting verification system based on the three datasets yielded EERs of 7.19%, 16.85%, 11.51%, and 11.90% based on HMM-DNN, DNN-HMM, DNN-GMM, and GMM-DNN, respectively. Furthermore, we found that the DNN-GMM model demonstrated the least computational complexity compared to all other hybrid models in both talking environments. Conversely, the HMM-DNN model required the greatest amount of training time. Findings also demonstrated that EER and AUC values depended on the database when comparing average emotional and stressful performances.
* 23 pages, 13 figures
CASA-Based Speaker Identification Using Cascaded GMM-CNN Classifier in Noisy and Emotional Talking Conditions
Feb 11, 2021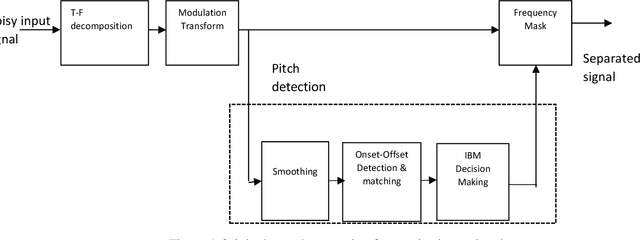
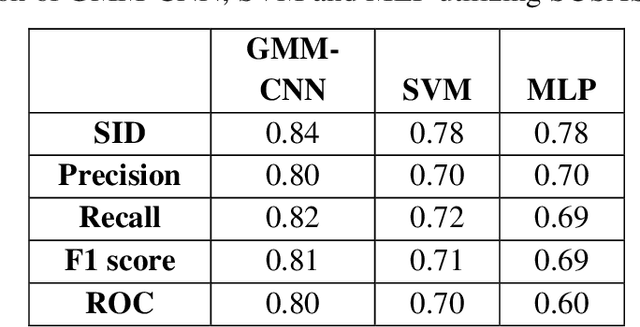
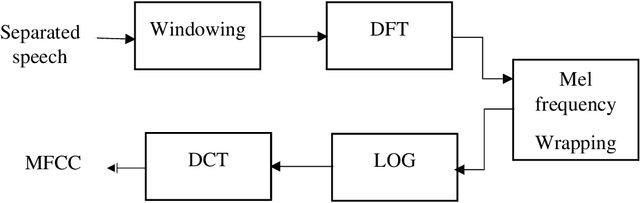
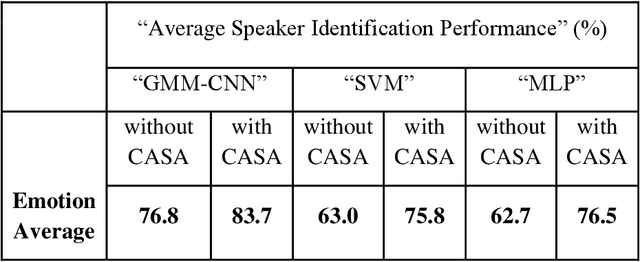
This work aims at intensifying text-independent speaker identification performance in real application situations such as noisy and emotional talking conditions. This is achieved by incorporating two different modules: a Computational Auditory Scene Analysis CASA based pre-processing module for noise reduction and cascaded Gaussian Mixture Model Convolutional Neural Network GMM-CNN classifier for speaker identification followed by emotion recognition. This research proposes and evaluates a novel algorithm to improve the accuracy of speaker identification in emotional and highly-noise susceptible conditions. Experiments demonstrate that the proposed model yields promising results in comparison with other classifiers when Speech Under Simulated and Actual Stress SUSAS database, Emirati Speech Database ESD, the Ryerson Audio-Visual Database of Emotional Speech and Song RAVDESS database and the Fluent Speech Commands database are used in a noisy environment.
* Published in Applied Soft Computing journal