 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Machine Learning for Online Reputation Systems
Sep 10, 2022Users on the internet usually require venues to provide better purchasing recommendations. This can be provided by a reputation system that processes ratings to provide recommendations. The rating aggregation process is a main part of reputation system to produce global opinion about the product quality. Naive methods that are frequently used do not consider consumer profiles in its calculation and cannot discover unfair ratings and trends emerging in new ratings. Other sophisticated rating aggregation methods that use weighted average technique focus on one or a few aspects of consumers profile data. This paper proposes a new reputation system using machine learning to predict reliability of consumers from consumer profile. In particular, we construct a new consumer profile dataset by extracting a set of factors that have great impact on consumer reliability, which serve as an input to machine learning algorithms. The predicted weight is then integrated with a weighted average method to compute product reputation score. The proposed model has been evaluated over three MovieLens benchmarking datasets, using 10-Folds cross validation. Furthermore, the performance of the proposed model has been compared to previous published rating aggregation models. The obtained results were promising which suggest that the proposed approach could be a potential solution for reputation systems. The results of comparison demonstrated the accuracy of our models. Finally, the proposed approach can be integrated with online recommendation systems to provide better purchasing recommendations and facilitate user experience on online shopping markets.
An Interactive Automation for Human Biliary Tree Diagnosis Using Computer Vision
Sep 10, 2022



The biliary tree is a network of tubes that connects the liver to the gallbladder, an organ right beneath it. The bile duct is the major tube in the biliary tree. The dilatation of a bile duct is a key indicator for more major problems in the human body, such as stones and tumors, which are frequently caused by the pancreas or the papilla of vater. The detection of bile duct dilatation can be challenging for beginner or untrained medical personnel in many circumstances. Even professionals are unable to detect bile duct dilatation with the naked eye. This research presents a unique vision-based model for biliary tree initial diagnosis. To segment the biliary tree from the Magnetic Resonance Image, the framework used different image processing approaches (MRI). After the image's region of interest was segmented, numerous calculations were performed on it to extract 10 features, including major and minor axes, bile duct area, biliary tree area, compactness, and some textural features (contrast, mean, variance and correlation). This study used a database of images from King Hussein Medical Center in Amman, Jordan, which included 200 MRI images, 100 normal cases, and 100 patients with dilated bile ducts. After the characteristics are extracted, various classifiers are used to determine the patients' condition in terms of their health (normal or dilated). The findings demonstrate that the extracted features perform well with all classifiers in terms of accuracy and area under the curve. This study is unique in that it uses an automated approach to segment the biliary tree from MRI images, as well as scientifically correlating retrieved features with biliary tree status that has never been done before in the literature.
Examining stability of machine learning methods for predicting dementia at early phases of the disease
Sep 10, 2022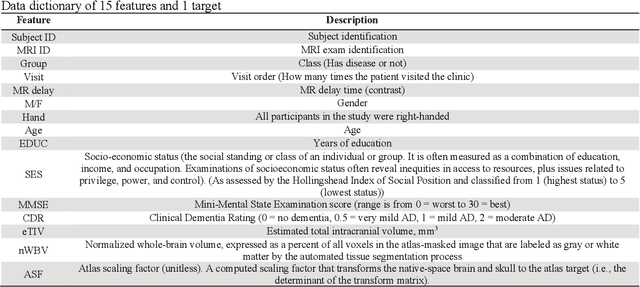
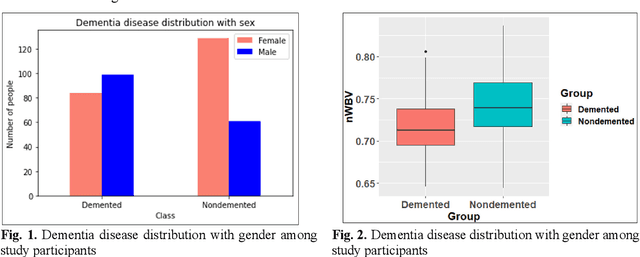
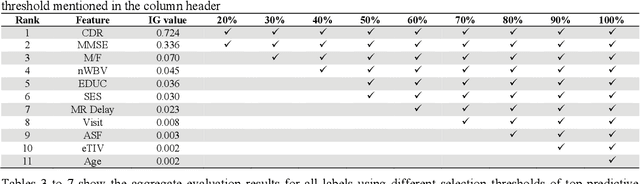
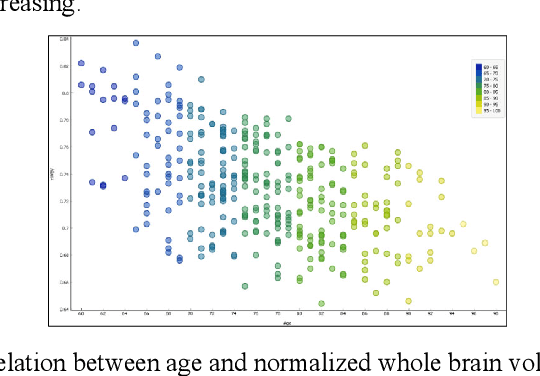
Dementia is a neuropsychiatric brain disorder that usually occurs when one or more brain cells stop working partially or at all. Diagnosis of this disorder in the early phases of the disease is a vital task to rescue patients lives from bad consequences and provide them with better healthcare. Machine learning methods have been proven to be accurate in predicting dementia in the early phases of the disease. The prediction of dementia depends heavily on the type of collected data which usually are gathered from Normalized Whole Brain Volume (nWBV) and Atlas Scaling Factor (ASF) which are normally measured and corrected from Magnetic Resonance Imaging (MRIs). Other biological features such as age and gender can also help in the diagnosis of dementia. Although many studies use machine learning for predicting dementia, we could not reach a conclusion on the stability of these methods for which one is more accurate under different experimental conditions. Therefore, this paper investigates the conclusion stability regarding the performance of machine learning algorithms for dementia prediction. To accomplish this, a large number of experiments were run using 7 machine learning algorithms and two feature reduction algorithms namely, Information Gain (IG) and Principal Component Analysis (PCA). To examine the stability of these algorithms, thresholds of feature selection were changed for the IG from 20% to 100% and the PCA dimension from 2 to 8. This has resulted in 7x9 + 7x7= 112 experiments. In each experiment, various classification evaluation data were recorded. The obtained results show that among seven algorithms the support vector machine and Naive Bayes are the most stable algorithms while changing the selection threshold. Also, it was found that using IG would seem more efficient than using PCA for predicting Dementia.
Artificial Intelligence and Statistical Techniques in Short-Term Load Forecasting: A Review
Dec 29, 2021
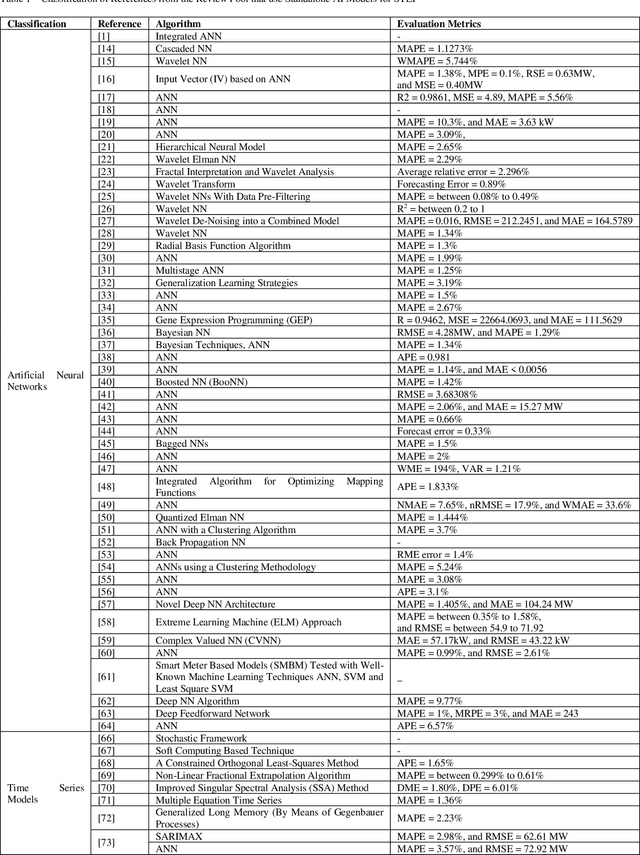
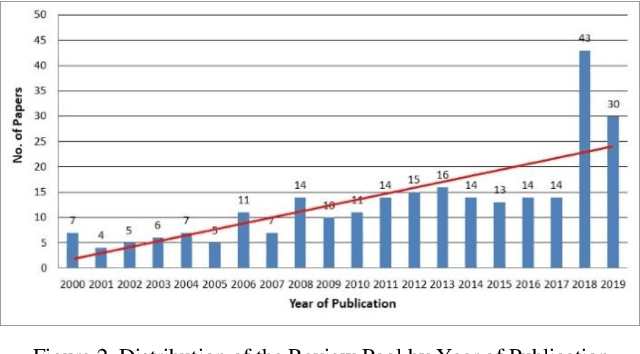
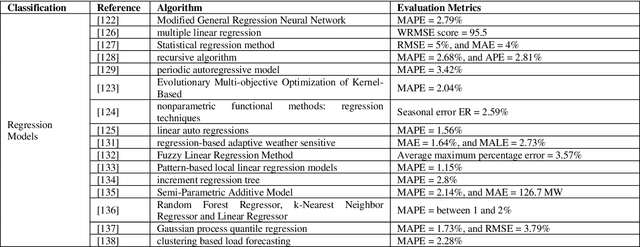
Electrical utilities depend on short-term demand forecasting to proactively adjust production and distribution in anticipation of major variations. This systematic review analyzes 240 works published in scholarly journals between 2000 and 2019 that focus on applying Artificial Intelligence (AI), statistical, and hybrid models to short-term load forecasting (STLF). This work represents the most comprehensive review of works on this subject to date. A complete analysis of the literature is conducted to identify the most popular and accurate techniques as well as existing gaps. The findings show that although Artificial Neural Networks (ANN) continue to be the most commonly used standalone technique, researchers have been exceedingly opting for hybrid combinations of different techniques to leverage the combined advantages of individual methods. The review demonstrates that it is commonly possible with these hybrid combinations to achieve prediction accuracy exceeding 99%. The most successful duration for short-term forecasting has been identified as prediction for a duration of one day at an hourly interval. The review has identified a deficiency in access to datasets needed for training of the models. A significant gap has been identified in researching regions other than Asia, Europe, North America, and Australia.
Ensemble of Learning Project Productivity in Software Effort Based on Use Case Points
Dec 16, 2018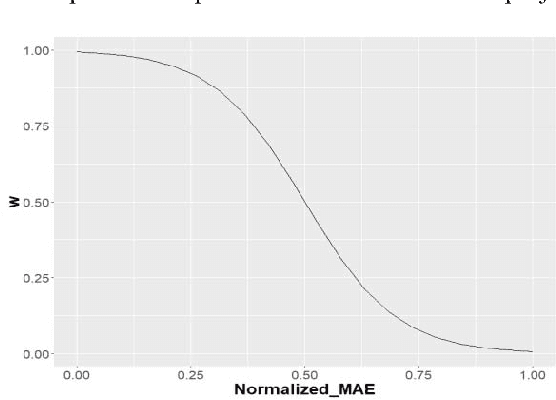
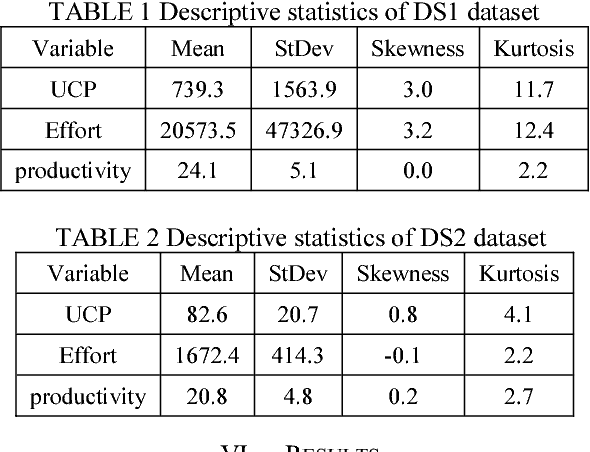
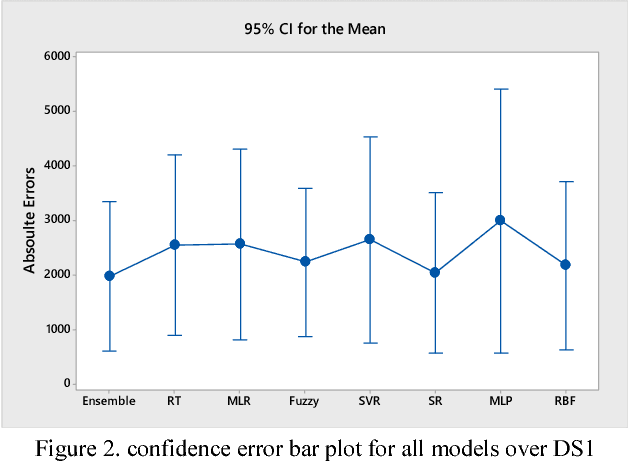
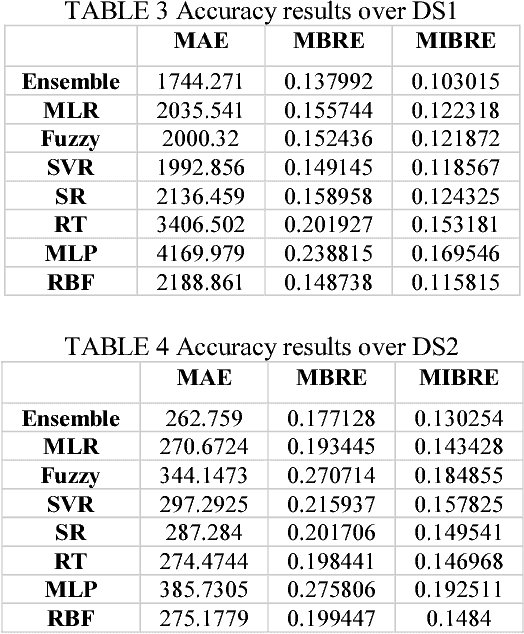
It is well recognized that the project productivity is a key driver in estimating software project effort from Use Case Point size metric at early software development stages. Although, there are few proposed models for predicting productivity, there is no consistent conclusion regarding which model is the superior. Therefore, instead of building a new productivity prediction model, this paper presents a new ensemble construction mechanism applied for software project productivity prediction. Ensemble is an effective technique when performance of base models is poor. We proposed a weighted mean method to aggregate predicted productivities based on average of errors produced by training model. The obtained results show that the using ensemble is a good alternative approach when accuracies of base models are not consistently accurate over different datasets, and when models behave diversely.
v-SVR Polynomial Kernel for Predicting the Defect Density in New Software Projects
Dec 15, 2018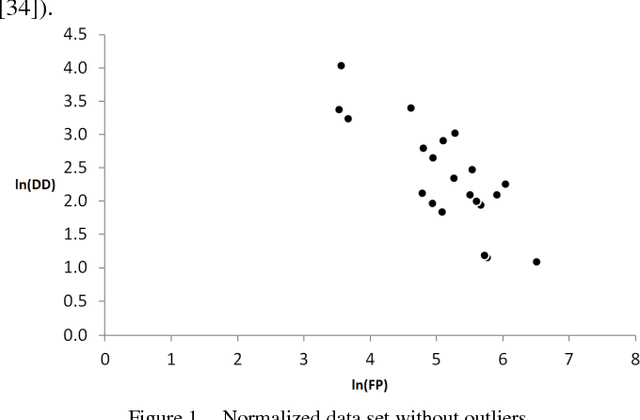
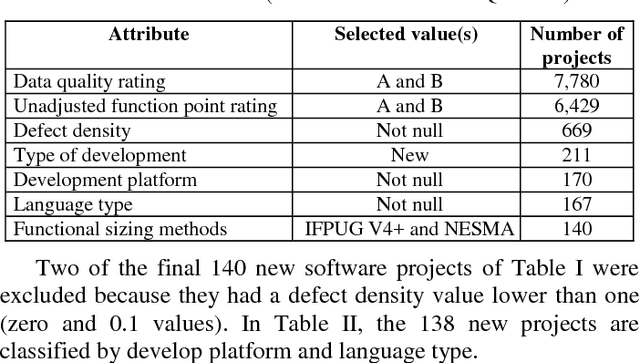
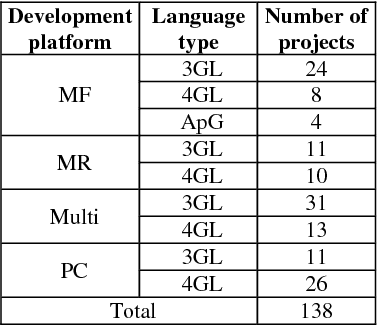
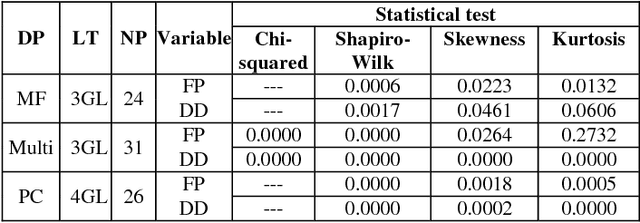
An important product measure to determine the effectiveness of software processes is the defect density (DD). In this study, we propose the application of support vector regression (SVR) to predict the DD of new software projects obtained from the International Software Benchmarking Standards Group (ISBSG) Release 2018 data set. Two types of SVR (e-SVR and v-SVR) were applied to train and test these projects. Each SVR used four types of kernels. The prediction accuracy of each SVR was compared to that of a statistical regression (i.e., a simple linear regression, SLR). Statistical significance test showed that v-SVR with polynomial kernel was better than that of SLR when new software projects were developed on mainframes and coded in programming languages of third generation
Machine Learning Classifications of Coronary Artery Disease
Nov 26, 2018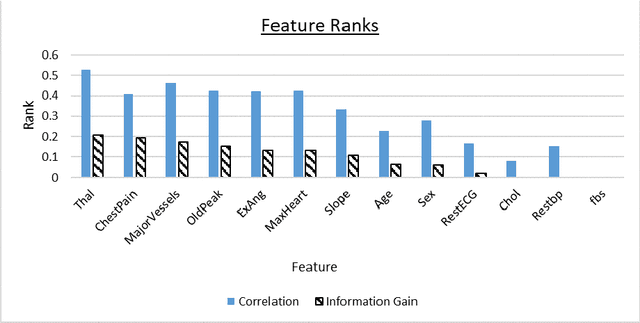

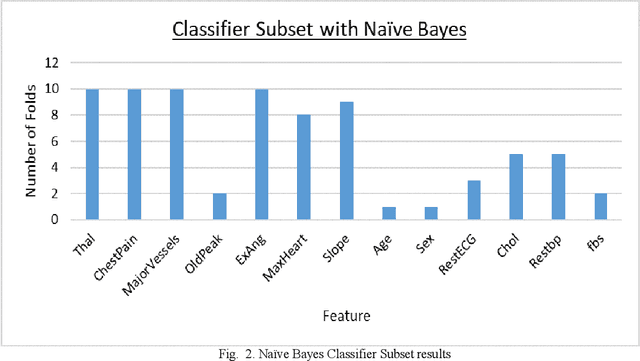
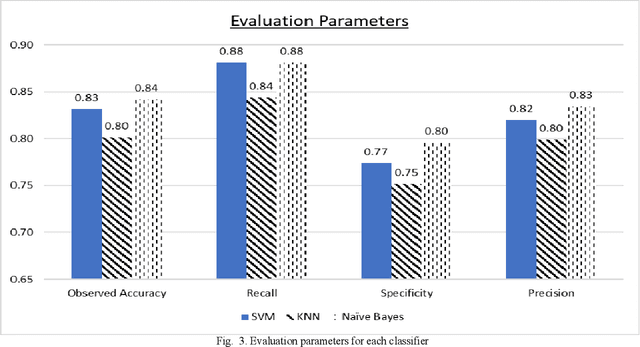
Coronary Artery Disease (CAD) is one of the leading causes of death worldwide, and so it is very important to correctly diagnose patients with the disease. For medical diagnosis, machine learning is a useful tool, however features and algorithms must be carefully selected to get accurate classification. To this effect, three feature selection methods have been used on 13 input features from the Cleveland dataset with 297 entries, and 7 were selected. The selected features were used to train three different classifiers, which are SVM, Na\"ive Bayes and KNN using 10-fold cross-validation. The resulting models evaluated using Accuracy, Recall, Specificity and Precision. It is found that the Na\"ive Bayes classifier performs the best on this dataset and features, outperforming or matching SVM and KNN in all the four evaluation parameters used and achieving an accuracy of 84%.
A Comparative Study for Predicting Heart Diseases Using Data Mining Classification Methods
Apr 10, 2017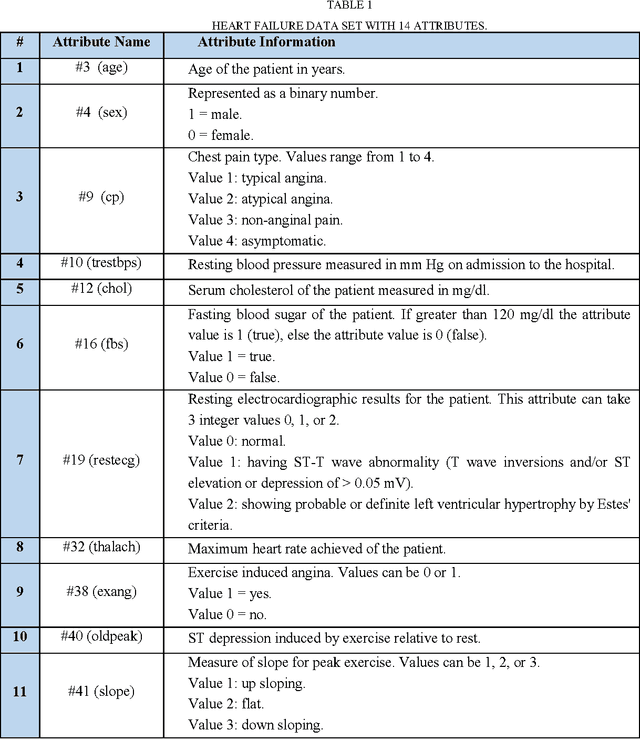
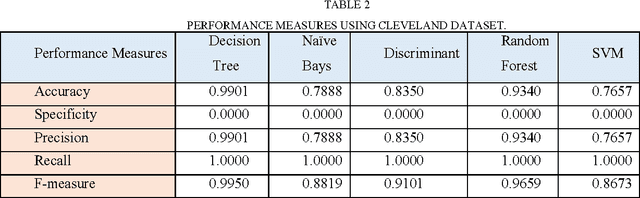
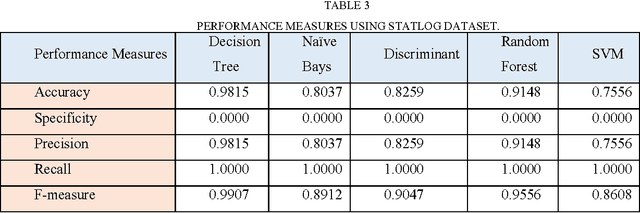
Improving the precision of heart diseases detection has been investigated by many researchers in the literature. Such improvement induced by the overwhelming health care expenditures and erroneous diagnosis. As a result, various methodologies have been proposed to analyze the disease factors aiming to decrease the physicians practice variation and reduce medical costs and errors. In this paper, our main motivation is to develop an effective intelligent medical decision support system based on data mining techniques. In this context, five data mining classifying algorithms, with large datasets, have been utilized to assess and analyze the risk factors statistically related to heart diseases in order to compare the performance of the implemented classifiers (e.g., Na\"ive Bayes, Decision Tree, Discriminant, Random Forest, and Support Vector Machine). To underscore the practical viability of our approach, the selected classifiers have been implemented using MATLAB tool with two datasets. Results of the conducted experiments showed that all classification algorithms are predictive and can give relatively correct answer. However, the decision tree outperforms other classifiers with an accuracy rate of 99.0% followed by Random forest. That is the case because both of them have relatively same mechanism but the Random forest can build ensemble of decision tree. Although ensemble learning has been proved to produce superior results, but in our case the decision tree has outperformed its ensemble version.
Fuzzy Model Tree For Early Effort Estimation
Mar 11, 2017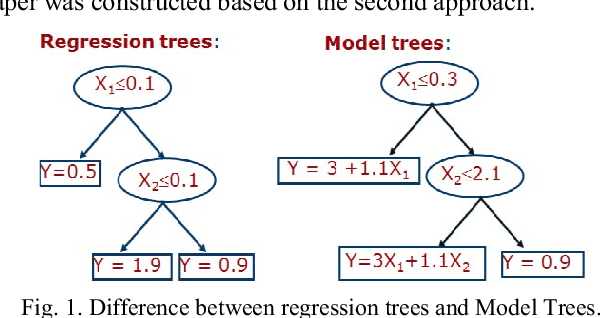
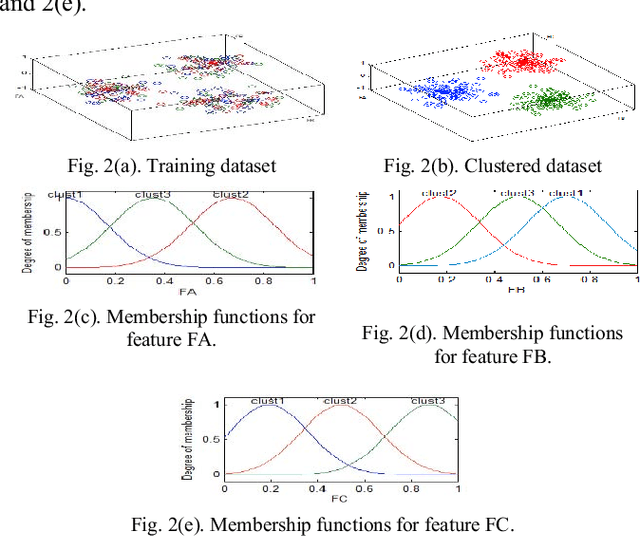
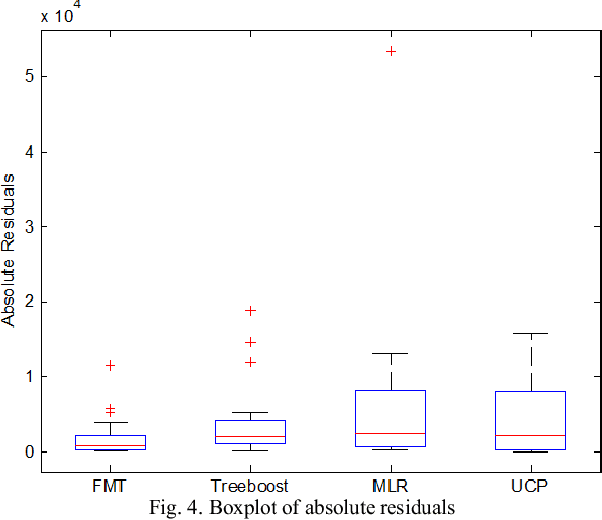
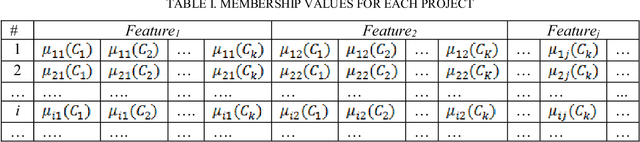
Use Case Points (UCP) is a well-known method to estimate the project size, based on Use Case diagram, at early phases of software development. Although the Use Case diagram is widely accepted as a de-facto model for analyzing object oriented software requirements over the world, UCP method did not take sufficient amount of attention because, as yet, there is no consensus on how to produce software effort from UCP. This paper aims to study the potential of using Fuzzy Model Tree to derive effort estimates based on UCP size measure using a dataset collected for that purpose. The proposed approach has been validated against Treeboost model, Multiple Linear Regression and classical effort estimation based on the UCP model. The obtained results are promising and show better performance than those obtained by classical UCP, Multiple Linear Regression and slightly better than those obtained by Tree boost model.
Learning best K analogies from data distribution for case-based software effort estimation
Mar 11, 2017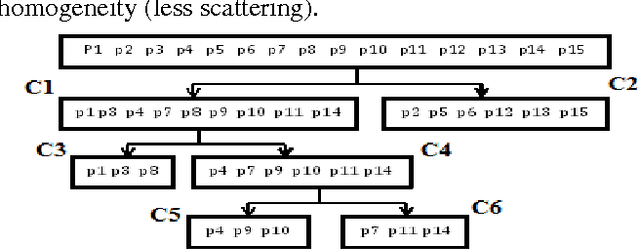
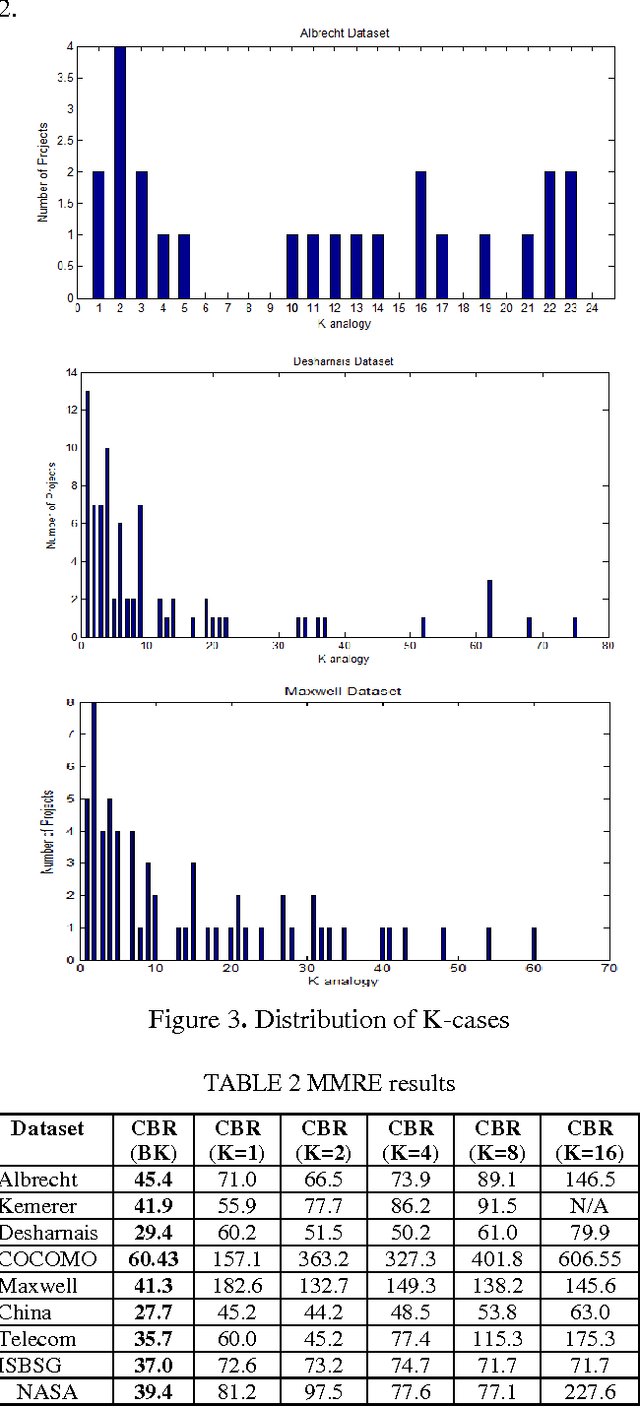
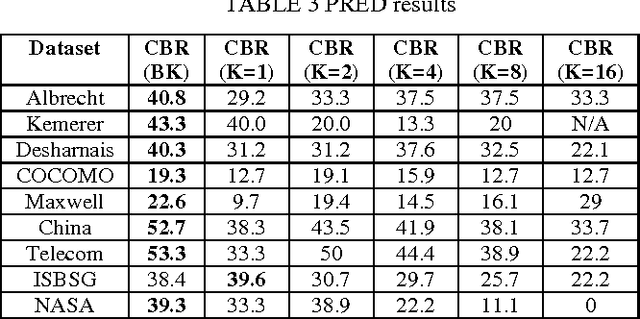
Case-Based Reasoning (CBR) has been widely used to generate good software effort estimates. The predictive performance of CBR is a dataset dependent and subject to extremely large space of configuration possibilities. Regardless of the type of adaptation technique, deciding on the optimal number of similar cases to be used before applying CBR is a key challenge. In this paper we propose a new technique based on Bisecting k-medoids clustering algorithm to better understanding the structure of a dataset and discovering the the optimal cases for each individual project by excluding irrelevant cases. Results obtained showed that understanding of the data characteristic prior prediction stage can help in automatically finding the best number of cases for each test project. Performance figures of the proposed estimation method are better than those of other regular K-based CBR methods.