 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble of Learning Project Productivity in Software Effort Based on Use Case Points
Dec 16, 2018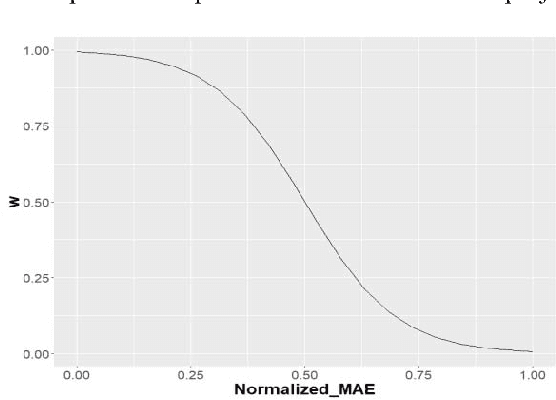
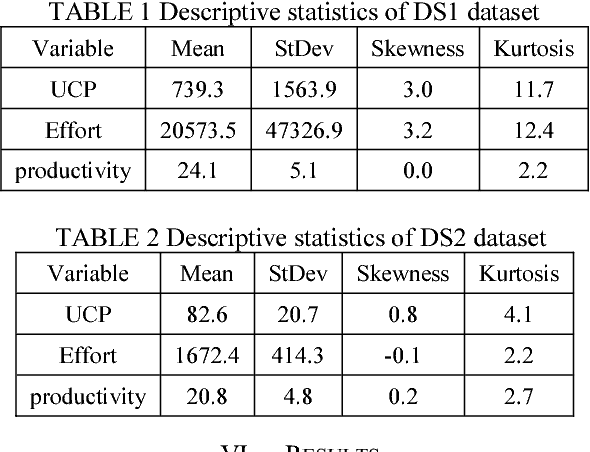
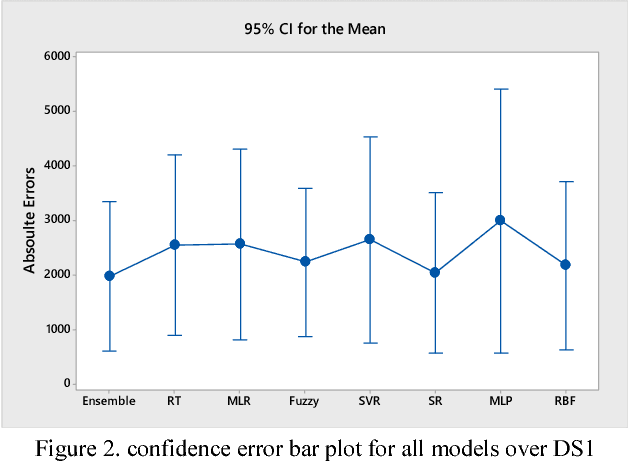
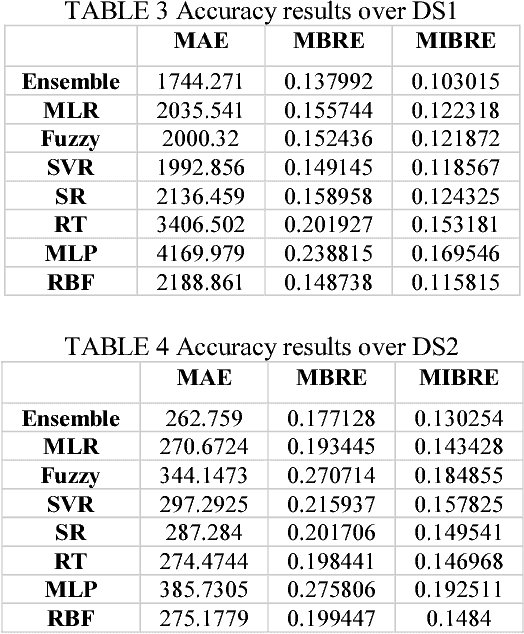
It is well recognized that the project productivity is a key driver in estimating software project effort from Use Case Point size metric at early software development stages. Although, there are few proposed models for predicting productivity, there is no consistent conclusion regarding which model is the superior. Therefore, instead of building a new productivity prediction model, this paper presents a new ensemble construction mechanism applied for software project productivity prediction. Ensemble is an effective technique when performance of base models is poor. We proposed a weighted mean method to aggregate predicted productivities based on average of errors produced by training model. The obtained results show that the using ensemble is a good alternative approach when accuracies of base models are not consistently accurate over different datasets, and when models behave diversely.
v-SVR Polynomial Kernel for Predicting the Defect Density in New Software Projects
Dec 15, 2018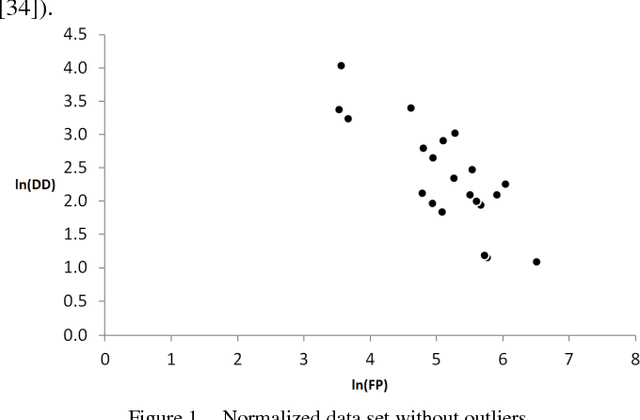
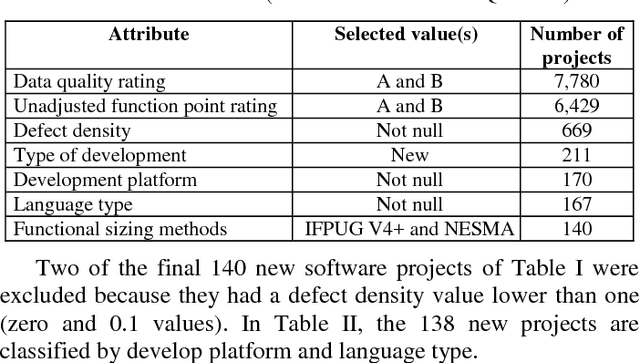
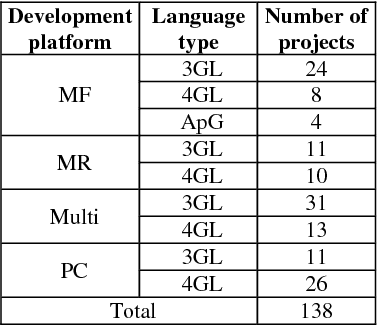
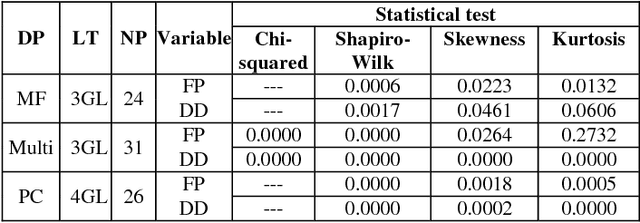
An important product measure to determine the effectiveness of software processes is the defect density (DD). In this study, we propose the application of support vector regression (SVR) to predict the DD of new software projects obtained from the International Software Benchmarking Standards Group (ISBSG) Release 2018 data set. Two types of SVR (e-SVR and v-SVR) were applied to train and test these projects. Each SVR used four types of kernels. The prediction accuracy of each SVR was compared to that of a statistical regression (i.e., a simple linear regression, SLR). Statistical significance test showed that v-SVR with polynomial kernel was better than that of SLR when new software projects were developed on mainframes and coded in programming languages of third generation