 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Classifications of Coronary Artery Disease
Paper and Code
Nov 26, 2018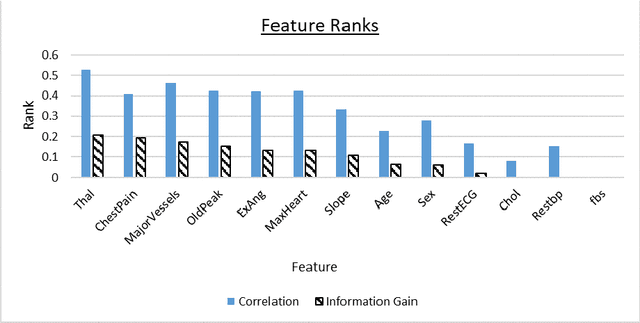

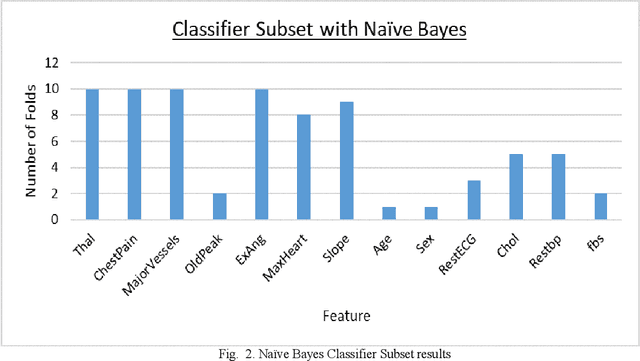
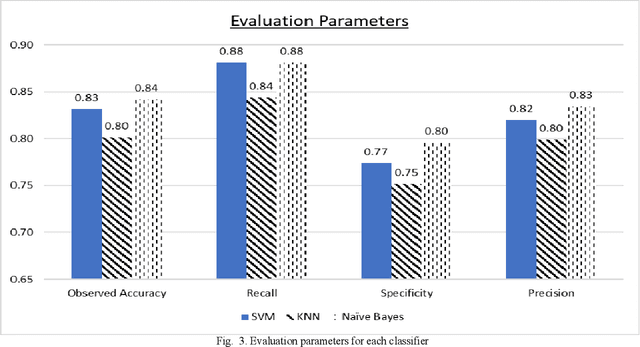
Coronary Artery Disease (CAD) is one of the leading causes of death worldwide, and so it is very important to correctly diagnose patients with the disease. For medical diagnosis, machine learning is a useful tool, however features and algorithms must be carefully selected to get accurate classification. To this effect, three feature selection methods have been used on 13 input features from the Cleveland dataset with 297 entries, and 7 were selected. The selected features were used to train three different classifiers, which are SVM, Na\"ive Bayes and KNN using 10-fold cross-validation. The resulting models evaluated using Accuracy, Recall, Specificity and Precision. It is found that the Na\"ive Bayes classifier performs the best on this dataset and features, outperforming or matching SVM and KNN in all the four evaluation parameters used and achieving an accuracy of 84%.