 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning best K analogies from data distribution for case-based software effort estimation
Paper and Code
Mar 11, 2017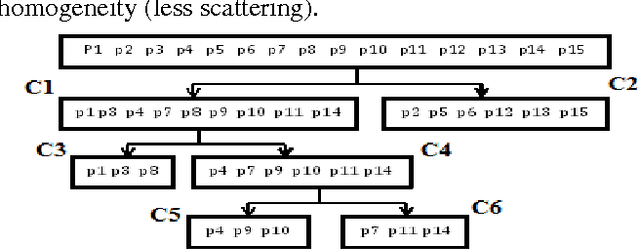
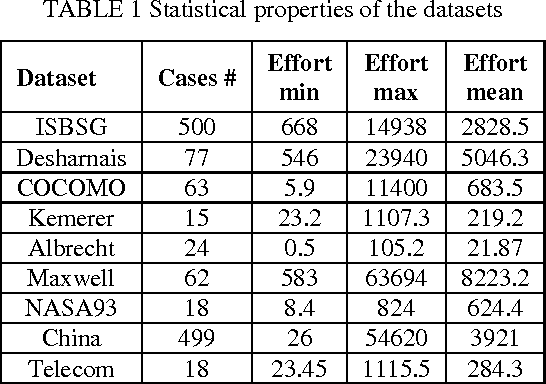
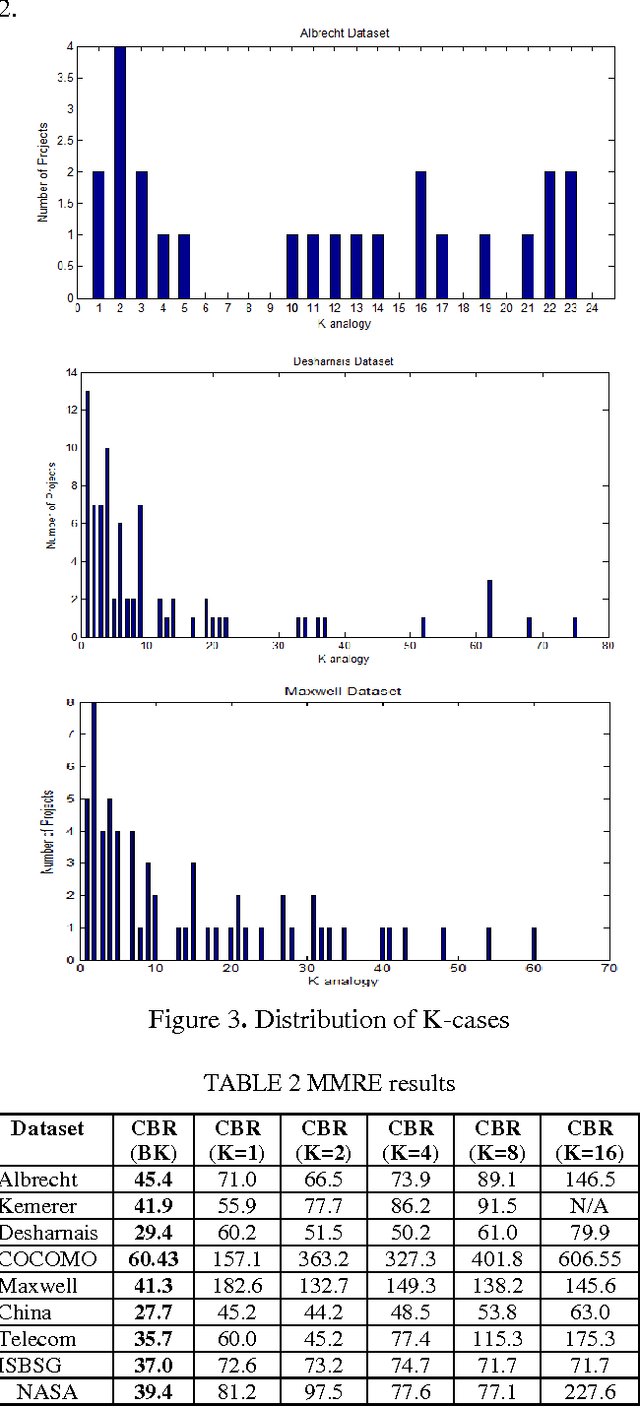
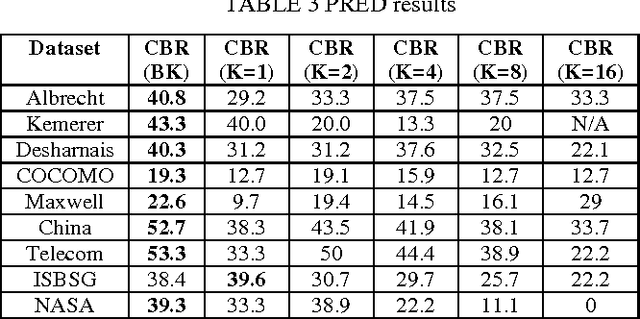
Case-Based Reasoning (CBR) has been widely used to generate good software effort estimates. The predictive performance of CBR is a dataset dependent and subject to extremely large space of configuration possibilities. Regardless of the type of adaptation technique, deciding on the optimal number of similar cases to be used before applying CBR is a key challenge. In this paper we propose a new technique based on Bisecting k-medoids clustering algorithm to better understanding the structure of a dataset and discovering the the optimal cases for each individual project by excluding irrelevant cases. Results obtained showed that understanding of the data characteristic prior prediction stage can help in automatically finding the best number of cases for each test project. Performance figures of the proposed estimation method are better than those of other regular K-based CBR methods.