 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe exploitation of Multiple Feature Extraction Techniques for Speaker Identification in Emotional States under Disguised Voices
Dec 15, 2021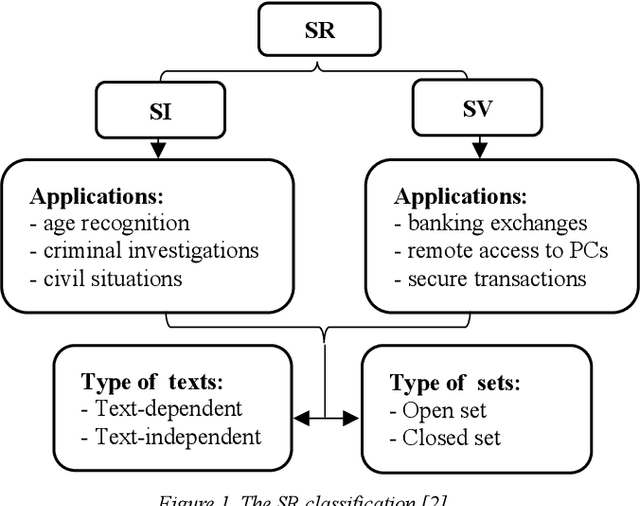

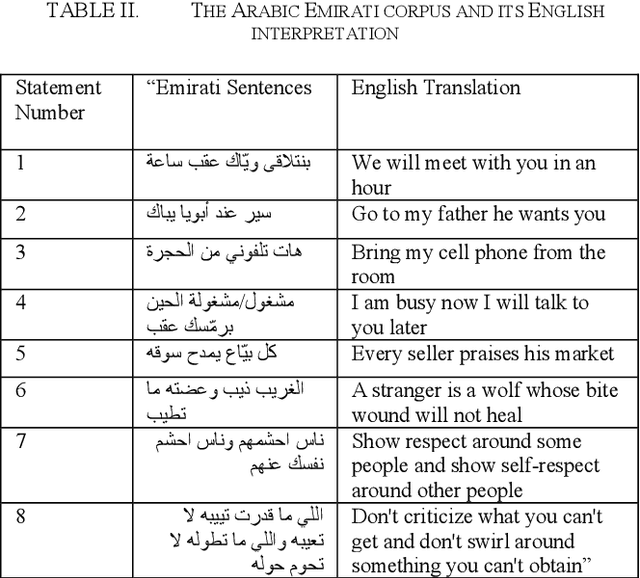
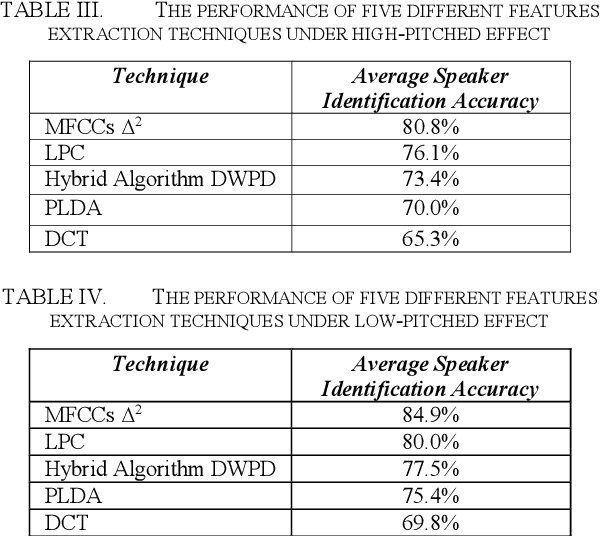
Due to improvements in artificial intelligence, speaker identification (SI) technologies have brought a great direction and are now widely used in a variety of sectors. One of the most important components of SI is feature extraction, which has a substantial impact on the SI process and performance. As a result, numerous feature extraction strategies are thoroughly investigated, contrasted, and analyzed. This article exploits five distinct feature extraction methods for speaker identification in disguised voices under emotional environments. To evaluate this work significantly, three effects are used: high-pitched, low-pitched, and Electronic Voice Conversion (EVC). Experimental results reported that the concatenated Mel-Frequency Cepstral Coefficients (MFCCs), MFCCs-delta, and MFCCs-delta-delta is the best feature extraction method.