 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical evaluation of shallow and deep learning classifiers for Arabic sentiment analysis
Paper and Code
Dec 01, 2021
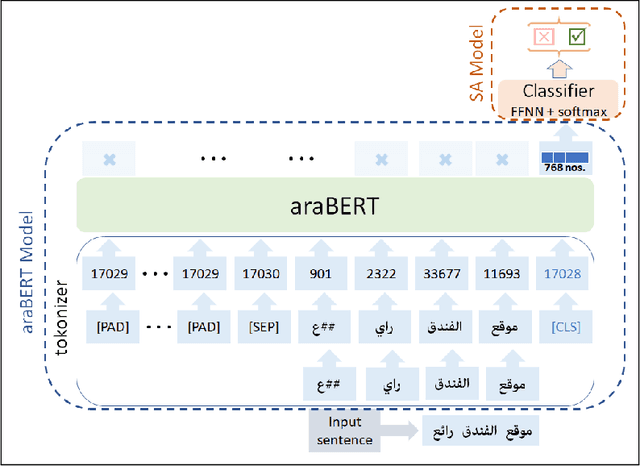


This work presents a detailed comparison of the performance of deep learning models such as convolutional neural networks (CNN), long short-term memory (LSTM), gated recurrent units (GRU), their hybrids, and a selection of shallow learning classifiers for sentiment analysis of Arabic reviews. Additionally, the comparison includes state-of-the-art models such as the transformer architecture and the araBERT pre-trained model. The datasets used in this study are multi-dialect Arabic hotel and book review datasets, which are some of the largest publicly available datasets for Arabic reviews. Results showed deep learning outperforming shallow learning for binary and multi-label classification, in contrast with the results of similar work reported in the literature. This discrepancy in outcome was caused by dataset size as we found it to be proportional to the performance of deep learning models. The performance of deep and shallow learning techniques was analyzed in terms of accuracy and F1 score. The best performing shallow learning technique was Random Forest followed by Decision Tree, and AdaBoost. The deep learning models performed similarly using a default embedding layer, while the transformer model performed best when augmented with araBERT.