 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling of uncertainty in medical data using machine learning and probability theory techniques: A review of 30 years
Aug 23, 2020
Understanding data and reaching valid conclusions are of paramount importance in the present era of big data. Machine learning and probability theory methods have widespread application for this purpose in different fields. One critically important yet less explored aspect is how data and model uncertainties are captured and analyzed. Proper quantification of uncertainty provides valuable information for optimal decision making. This paper reviewed related studies conducted in the last 30 years (from 1991 to 2020) in handling uncertainties in medical data using probability theory and machine learning techniques. Medical data is more prone to uncertainty due to the presence of noise in the data. So, it is very important to have clean medical data without any noise to get accurate diagnosis. The sources of noise in the medical data need to be known to address this issue. Based on the medical data obtained by the physician, diagnosis of disease, and treatment plan are prescribed. Hence, the uncertainty is growing in healthcare and there is limited knowledge to address these problems. We have little knowledge about the optimal treatment methods as there are many sources of uncertainty in medical science. Our findings indicate that there are few challenges to be addressed in handling the uncertainty in medical raw data and new models. In this work, we have summarized various methods employed to overcome this problem. Nowadays, application of novel deep learning techniques to deal such uncertainties have significantly increased.
Discovering topic structures of a temporally evolving document corpus
Dec 25, 2015

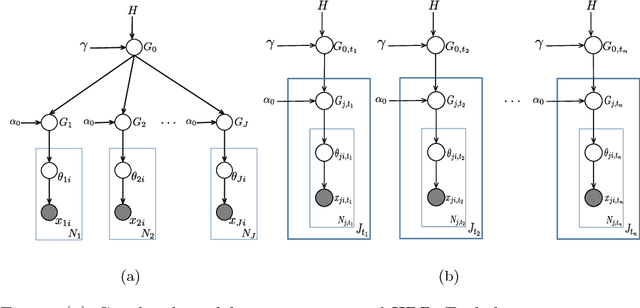

In this paper we describe a novel framework for the discovery of the topical content of a data corpus, and the tracking of its complex structural changes across the temporal dimension. In contrast to previous work our model does not impose a prior on the rate at which documents are added to the corpus nor does it adopt the Markovian assumption which overly restricts the type of changes that the model can capture. Our key technical contribution is a framework based on (i) discretization of time into epochs, (ii) epoch-wise topic discovery using a hierarchical Dirichlet process-based model, and (iii) a temporal similarity graph which allows for the modelling of complex topic changes: emergence and disappearance, evolution, splitting, and merging. The power of the proposed framework is demonstrated on two medical literature corpora concerned with the autism spectrum disorder (ASD) and the metabolic syndrome (MetS) -- both increasingly important research subjects with significant social and healthcare consequences. In addition to the collected ASD and metabolic syndrome literature corpora which we made freely available, our contribution also includes an extensive empirical analysis of the proposed framework. We describe a detailed and careful examination of the effects that our algorithms's free parameters have on its output, and discuss the significance of the findings both in the context of the practical application of our algorithm as well as in the context of the existing body of work on temporal topic analysis. Our quantitative analysis is followed by several qualitative case studies highly relevant to the current research on ASD and MetS, on which our algorithm is shown to capture well the actual developments in these fields.
Hierarchical Dirichlet process for tracking complex topical structure evolution and its application to autism research literature
Feb 08, 2015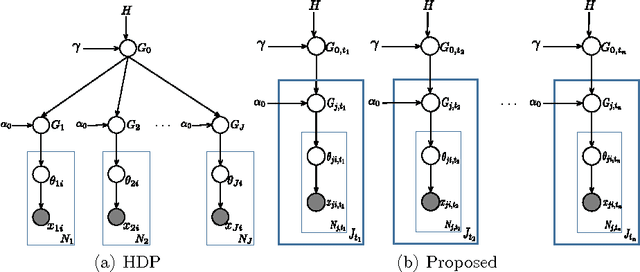
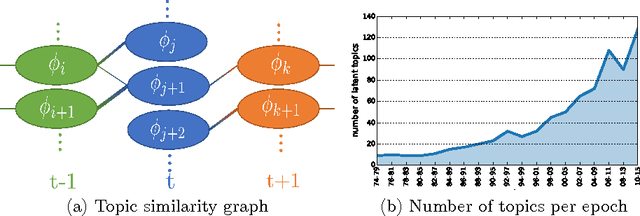
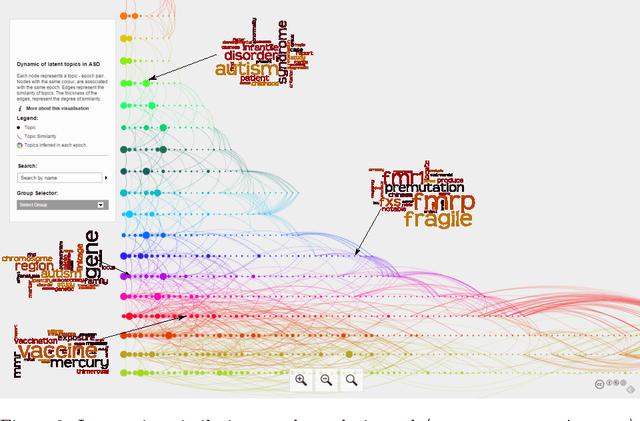
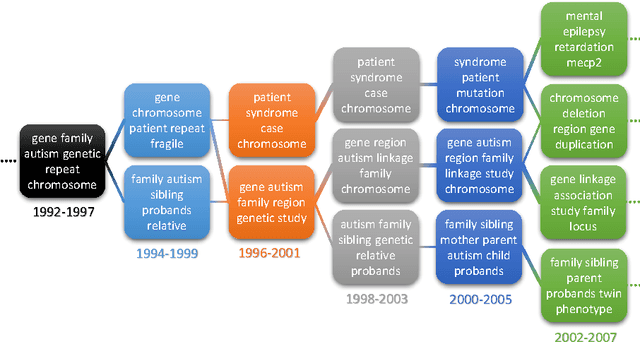
In this paper we describe a novel framework for the discovery of the topical content of a data corpus, and the tracking of its complex structural changes across the temporal dimension. In contrast to previous work our model does not impose a prior on the rate at which documents are added to the corpus nor does it adopt the Markovian assumption which overly restricts the type of changes that the model can capture. Our key technical contribution is a framework based on (i) discretization of time into epochs, (ii) epoch-wise topic discovery using a hierarchical Dirichlet process-based model, and (iii) a temporal similarity graph which allows for the modelling of complex topic changes: emergence and disappearance, evolution, and splitting and merging. The power of the proposed framework is demonstrated on the medical literature corpus concerned with the autism spectrum disorder (ASD) - an increasingly important research subject of significant social and healthcare importance. In addition to the collected ASD literature corpus which we will make freely available, our contributions also include two free online tools we built as aids to ASD researchers. These can be used for semantically meaningful navigation and searching, as well as knowledge discovery from this large and rapidly growing corpus of literature.