 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable sigma Gaussian processes: An expectation propagation perspective
Paper and Code
Oct 07, 2009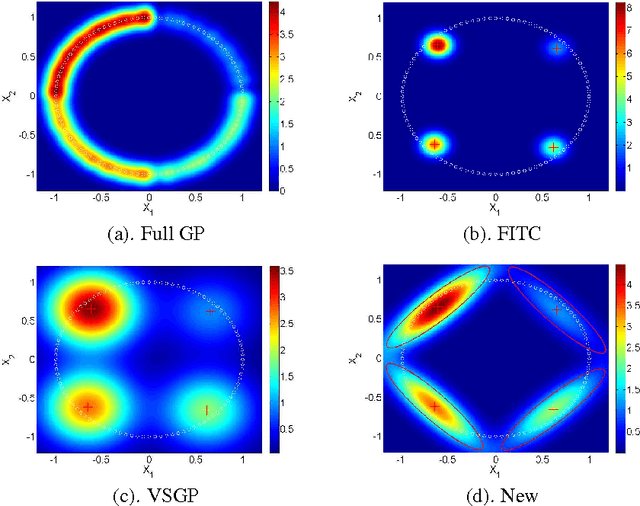
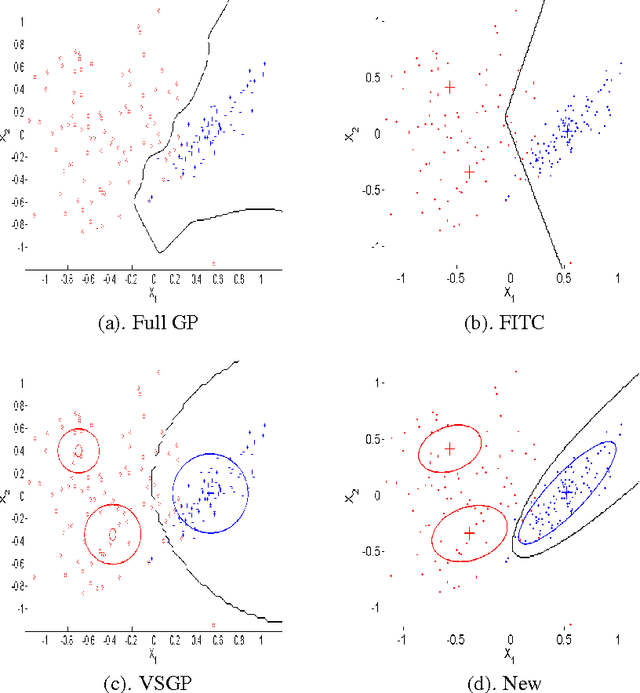
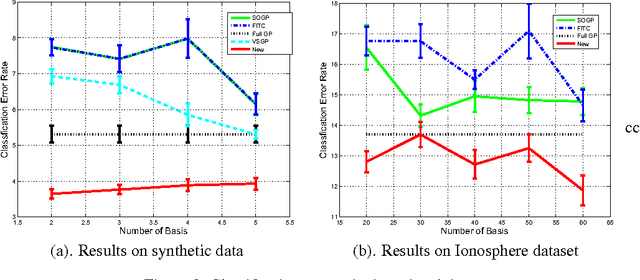
Gaussian processes (GPs) provide a probabilistic nonparametric representation of functions in regression, classification, and other problems. Unfortunately, exact learning with GPs is intractable for large datasets. A variety of approximate GP methods have been proposed that essentially map the large dataset into a small set of basis points. The most advanced of these, the variable-sigma GP (VSGP) (Walder et al., 2008), allows each basis point to have its own length scale. However, VSGP was only derived for regression. We describe how VSGP can be applied to classification and other problems, by deriving it as an expectation propagation algorithm. In this view, sparse GP approximations correspond to a KL-projection of the true posterior onto a compact exponential family of GPs. VSGP constitutes one such family, and we show how to enlarge this family to get additional accuracy. In particular, we show that endowing each basis point with its own full covariance matrix provides a significant increase in approximation power.