 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELD: Mel-Spectrogram-Based Speech Language Modeling with Discrete Latent Variables
May 28, 2026Recent speech language models rely on encoders that are optimized separately from autoregressive models. Since these encoders are unaware of the downstream objectives, the extracted representations may not be optimal for downstream tasks. To address this limitation, we introduce a discrete latent variable model on mel spectrograms that jointly optimizes the encoder and the speech language model. Joint optimization not only brings improvements over codec-based and other mel-spectrogram-based baselines on zero-shot Text-to-Speech (TTS) and Speech-to-Text (STT) tasks, but also effectively alleviates common issues in autoregressive mel-spectrogram modeling, such as prolonged silence generation and word omissions.
TextSeal: A Localized LLM Watermark for Provenance & Distillation Protection
May 12, 2026We introduce TextSeal, a state-of-the-art watermark for large language models. Building on Gumbel-max sampling, TextSeal introduces dual-key generation to restore output diversity, along with entropy-weighted scoring and multi-region localization for improved detection. It supports serving optimizations such as speculative decoding and multi-token prediction, and does not add any inference overhead. TextSeal strictly dominates baselines like SynthID-text in detection strength and is robust to dilution, maintaining confident localized detection even in heavily mixed human/AI documents. The scheme is theoretically distortion-free, and evaluation across reasoning benchmarks confirms that it preserves downstream performance; while a multilingual human evaluation (6000 A/B comparisons, 5 languages) shows no perceptible quality difference. Beyond its use for provenance detection, TextSeal is also ``radioactive'': its watermark signal transfers through model distillation, enabling detection of unauthorized use.
Omnilingual MT: Machine Translation for 1,600 Languages
Mar 17, 2026High-quality machine translation (MT) can scale to hundreds of languages, setting a high bar for multilingual systems. However, compared to the world's 7,000 languages, current systems still offer only limited coverage: about 200 languages on the target side, and maybe a few hundreds more on the source side, supported due to cross-lingual transfer. And even these numbers have been hard to evaluate due to the lack of reliable benchmarks and metrics. We present Omnilingual Machine Translation (OMT), the first MT system supporting more than 1,600 languages. This scale is enabled by a comprehensive data strategy that integrates large public multilingual corpora with newly created datasets, including manually curated MeDLEY bitext. We explore two ways of specializing a Large Language model (LLM) for machine translation: as a decoder-only model (OMT-LLaMA) or as a module in an encoder-decoder architecture (OMT-NLLB). Notably, all our 1B to 8B parameter models match or exceed the MT performance of a 70B LLM baseline, revealing a clear specialization advantage and enabling strong translation quality in low-compute settings. Moreover, our evaluation of English-to-1,600 translations further shows that while baseline models can interpret undersupported languages, they frequently fail to generate them with meaningful fidelity; OMT-LLaMA models substantially expand the set of languages for which coherent generation is feasible. Additionally, OMT models improve in cross-lingual transfer, being close to solving the "understanding" part of the puzzle in MT for the 1,600 evaluated. Our leaderboard and main human-created evaluation datasets (BOUQuET and Met-BOUQuET) are dynamically evolving towards Omnilinguality and freely available.
Omnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026Cross-lingual sentence encoders typically cover only a few hundred languages and often trade downstream quality for stronger alignment, limiting their adoption. We introduce OmniSONAR, a new family of omnilingual, cross-lingual and cross-modal sentence embedding models that natively embed text, speech, code, and mathematical expressions in a single semantic space, while delivering state-of-the-art downstream performance at the scale of thousands of languages, from high-resource to extremely low-resource varieties. To reach this scale without representation collapse, we use progressive training. We first learn a strong foundational space for 200 languages with an LLM-initialized encoder-decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Building on this foundation, we expand to several thousands language varieties via a two-stage teacher-student encoder distillation framework. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR halves cross-lingual similarity search error on the 200-language FLORES dataset and reduces error by a factor of 15 on the 1,560-language BIBLE benchmark. It also enables strong translation, outperforming NLLB-3B on multilingual benchmarks and exceeding prior models (including much larger LLMs) by 15 chrF++ points on 1,560 languages into English BIBLE translation. OmniSONAR also performs strongly on MTEB and XLCoST. For speech, OmniSONAR achieves a 43% lower similarity-search error and reaches 97% of SeamlessM4T speech-to-text quality, despite being zero-shot for translation (trained only on ASR data). Finally, by training an encoder-decoder LM, Spectrum, exclusively on English text processing OmniSONAR embedding sequences, we unlock high-performance transfer to thousands of languages and speech for complex downstream tasks.
Learning to Watermark in the Latent Space of Generative Models
Jan 22, 2026Existing approaches for watermarking AI-generated images often rely on post-hoc methods applied in pixel space, introducing computational overhead and potential visual artifacts. In this work, we explore latent space watermarking and introduce DistSeal, a unified approach for latent watermarking that works across both diffusion and autoregressive models. Our approach works by training post-hoc watermarking models in the latent space of generative models. We demonstrate that these latent watermarkers can be effectively distilled either into the generative model itself or into the latent decoder, enabling in-model watermarking. The resulting latent watermarks achieve competitive robustness while offering similar imperceptibility and up to 20x speedup compared to pixel-space baselines. Our experiments further reveal that distilling latent watermarkers outperforms distilling pixel-space ones, providing a solution that is both more efficient and more robust.
Pixel Seal: Adversarial-only training for invisible image and video watermarking
Dec 18, 2025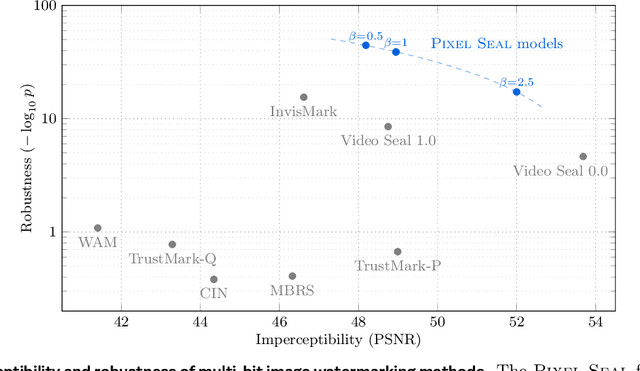
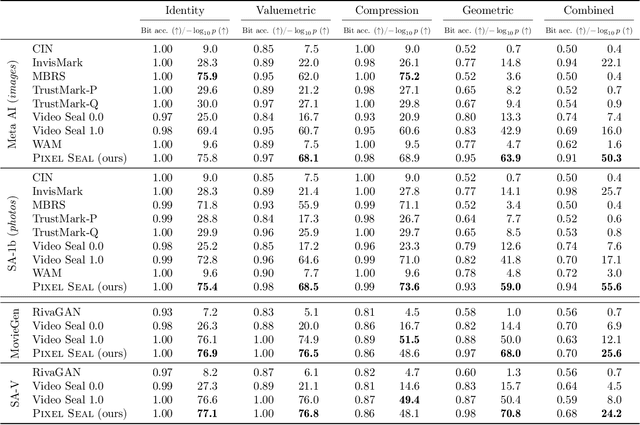
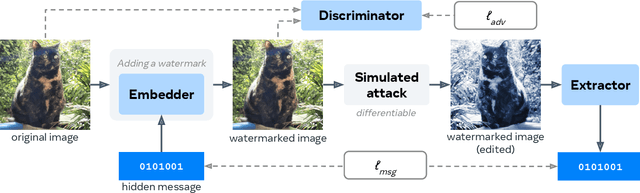
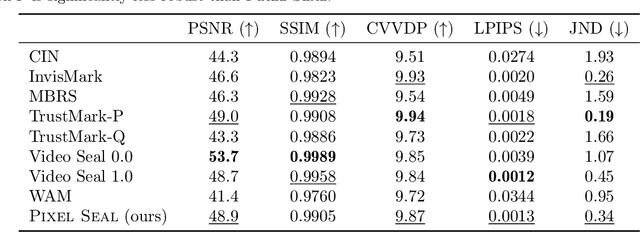
Invisible watermarking is essential for tracing the provenance of digital content. However, training state-of-the-art models remains notoriously difficult, with current approaches often struggling to balance robustness against true imperceptibility. This work introduces Pixel Seal, which sets a new state-of-the-art for image and video watermarking. We first identify three fundamental issues of existing methods: (i) the reliance on proxy perceptual losses such as MSE and LPIPS that fail to mimic human perception and result in visible watermark artifacts; (ii) the optimization instability caused by conflicting objectives, which necessitates exhaustive hyperparameter tuning; and (iii) reduced robustness and imperceptibility of watermarks when scaling models to high-resolution images and videos. To overcome these issues, we first propose an adversarial-only training paradigm that eliminates unreliable pixel-wise imperceptibility losses. Second, we introduce a three-stage training schedule that stabilizes convergence by decoupling robustness and imperceptibility. Third, we address the resolution gap via high-resolution adaptation, employing JND-based attenuation and training-time inference simulation to eliminate upscaling artifacts. We thoroughly evaluate the robustness and imperceptibility of Pixel Seal on different image types and across a wide range of transformations, and show clear improvements over the state-of-the-art. We finally demonstrate that the model efficiently adapts to video via temporal watermark pooling, positioning Pixel Seal as a practical and scalable solution for reliable provenance in real-world image and video settings.
How Good is Post-Hoc Watermarking With Language Model Rephrasing?
Dec 18, 2025Generation-time text watermarking embeds statistical signals into text for traceability of AI-generated content. We explore *post-hoc watermarking* where an LLM rewrites existing text while applying generation-time watermarking, to protect copyrighted documents, or detect their use in training or RAG via watermark radioactivity. Unlike generation-time approaches, which is constrained by how LLMs are served, this setting offers additional degrees of freedom for both generation and detection. We investigate how allocating compute (through larger rephrasing models, beam search, multi-candidate generation, or entropy filtering at detection) affects the quality-detectability trade-off. Our strategies achieve strong detectability and semantic fidelity on open-ended text such as books. Among our findings, the simple Gumbel-max scheme surprisingly outperforms more recent alternatives under nucleus sampling, and most methods benefit significantly from beam search. However, most approaches struggle when watermarking verifiable text such as code, where we counterintuitively find that smaller models outperform larger ones. This study reveals both the potential and limitations of post-hoc watermarking, laying groundwork for practical applications and future research.
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
Transferable Black-Box One-Shot Forging of Watermarks via Image Preference Models
Oct 23, 2025



Recent years have seen a surge in interest in digital content watermarking techniques, driven by the proliferation of generative models and increased legal pressure. With an ever-growing percentage of AI-generated content available online, watermarking plays an increasingly important role in ensuring content authenticity and attribution at scale. There have been many works assessing the robustness of watermarking to removal attacks, yet, watermark forging, the scenario when a watermark is stolen from genuine content and applied to malicious content, remains underexplored. In this work, we investigate watermark forging in the context of widely used post-hoc image watermarking. Our contributions are as follows. First, we introduce a preference model to assess whether an image is watermarked. The model is trained using a ranking loss on purely procedurally generated images without any need for real watermarks. Second, we demonstrate the model's capability to remove and forge watermarks by optimizing the input image through backpropagation. This technique requires only a single watermarked image and works without knowledge of the watermarking model, making our attack much simpler and more practical than attacks introduced in related work. Third, we evaluate our proposed method on a variety of post-hoc image watermarking models, demonstrating that our approach can effectively forge watermarks, questioning the security of current watermarking approaches. Our code and further resources are publicly available.
Geometric Image Synchronization with Deep Watermarking
Sep 18, 2025



Synchronization is the task of estimating and inverting geometric transformations (e.g., crop, rotation) applied to an image. This work introduces SyncSeal, a bespoke watermarking method for robust image synchronization, which can be applied on top of existing watermarking methods to enhance their robustness against geometric transformations. It relies on an embedder network that imperceptibly alters images and an extractor network that predicts the geometric transformation to which the image was subjected. Both networks are end-to-end trained to minimize the error between the predicted and ground-truth parameters of the transformation, combined with a discriminator to maintain high perceptual quality. We experimentally validate our method on a wide variety of geometric and valuemetric transformations, demonstrating its effectiveness in accurately synchronizing images. We further show that our synchronization can effectively upgrade existing watermarking methods to withstand geometric transformations to which they were previously vulnerable.